
Numpy学习指南
基础部分
入门结合参考:https://chuna2.787528.xyz/yigehulu/p/18034817
numpy简介
核心概念 - 轴(Axis)
轴(Axis)是数组的维度索引,从0开始编号
二维数组的轴
-
axis=0垂直方向(沿行方向,操作跨行) -
axis=1水平方向(沿列方向,操作跨列)
三维数组的轴
axis=0深度方向(跨层操作)axis=1垂直方向(跨行)axis=2水平方向(跨列)
numpy数组
创建数组
np.array()基础创建
-
创建一维数组
![]()
-
创建二维数组
![]()
-
指定数据类型创建数组
![]()



np.random随机数创建数组
np.random.randint创建整数数组
![]()


-
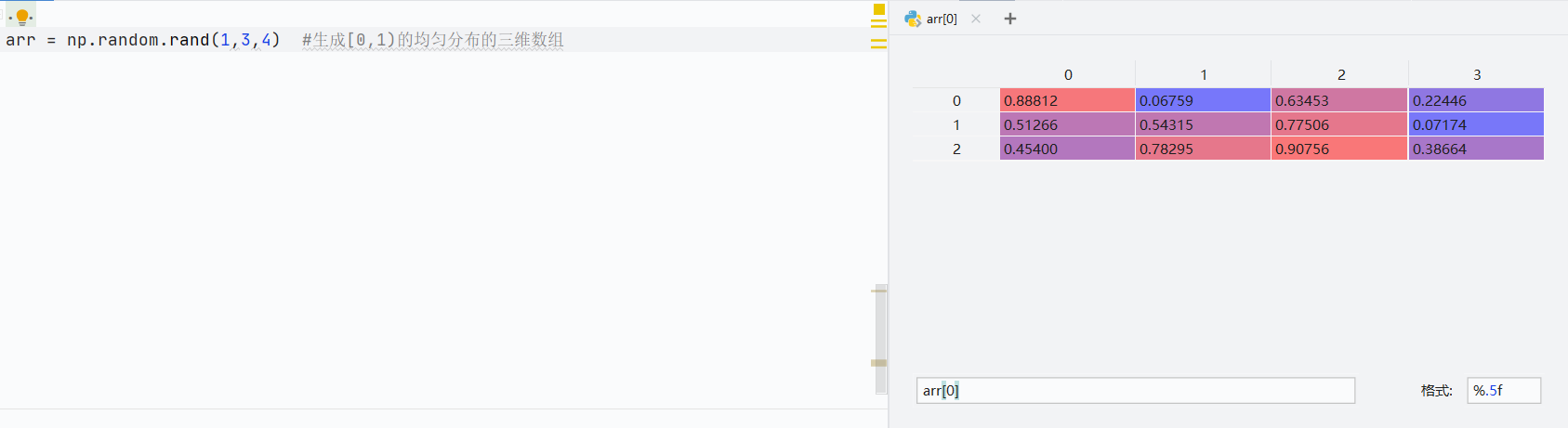
np.random.rand()创建[0,1)均态分布数组
![]()
-
np.random.randn()标准正态分布
![]()
-
np.random.random()通用均匀分布
![]()
-
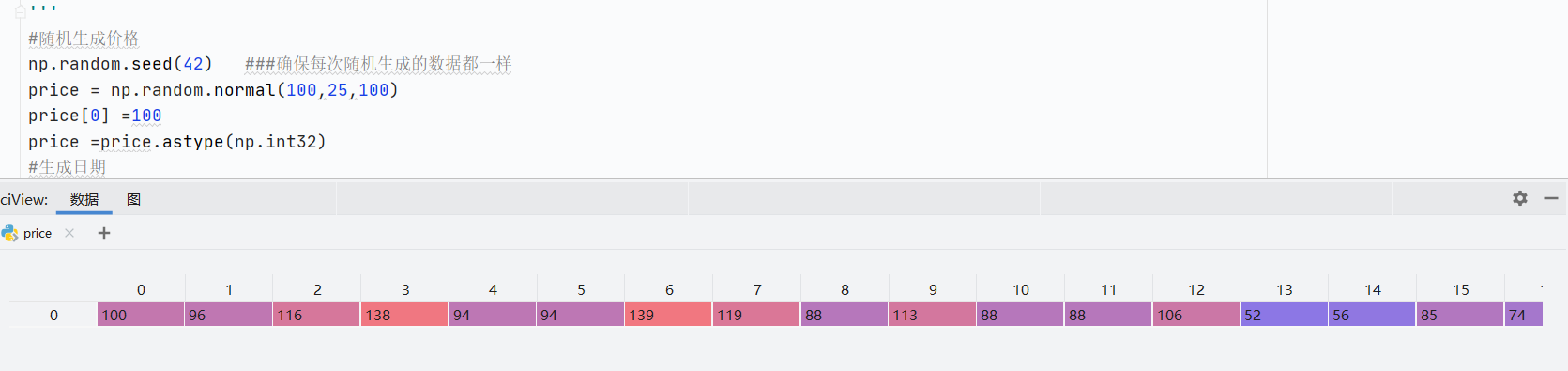
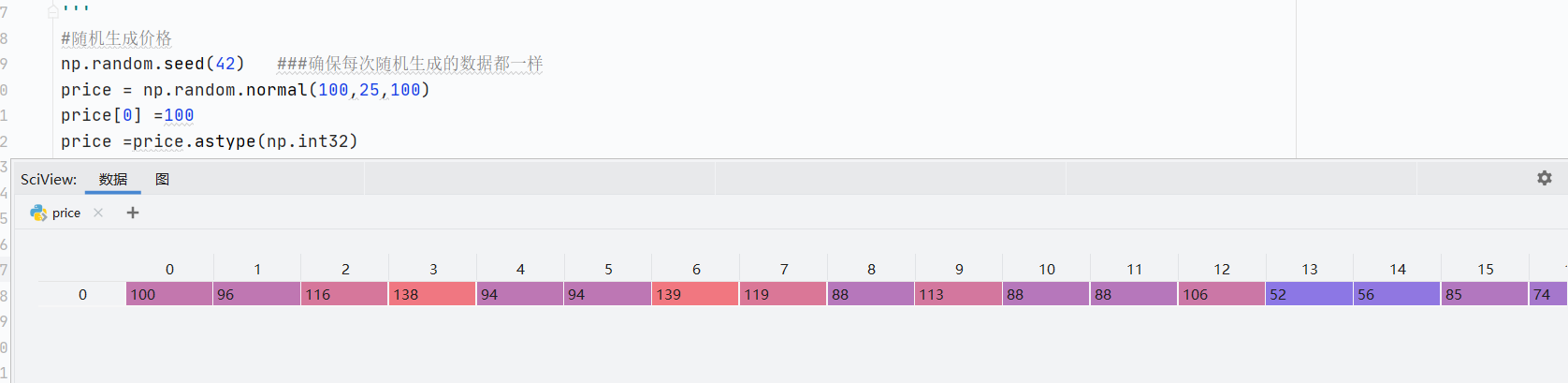
