![image]()
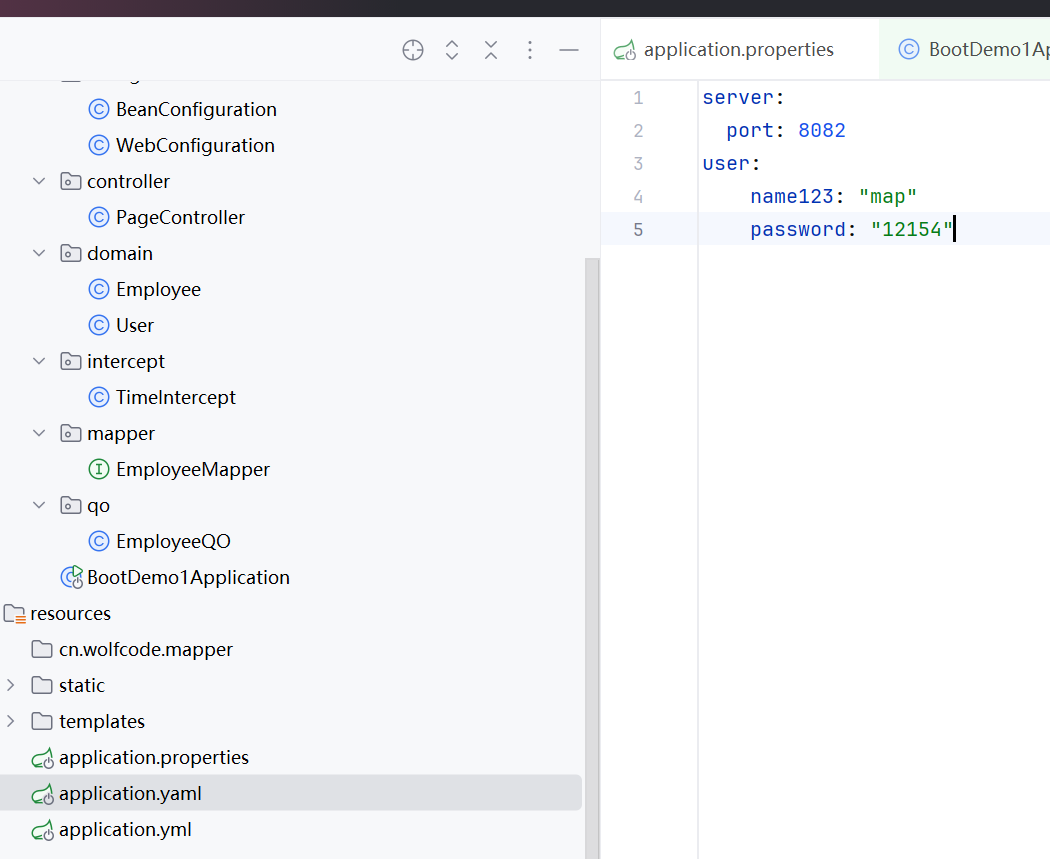
除了.properties配置文件之外,.yaml和.yml后缀也可以作为配置文件,在.yaml中的配置写法可以便捷一些,写成如图所示的写法,把相同前缀的归在一类里,这样就不需要反复引用了
在访问时,如果同同时出现这三个配置文件,优先级是.properties>.yml>.yaml这点可以在不同的配置文件配置不同的端口号然后查看访问结果
构建查询对象 (EmployeeQO):创建了一个 EmployeeQO(Query Object,查询条件对象。
然后开启分页 (PageHelper.startPage):
这里使用了 PageHelper.startPage(1, 3)。
关键点:PageHelper 通常是 PageHelper 插件(非 MyBatis-Plus 自带,或旧版用法)的静态方法。它利用 ThreadLocal 绑定了当前线程的分页参数(第 1 页,每页 3 条)。他相当于sql中的limit
!!!!注意:这行代码必须在查询数据库之前调用。
执行查询:调用 employeeMapper.QueryByCondition(qo)。此时 MyBatis 的拦截器会拦截该查询,并自动拼接上 LIMIT 语句。
封装分页信息 (PageInfo):
将查询结果 employeeList 传入 PageInfo 构造函数。
PageInfo 的构造函数会自动分析传入的列表。如果列表是 PageHelper 生成的 Page 对象,它会直接读取其中的总记录数和分页参数;如果是普通列表,它则会将列表大小视为总记录数。基于这些数据,PageInfo 会自动计算出总页数、是否有下一页等所有辅助属性,从而避免手动计算的繁琐与错误。
获取结果:employeePageInfo.getList() 获取当前页的数据列表。
![image]()
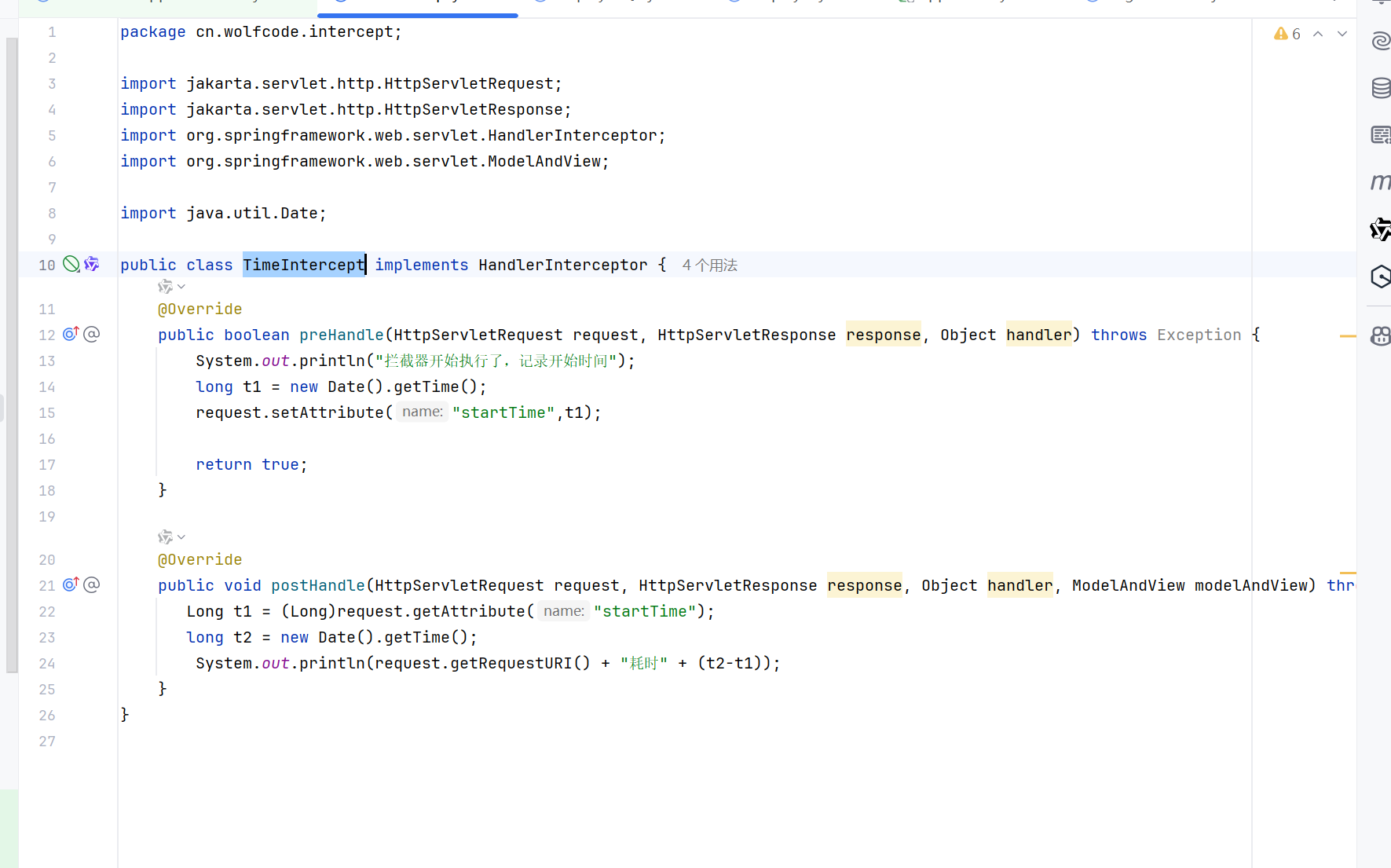
首先是preHandle (预处理):在控制器方法执行前被调用。记录开始时间:long t1 = new Date().getTime()。存入 Request:request.setAttribute("startTime", t1)。这是为了将开始时间传递给后续的 postHandle 方法使用(因为拦截器是单例的,不能用成员变量存 t1,否则多线程下会混乱)。返回 true:表示放行,继续执行后续的控制器逻辑;若返回 false,则请求终止。
然后是postHandle (后处理):在控制器方法执行后、视图渲染前被调用。获取开始时间:从 request 中取出 startTime。计算结束时间:long t2 = new Date().getTime()。打印耗时:输出 request.getRequestURI()(请求路径)以及 t2 - t1(消耗的毫秒数)。
设计模式与原理:AOP 思想:这是面向切面编程的一种简单实现,将“统计耗时”这个非业务核心逻辑(Cross-cutting Concerns)从业务代码中剥离出来。
最后分享几道面试题
13 final 关键字修饰这三个地方:变量、方法、类,会有什么作用?
对于一个 final 变量,如果是基本数据类型的变量,则其数值一旦在初始化之后;便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。当用 final 修饰一个类时,表明这个类不能被继承。final 类中的所有成员方法都会被隐式地指定为 final 方法。使用 final 方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的 Java 实现版本中,会将 final 方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升
14 Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
15 获取用键盘输入常用的两种方法
方法 1:通过 Scanner
Scanner input = new Scanner(System.in);
String s = input.nextLine();
input.close();
方法 2:通过 BufferedReader
BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
String s = input.readLine();
16 既然有了字节流,为什么还要有字符流?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
17 描述深拷贝和浅拷贝
浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。