np.random.normal()自定义正态分布
![]()
-
np.random.uniform()自定义均匀分布,区间内所有数值的概率相同
![]()
-
np.random.seed(42)确保每次随机过后的数据值都一样
![]()




-
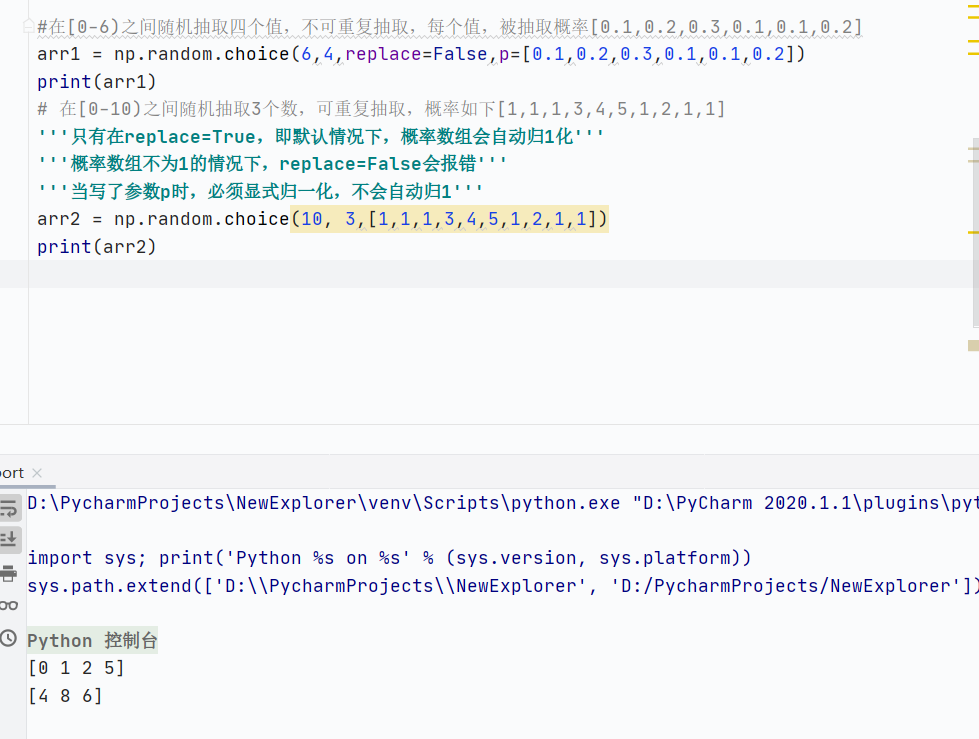
np.random.choice():随机抽样,a必须是一维数组,replace表示是否重复抽取,p表示抽取概率
![]()
-
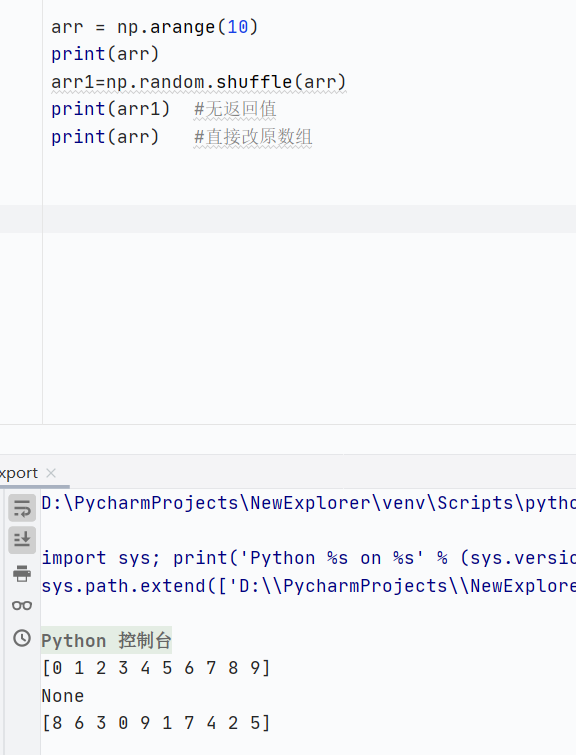
np.random.shuffle()原地洗牌,直接修改原数组
![]()
-
np.random.permutation()返回打乱后的新数组,原数组不变
![]()

其他特殊数组
-
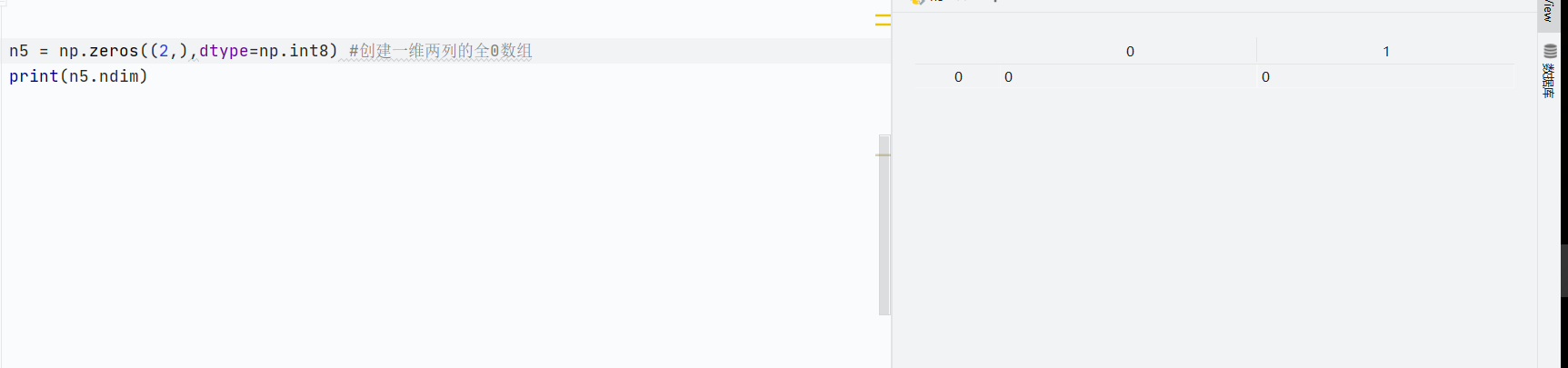
np.zeros()创造全0数组-
创建指定形状的全0数组
![]()
-
创建指定类型的全0数组
![]()
-
-
np.ones()创建全1数组-
创建指定形状的全1数组
![]()
-
创建指定数据类型的全1数组
![]()
-
自定义填充
![]()
-
-
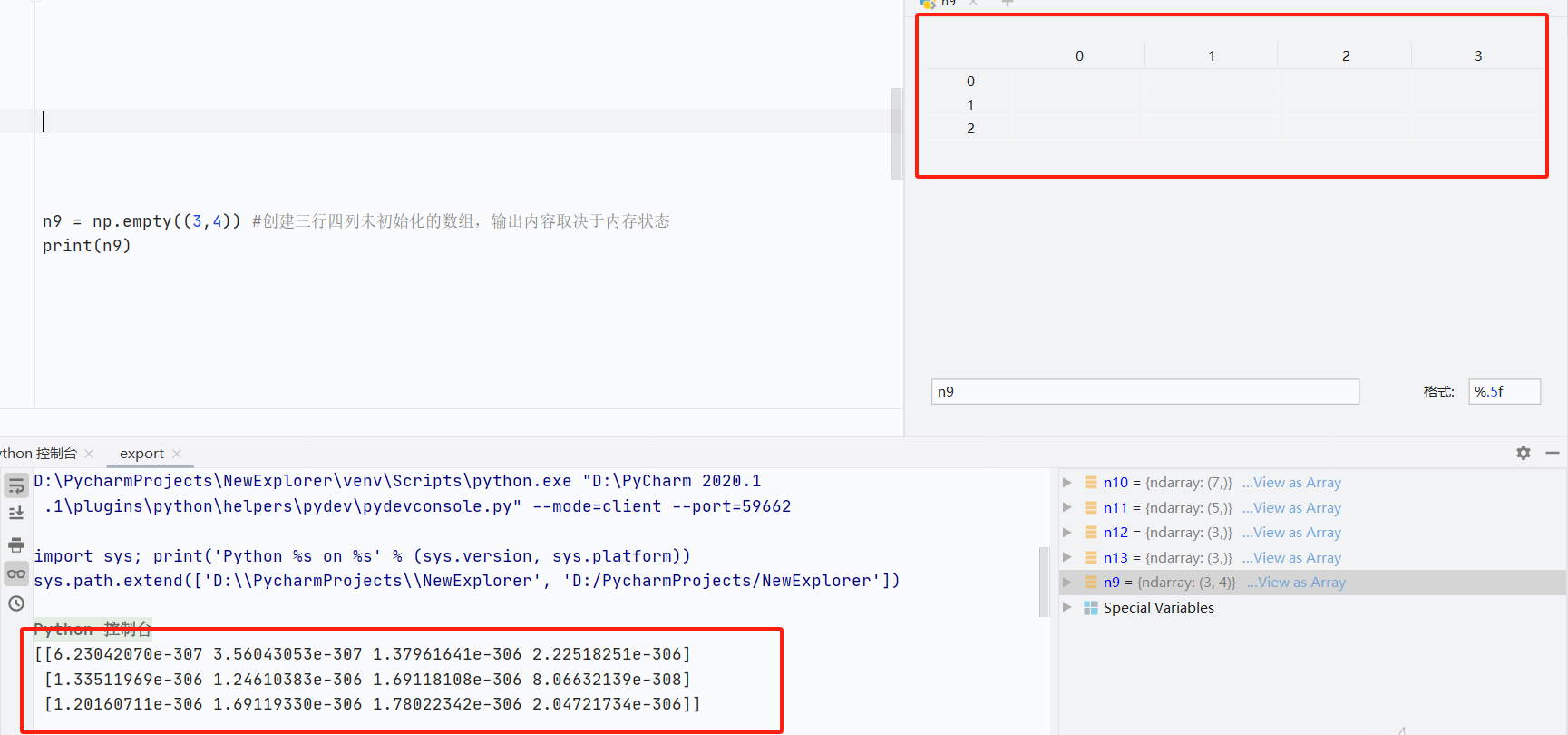
np.empty()未初始化数组- 创建随机内容数组,取决于内存
![]()
- 创建随机内容数组,取决于内存
-
np.arange()数值范围数组-
创建指定范围内数组
![]()
-
创建指定范围内数组,并指定数据类型
![]()
-
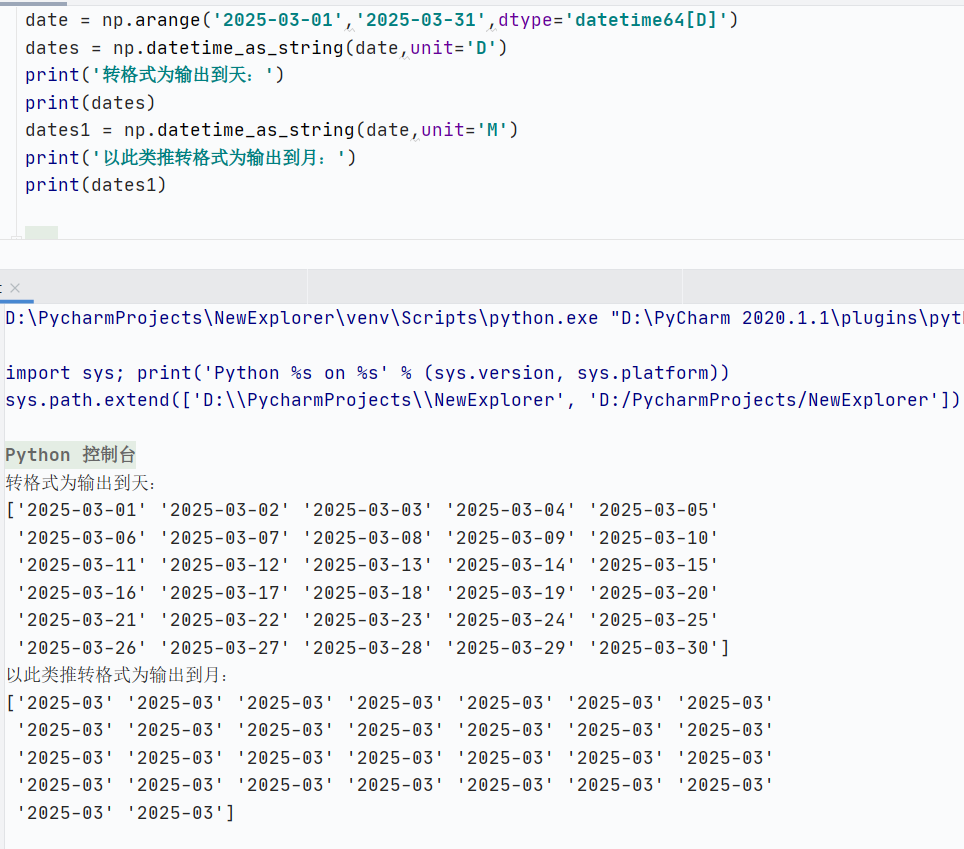
创建日期数组
![]()
格式化输出(在使用 np.arange(start, end, dtype='datetime64[D]') 生成日期时,输出的日期显示包含时分秒的现象,是由 NumPy 内部日期时间表示机制和默认的字符串格式化规则 导致的)
![]()
-
-
np.linspace()线性间隔数组-
创建等距数组,默认包含终点
![]()
-
创建包含终点的等差数组
![]()
-









数组属性
-
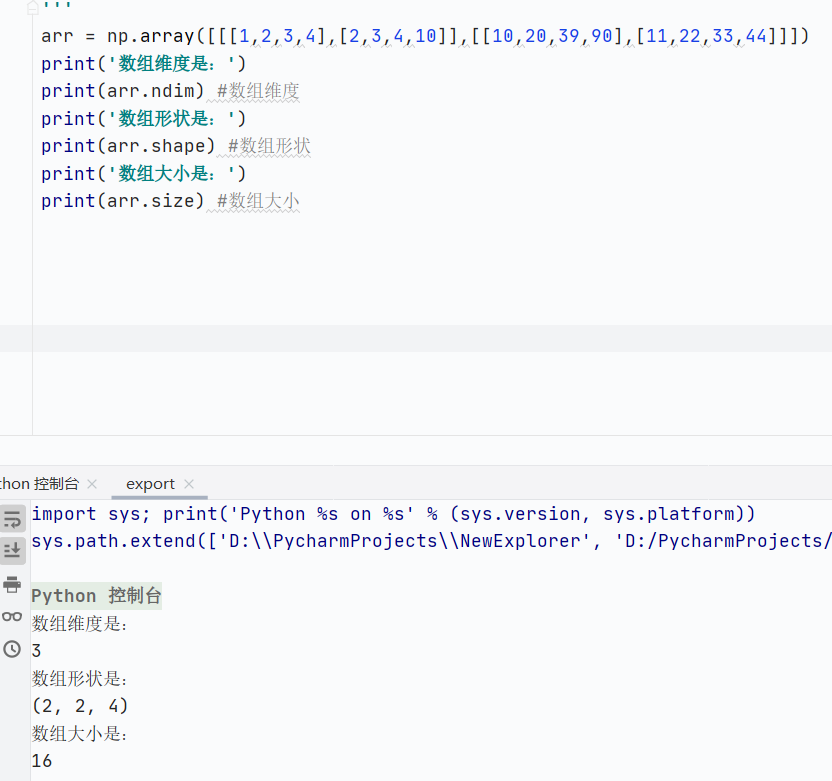
数组维度
![]()
-
数据类型
![]()
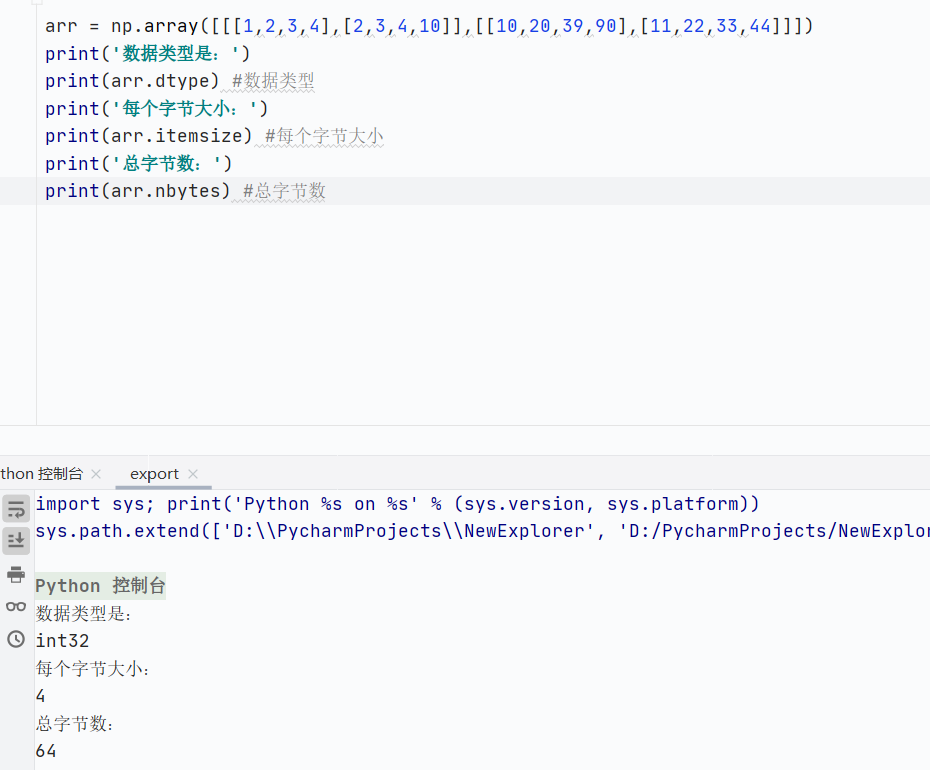
数组数据类型
-
常见数据类型如下图
![]()
-
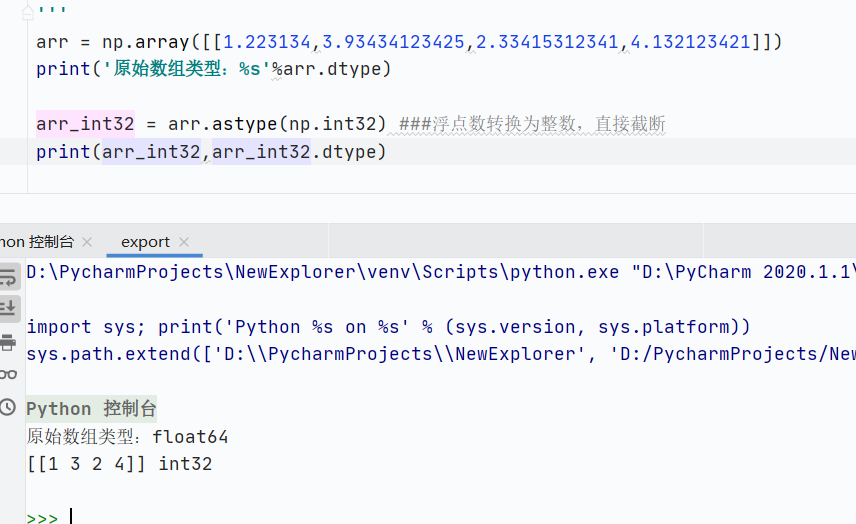
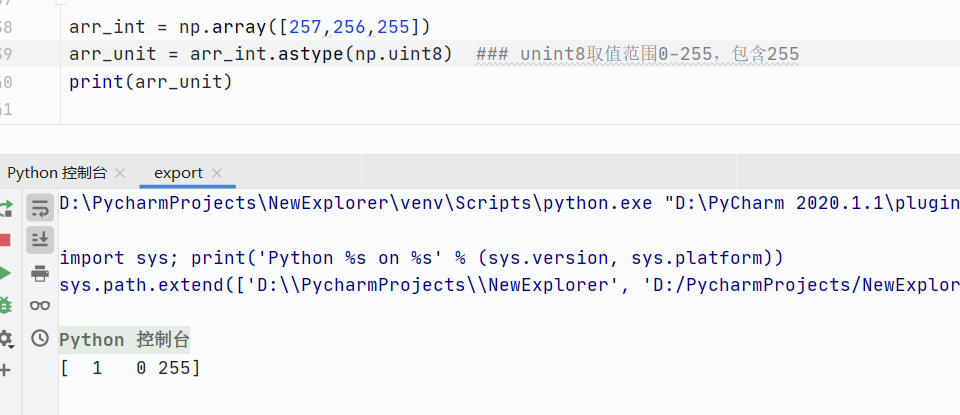
astype()数据类型转换-
浮点数转换为整数,直接截断(非四舍五入)
![]()
-
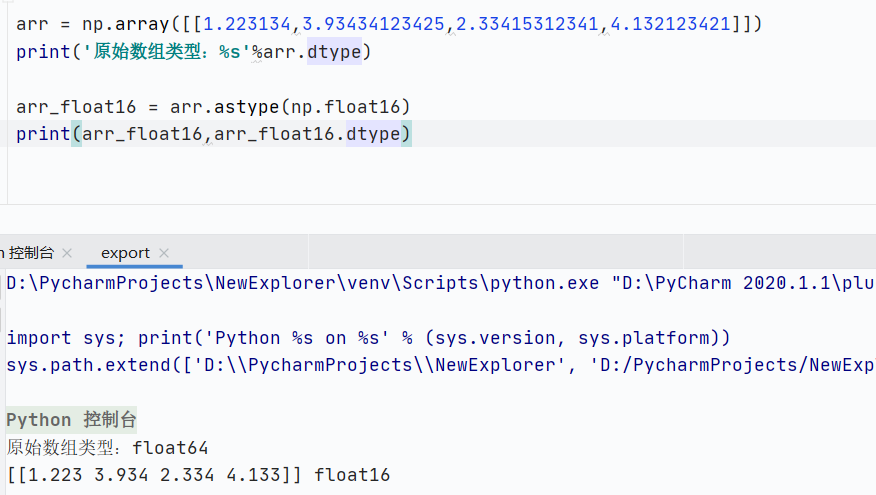
高精度浮点数转换成低精度浮点数
![]()
-
大整数转换为小类型整数,溢出,自动取模
![]()
-
字符串转换成数值
![]()
-
数值转换成布尔值
![]()
-
数值转换成日期格式
![]()
![]()
![]()
-






特殊数组
- 单位矩阵
np.eye()对角线为1,剩下数值由0填充
![]()


-
对角矩阵
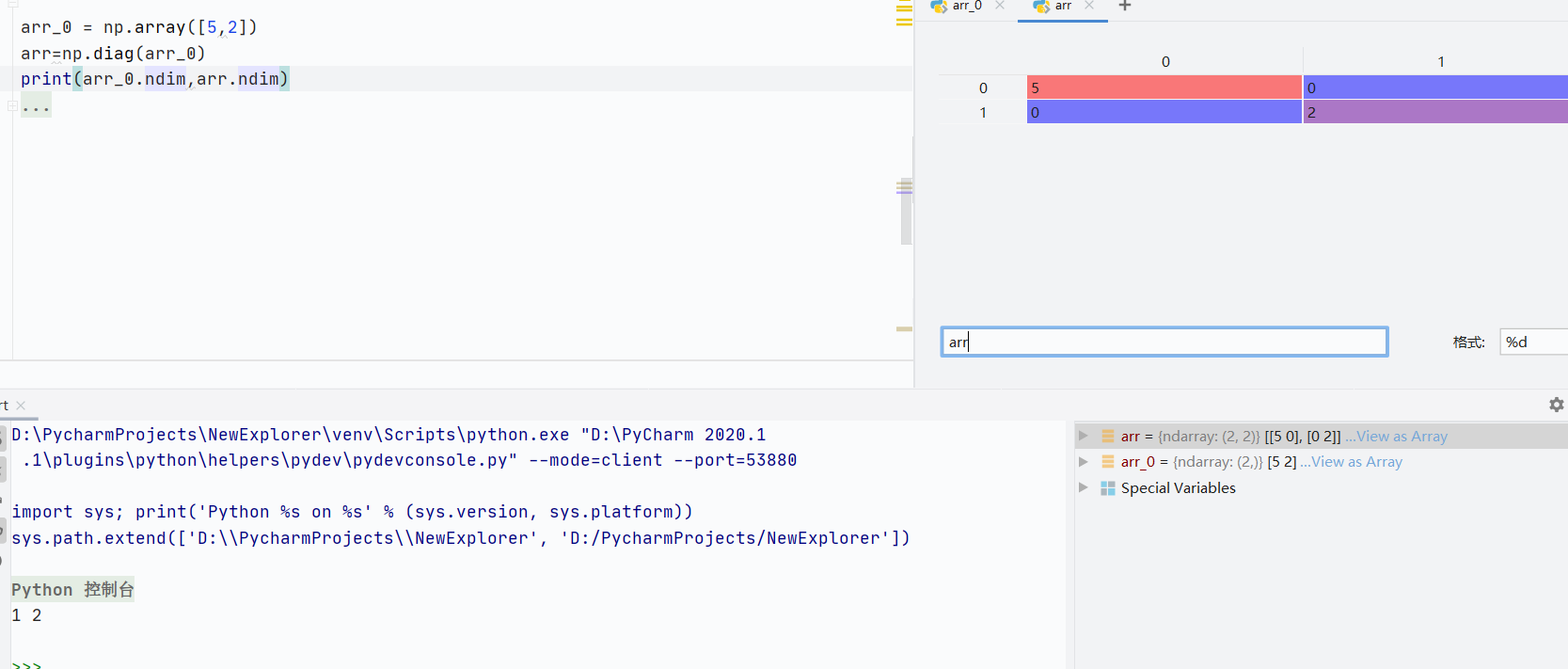
np.diag()-
一维数组会变成二维数组,对角线数值为给定数组,剩下由0填充
![]()
-
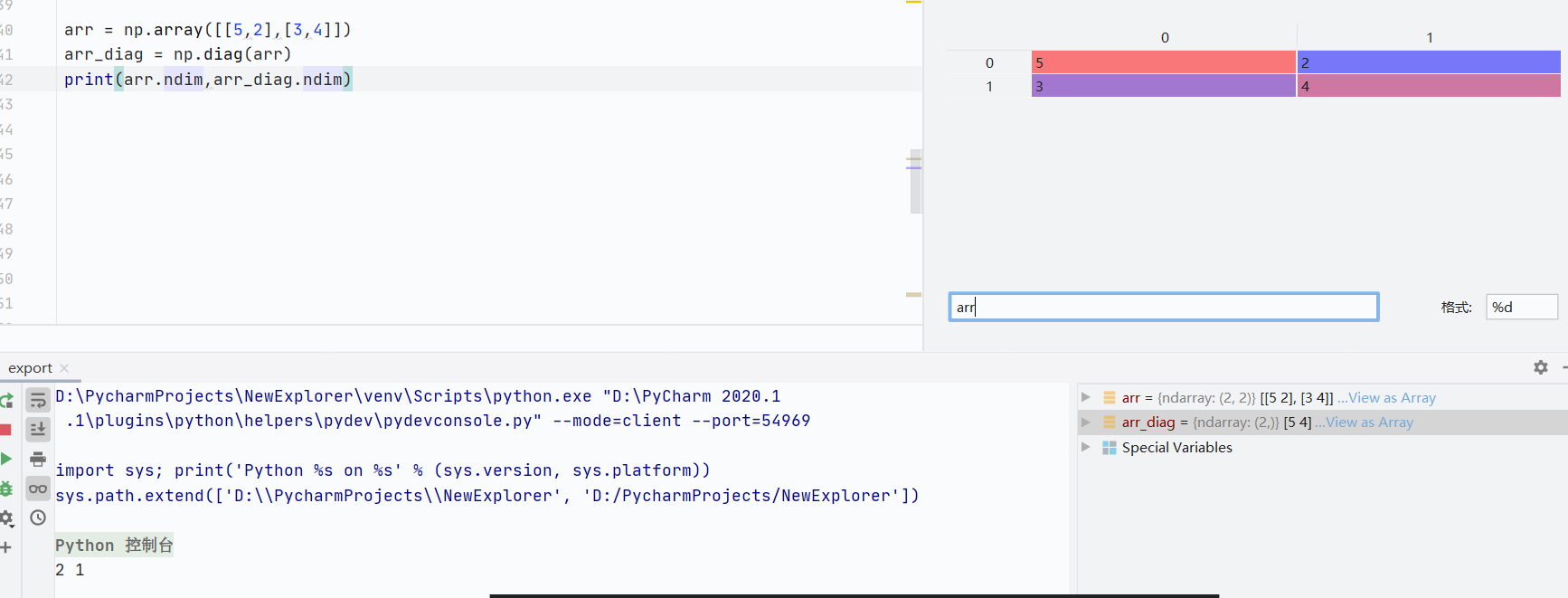
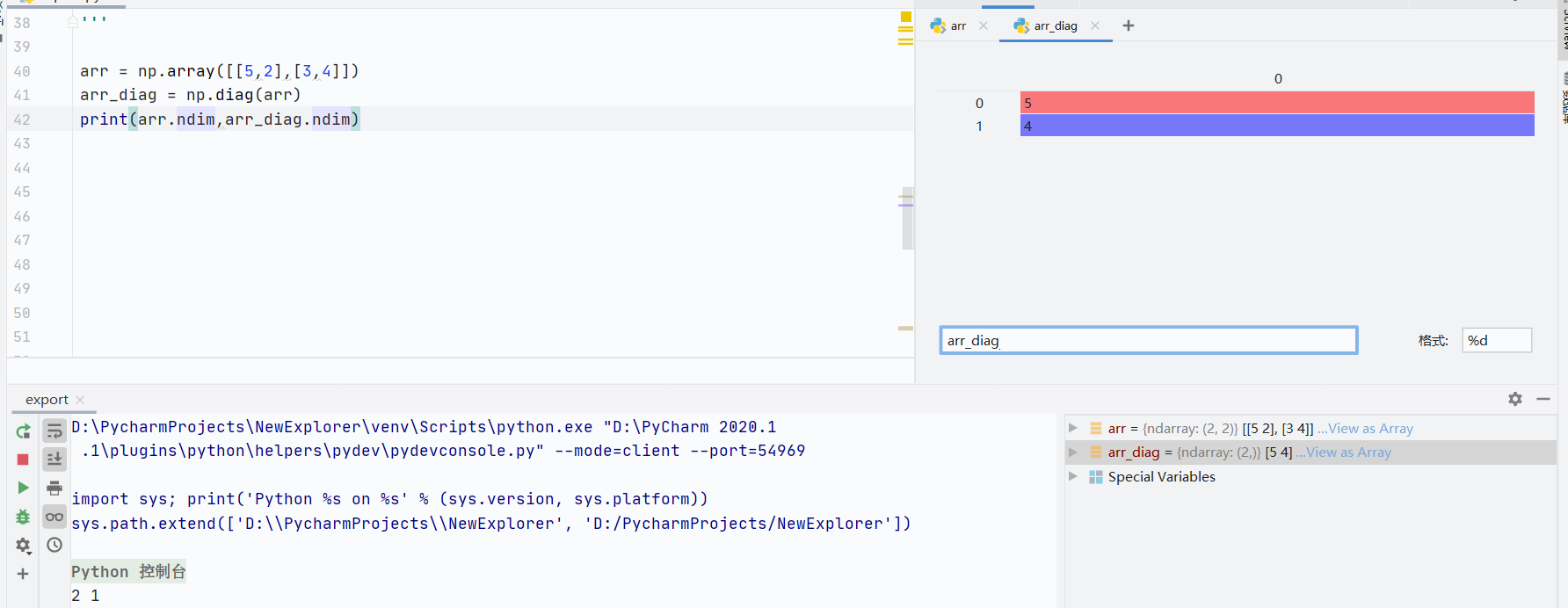
二维数组会变成一维数组,只显示对角线数值
![]()
![]()
-
数组操作
索引和切片
-
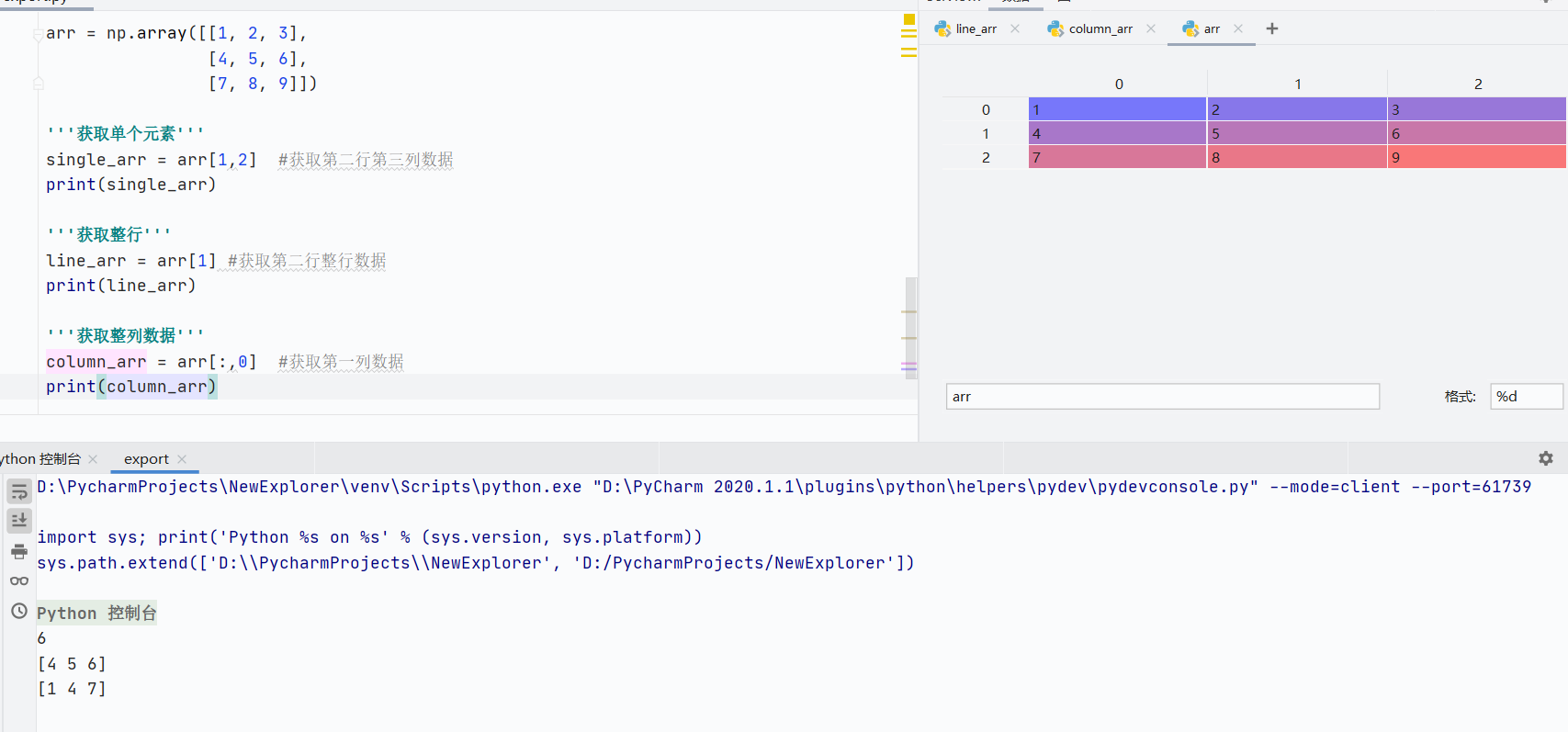
基础索引
![]()
-
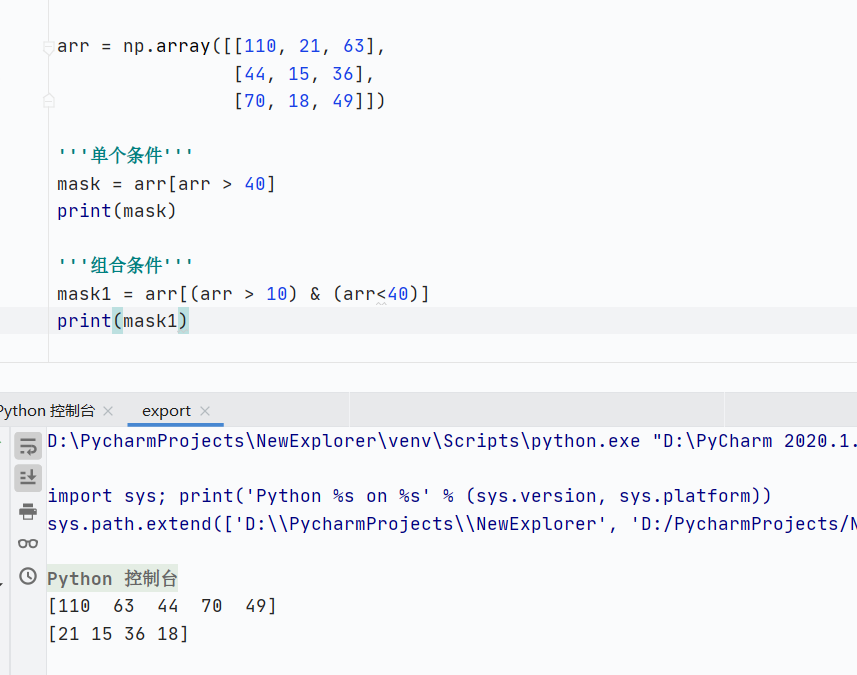
布尔索引
![]()
-
切片操作
-
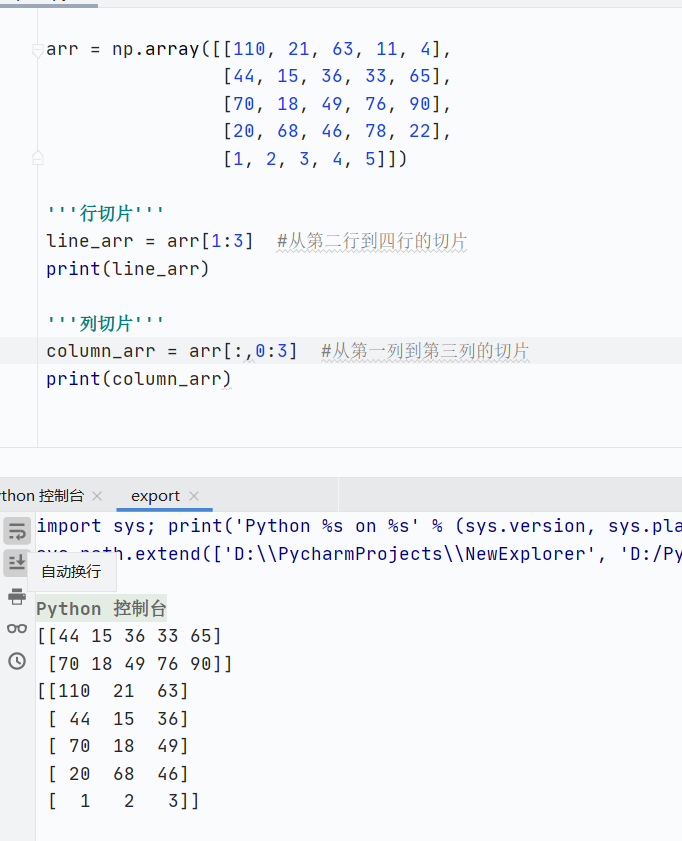
行列切片
![]()
-
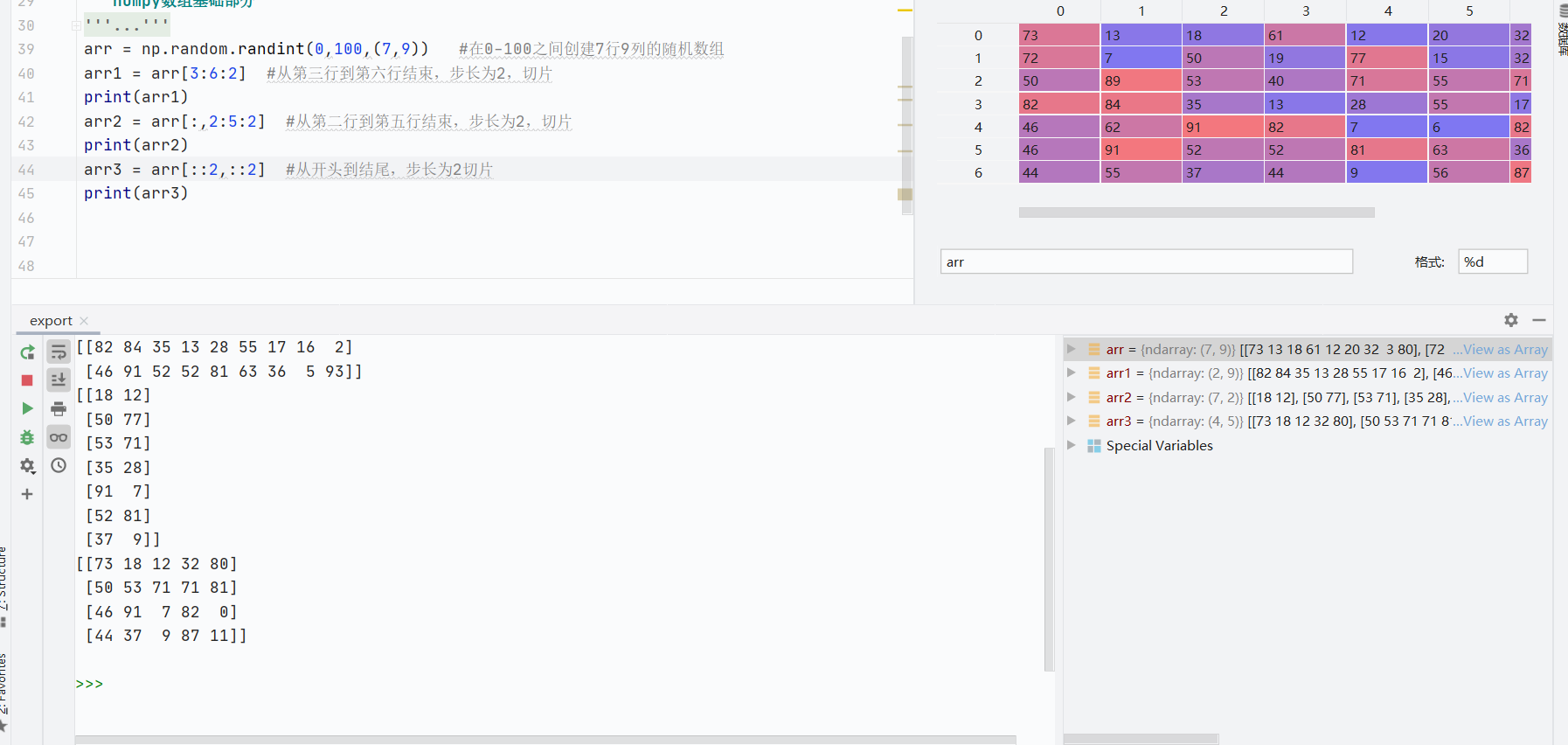
步长切片
![]()
-
形状操作
-
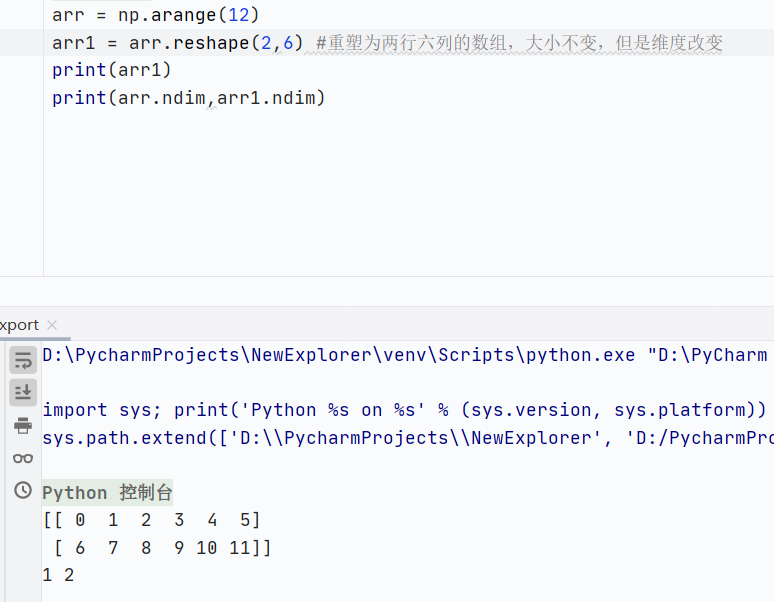
reshape()重塑形状
![]()
-
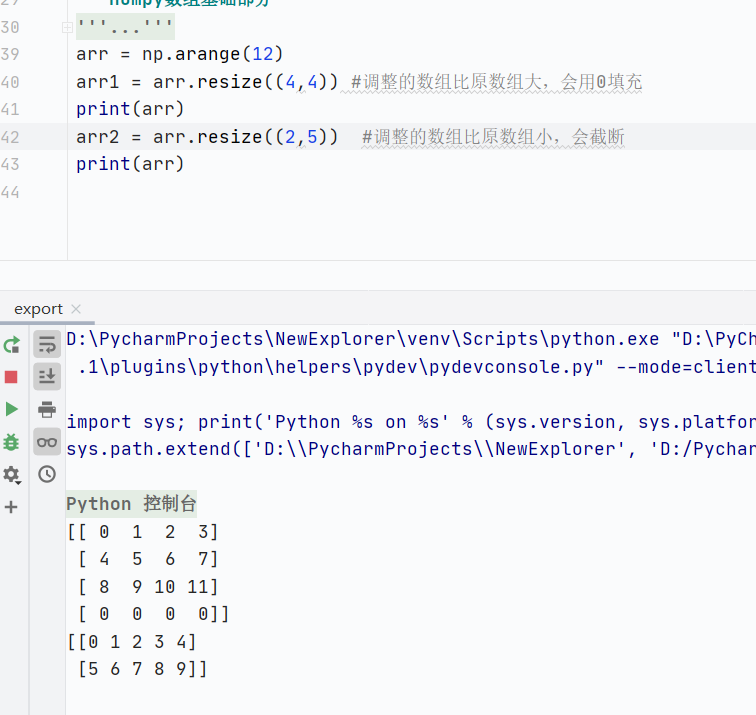
resize()调整大小,直接修改原数组,返回值为None
![]()
-
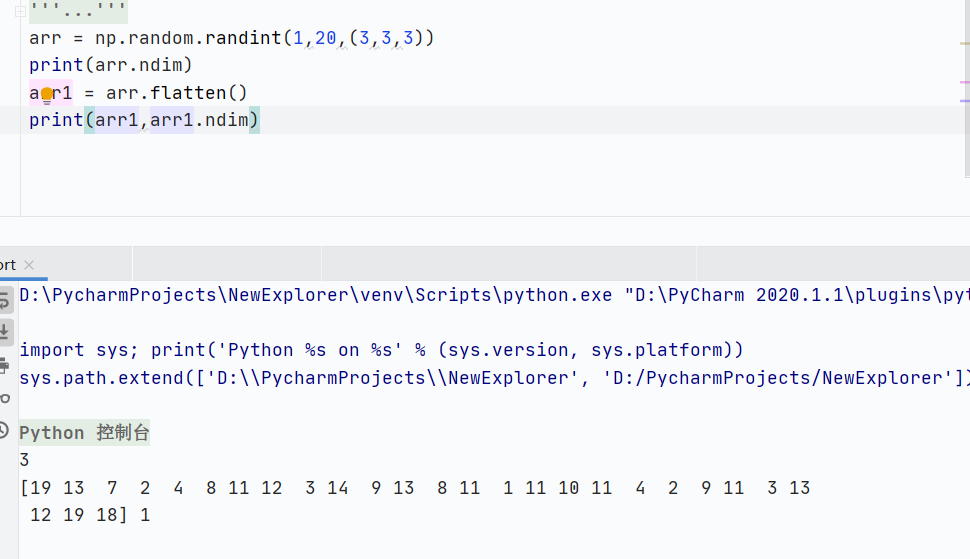
flatten()展平数组,多维数组转换为一维数组,深拷贝,不影响原数组
![]()
数组堆叠
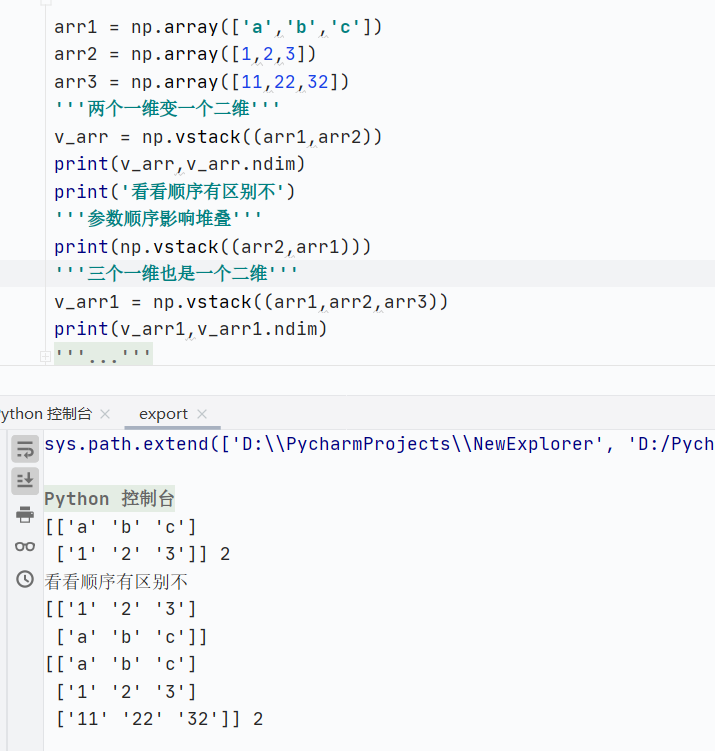
np.vstack()垂直堆叠
![]()

np.hstack()水平堆叠,数据类型必须相同,否则报错
![]()
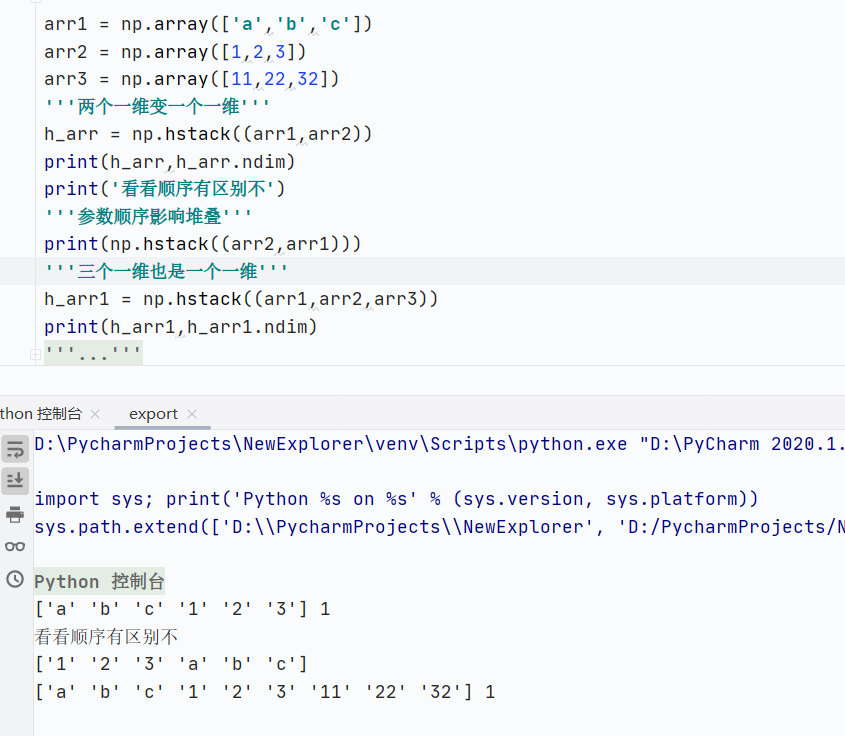

np.concatenate()通用堆叠,数据类型必须相同,否则报错
![]()

数组分割
-
np.split()-
平均分,数组大小一定要能被均分,不然报错
![]()
-
自定义分
![]()
-
-
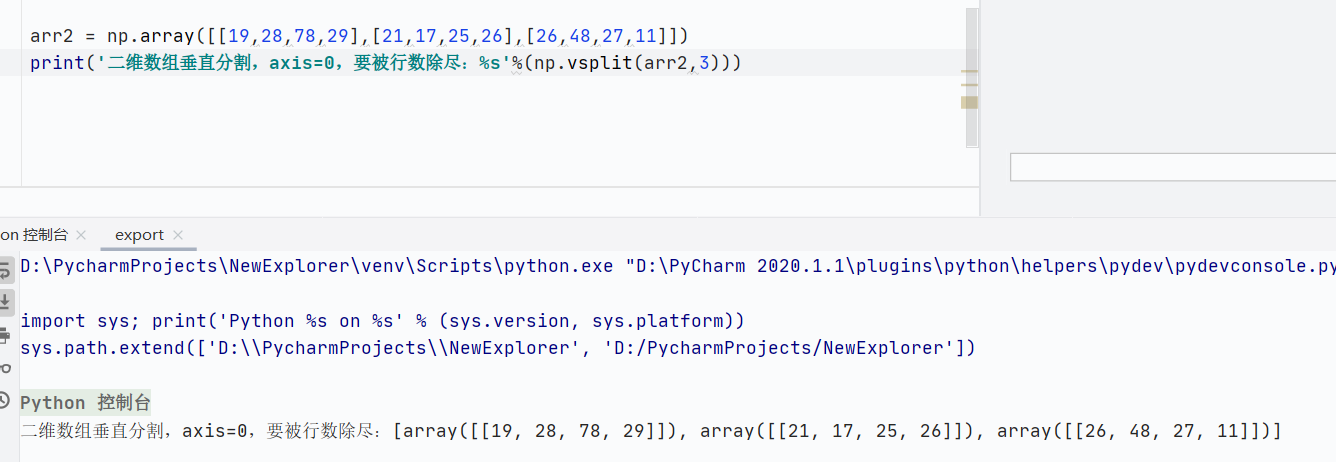
np.vsplit()垂直分割,用于一维数组报错,axis=0,行相关
![]()
-
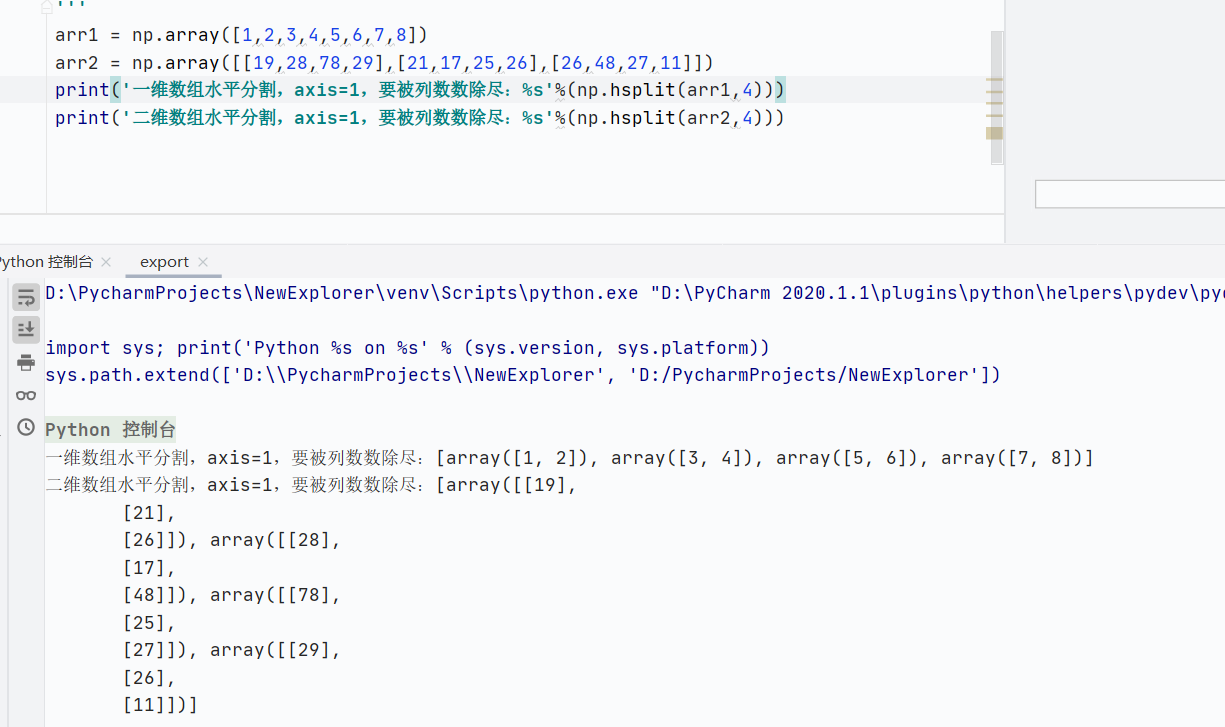
np.hsplit()水平分割,axis=1,列相关
![]()


中级部分
数组运算
广播机制(Broadcasting)
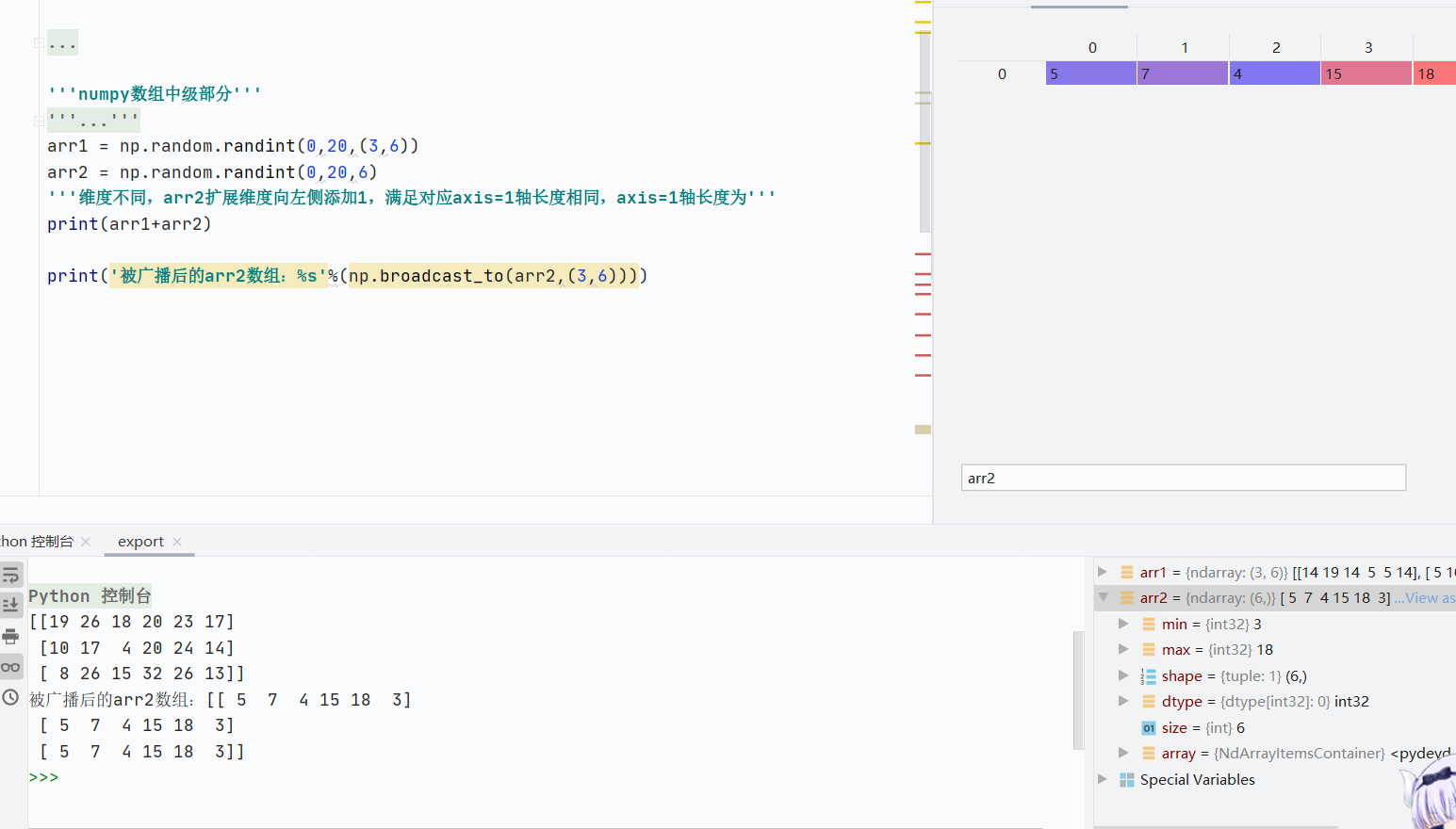
广播是 NumPy 对不同形状数组进行数学运算的规则。当两个数组形状不同时,自动扩展较小数组的维度,使其与较大数组的形状兼容,从而完成逐元素运算。
广播机制
-
先比较形状,在比较维度,再比较对应轴长度
-
如果两个数维度不相等,会在低维度数组形状左侧填充1,直到维度与高维度数组相等
![]()
-
如果维度相同,形状不同情况下,数组对应轴长度相同,且有一轴为1
![]()
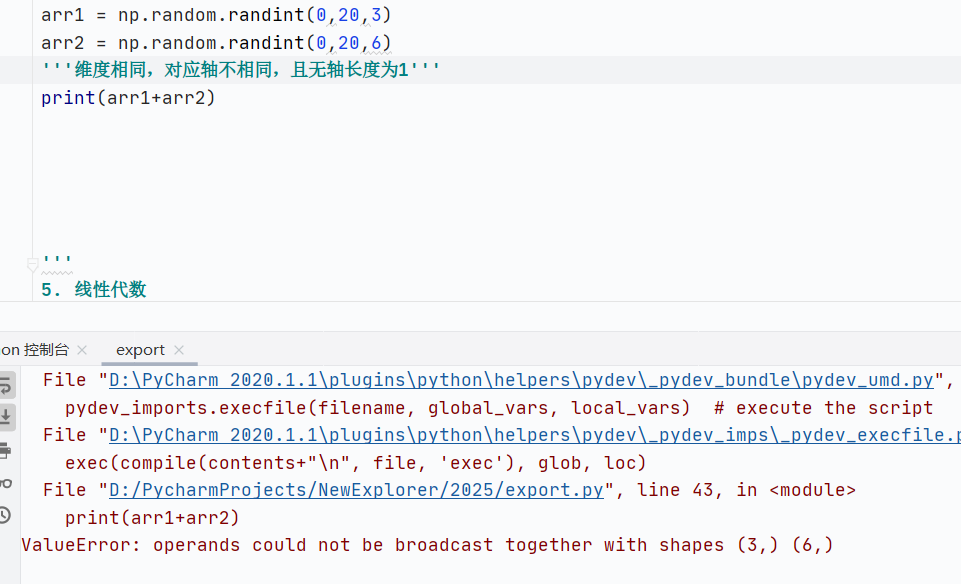

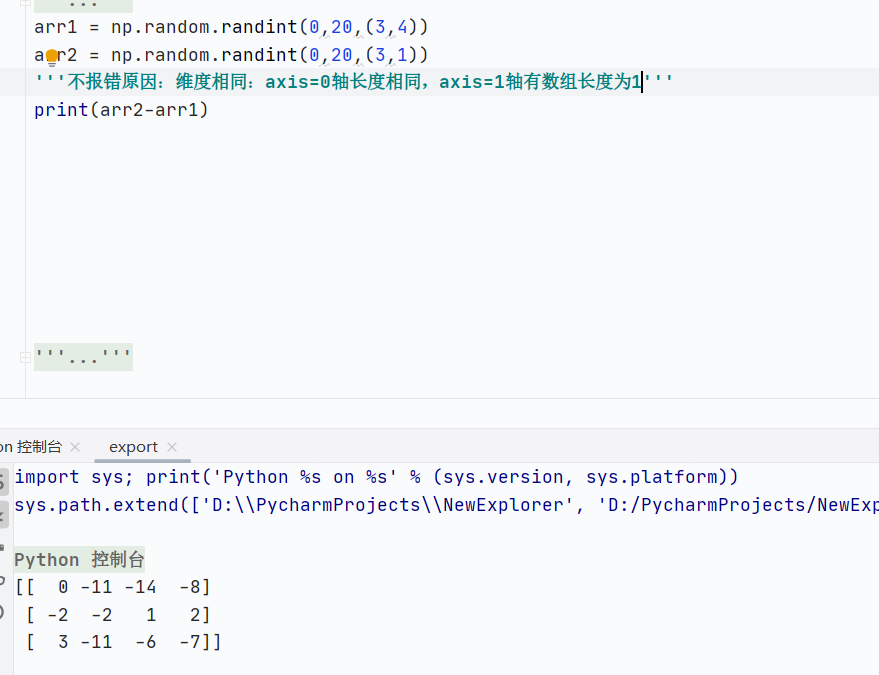
基础数组运算
+,-,*,/,``
![]()
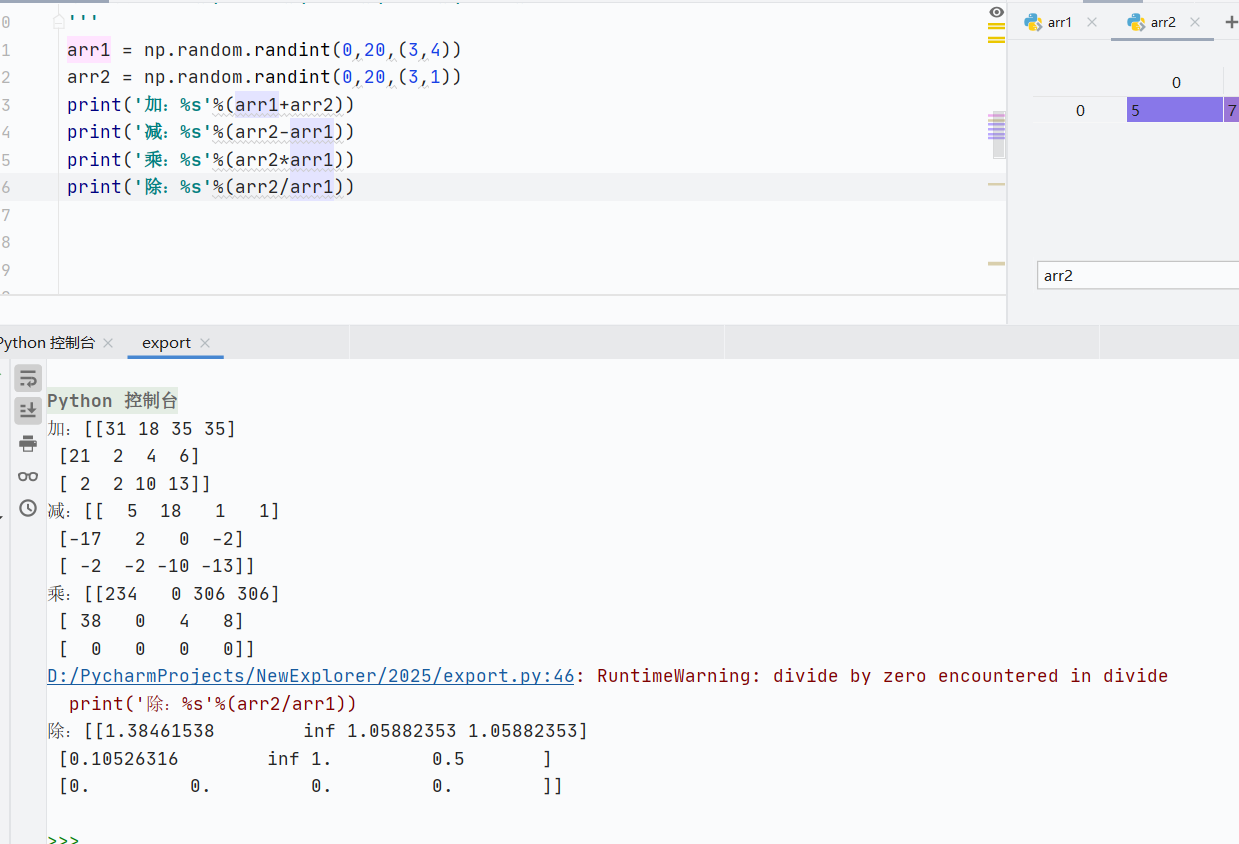
通用函数
-
np.sqrt()开根号
![]()
-
np.exp()指数
![]()
-
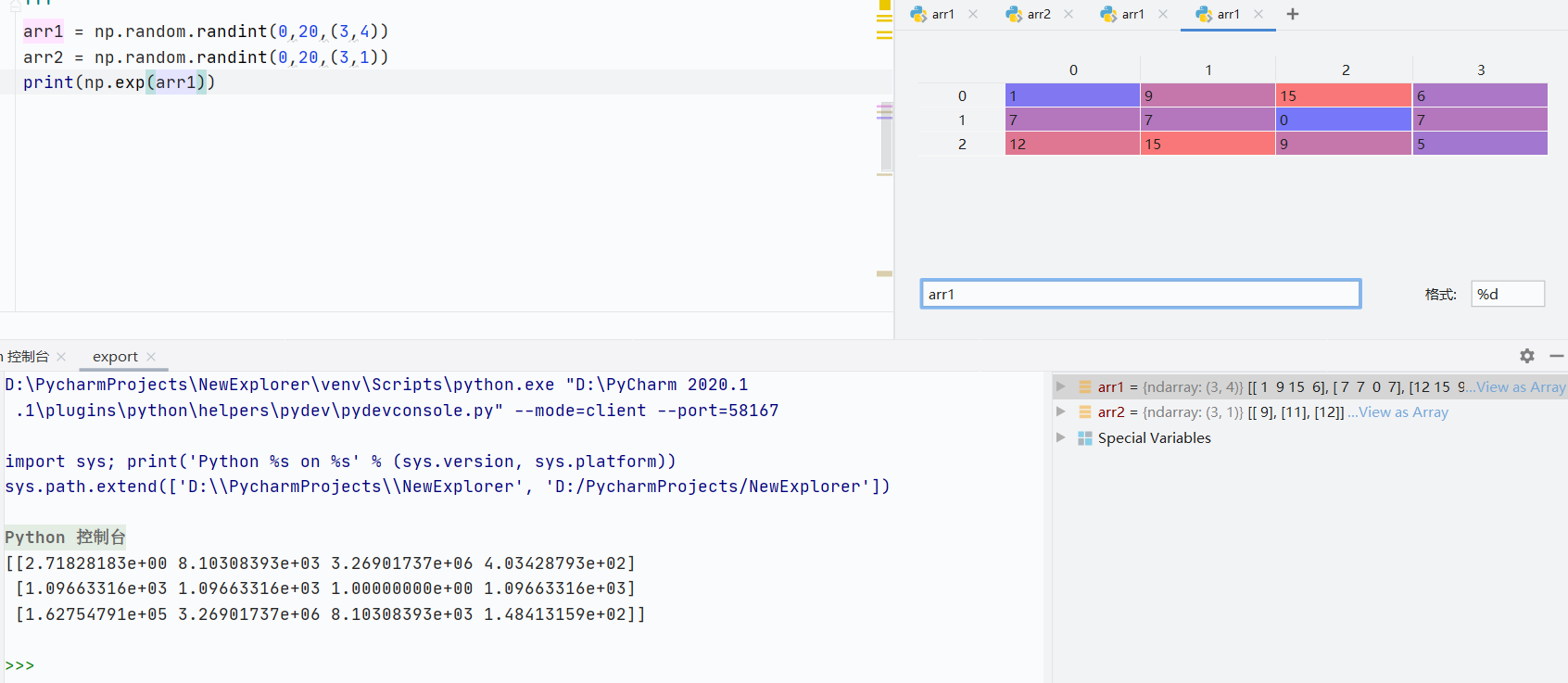
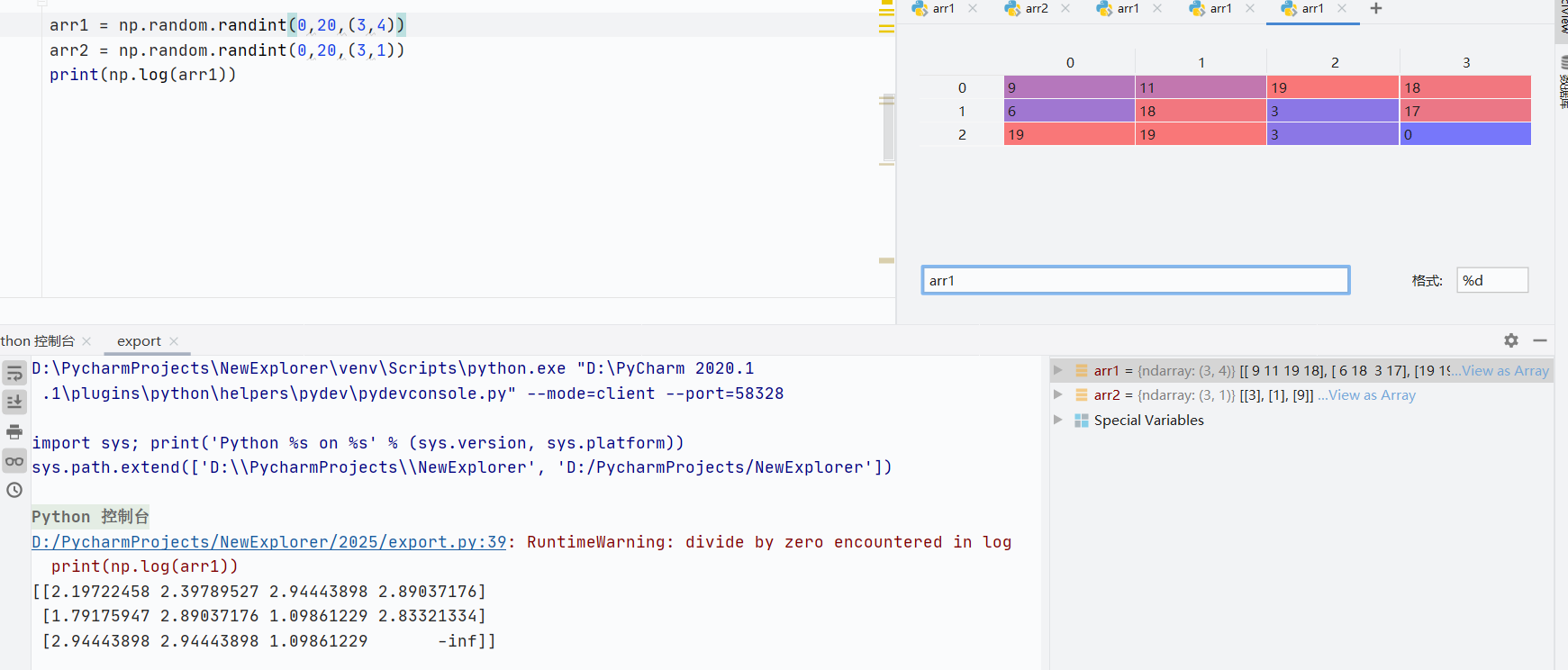
np.log()自然对数
![]()
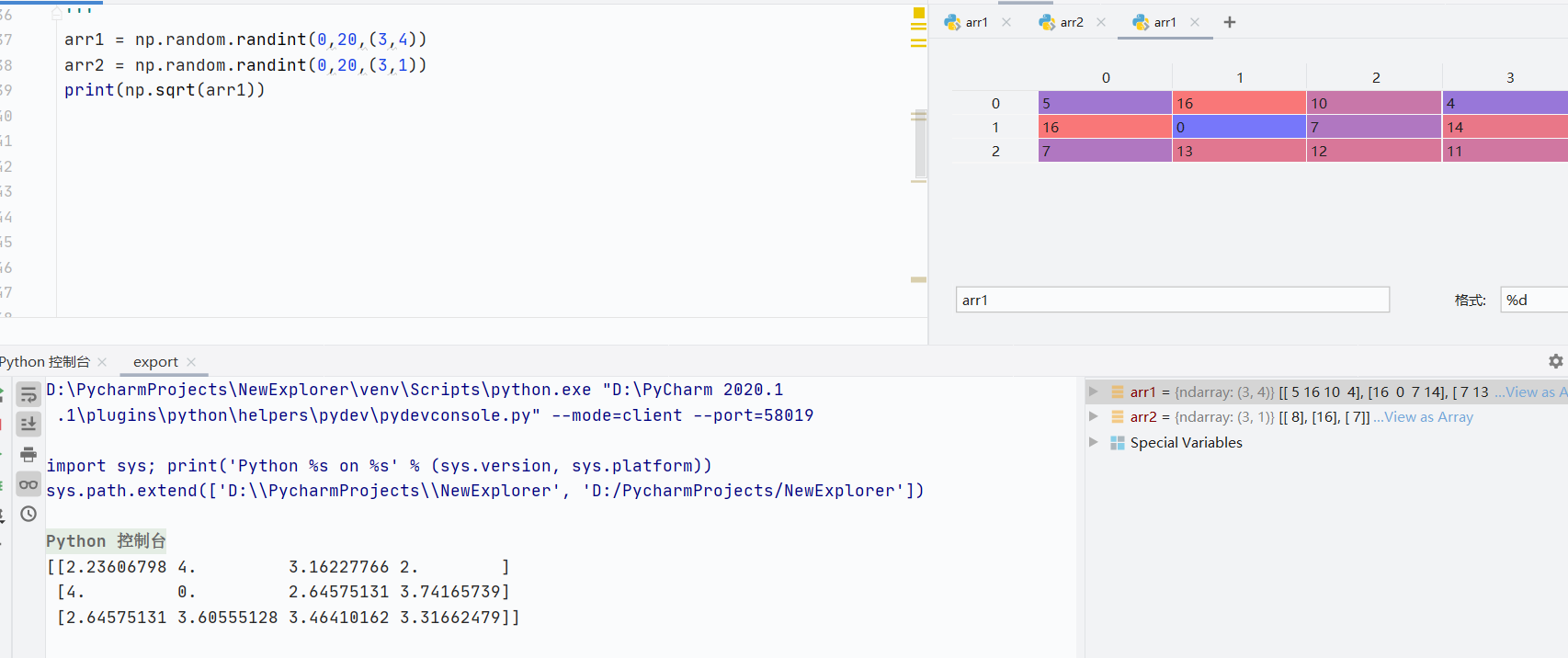
聚合函数
-
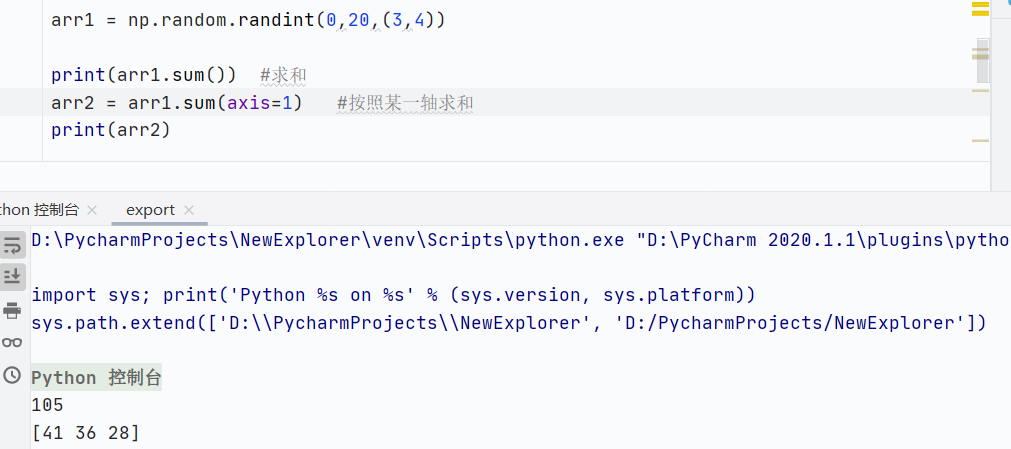
sum()求和
![]()
-
mean()平均值
![]()
-
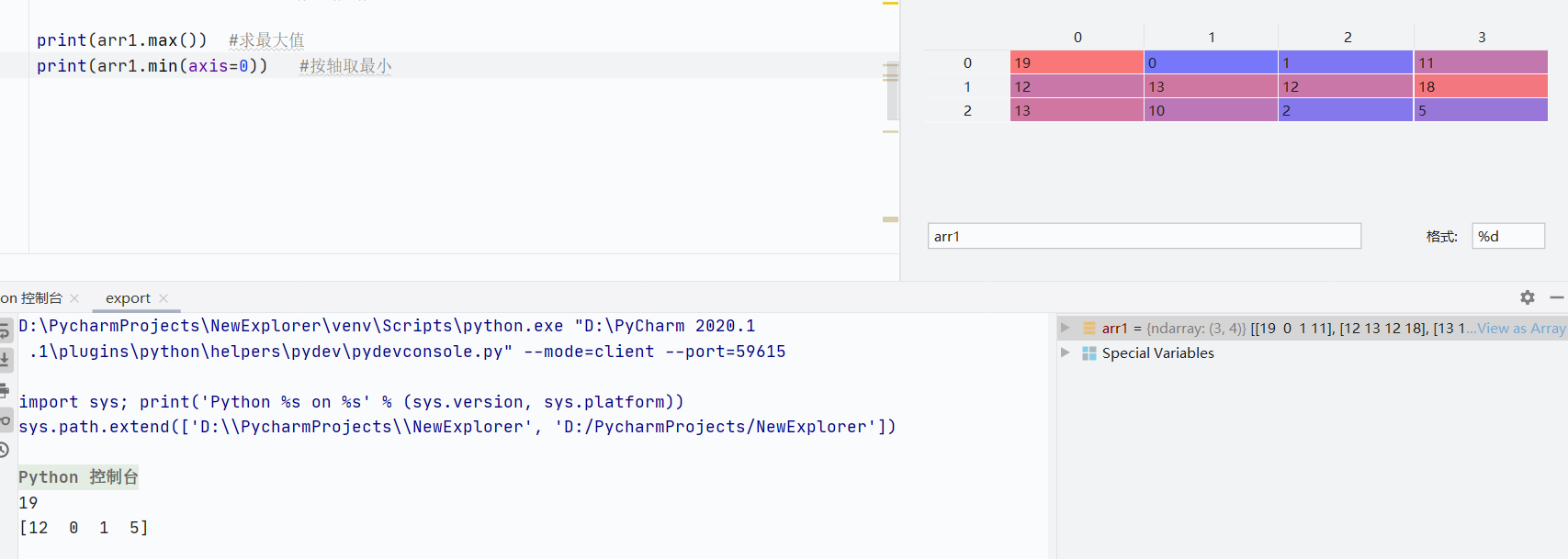
max()最大值np.min()最小值
![]()
-
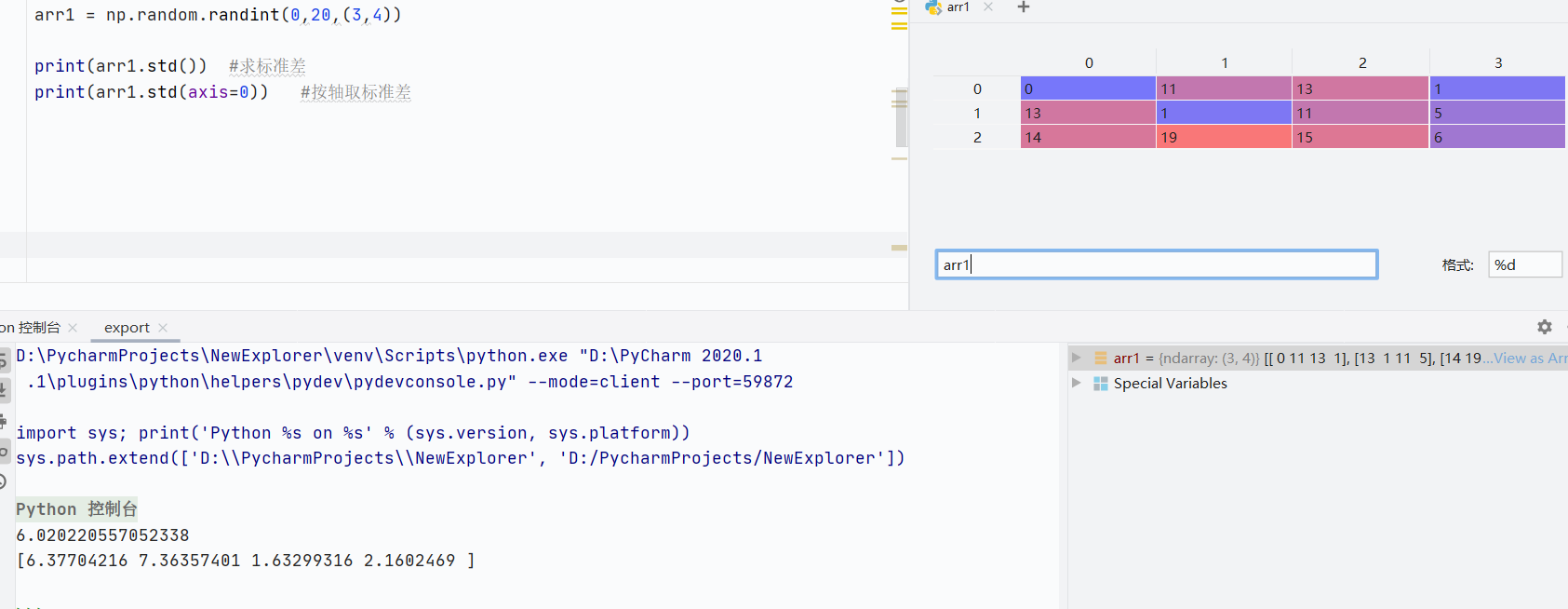
std()标准差
![]()

高级部分
高级索引
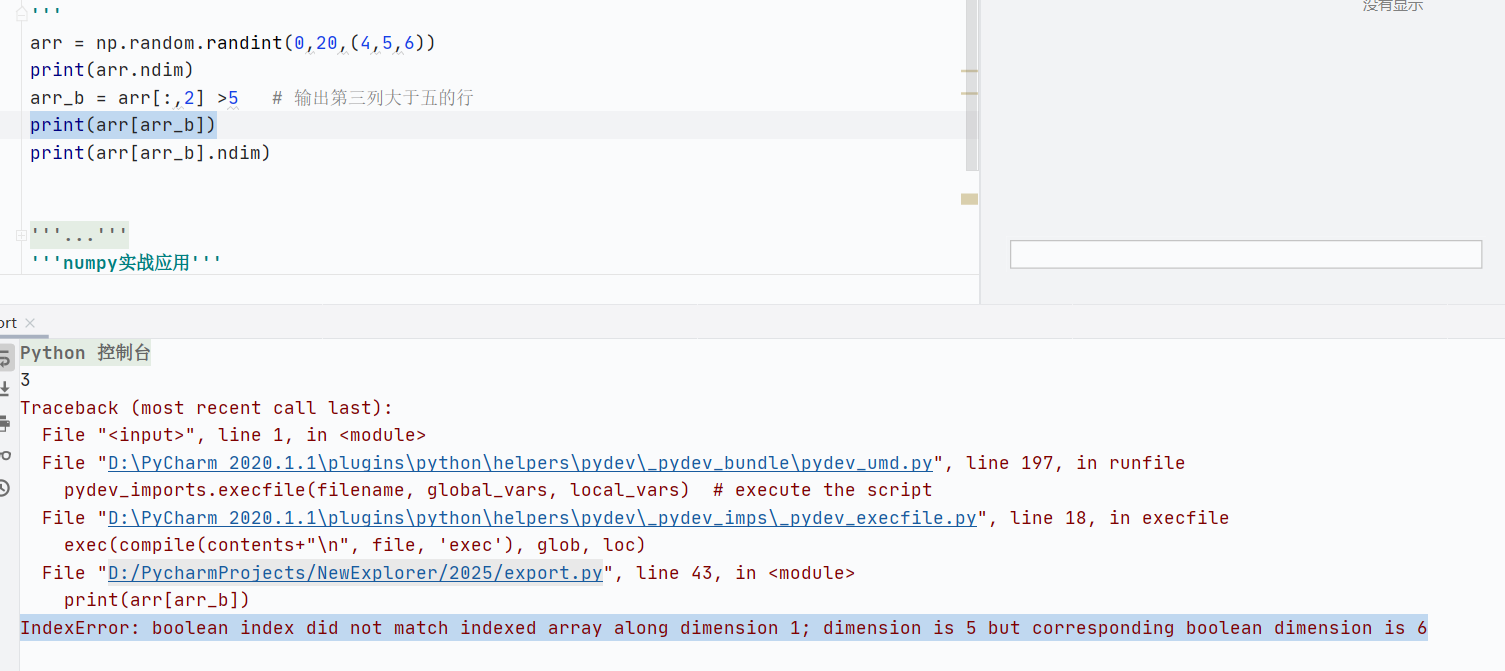
布尔索引
通过布尔条件(True/False)筛选数组中的元素
核心规则
布尔数组必须与目标数组的形状相同
返回的是满足条件(True)的元素
核心为题:NumPy 不支持直接用多维布尔数组索引多维数组,需逐层筛选
-
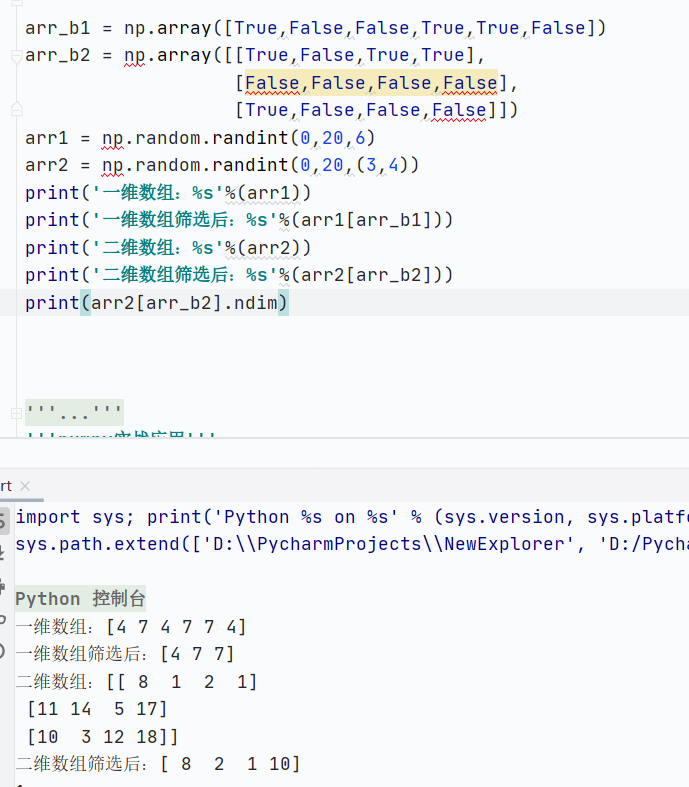
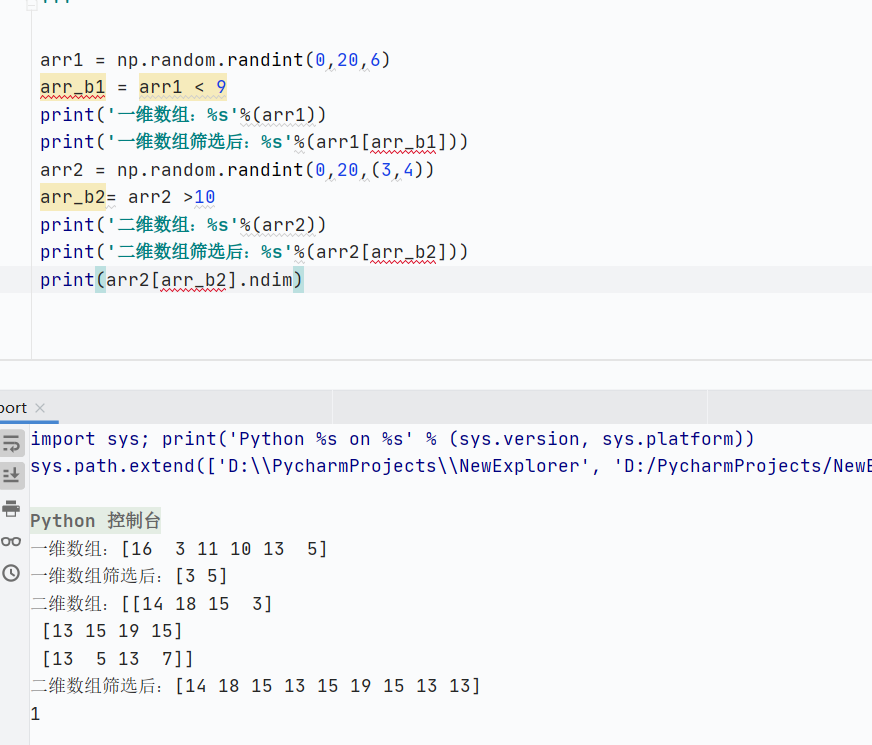
直接使用布尔数组
![]()
-
创建布尔掩码判断
![]()
-
直接使用条件表达式筛选
![]()
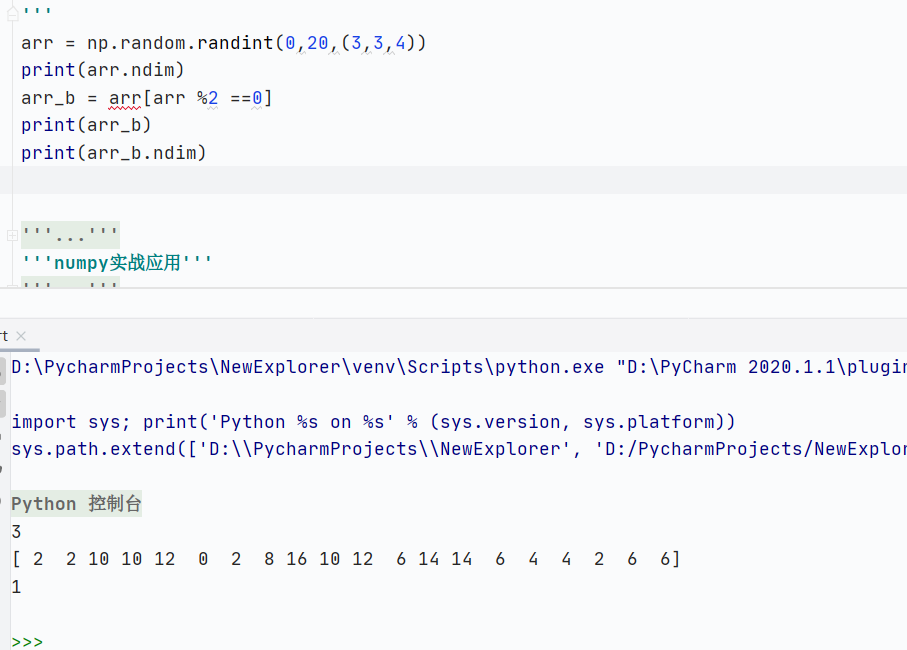
花式索引
通过整数数组(或列表)指定索引位置来访问元素,它不依赖连续或规律的位置,可以灵活选择任意位置的元素
核心规则:
传递一个整数数组作为左印,返回由这些位置元素组成的新数组
支持多维索引
-
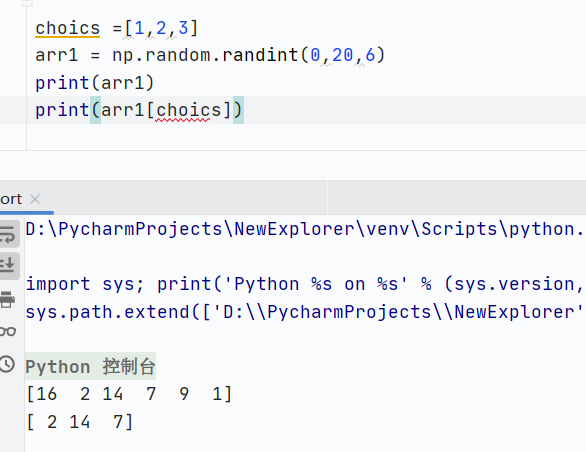
一维数组
![]()
-
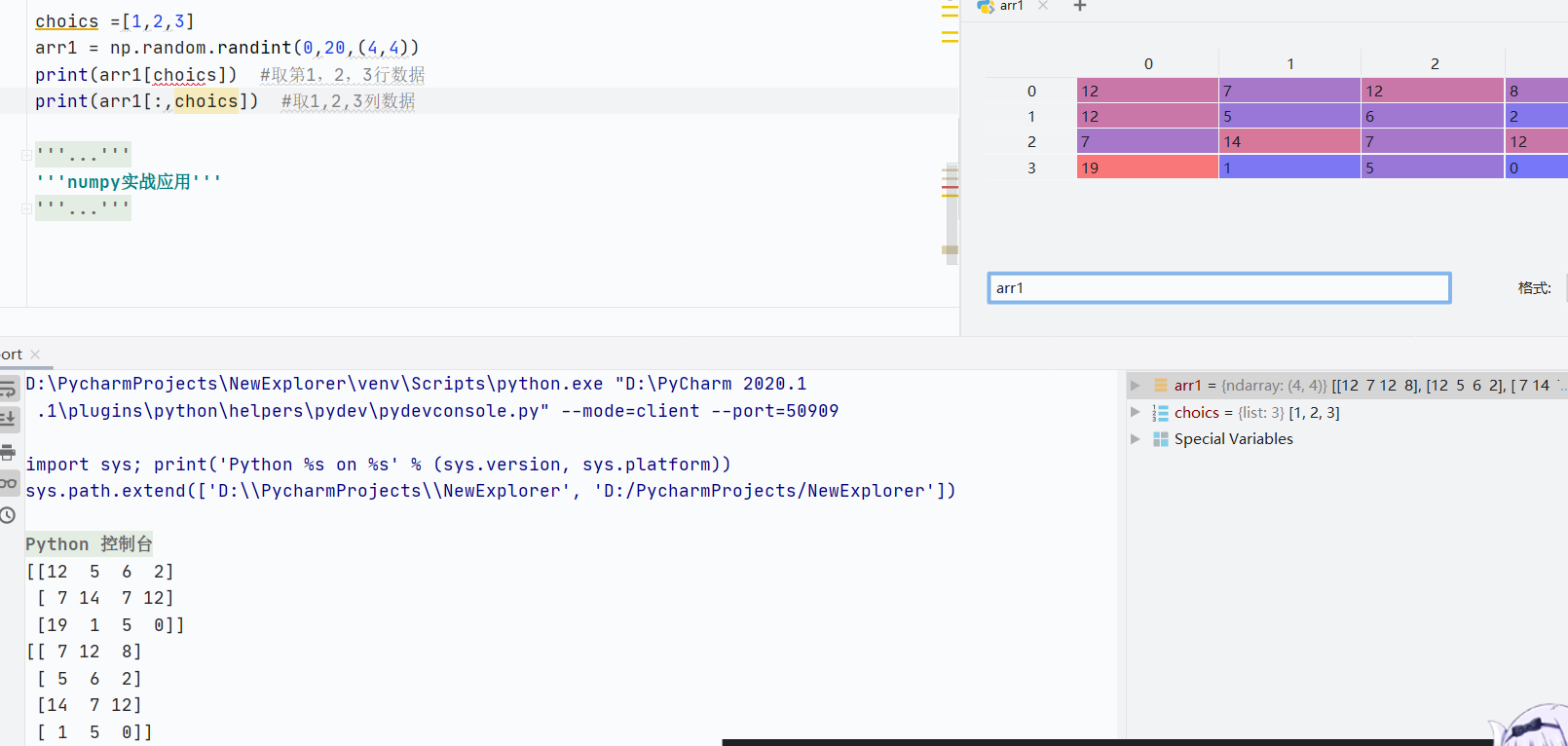
多维数组
![]()
-
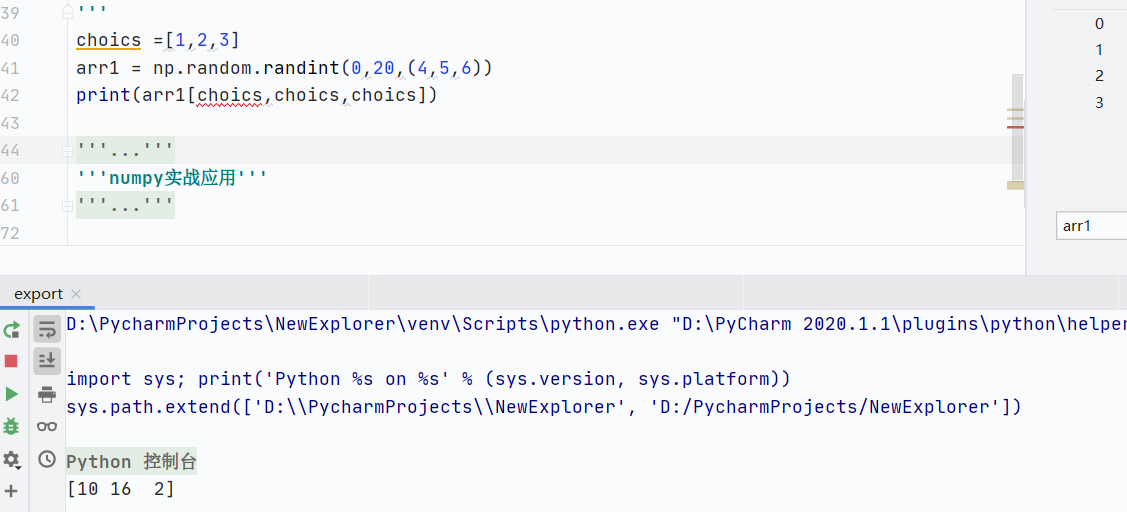
组合行列索引
![]()
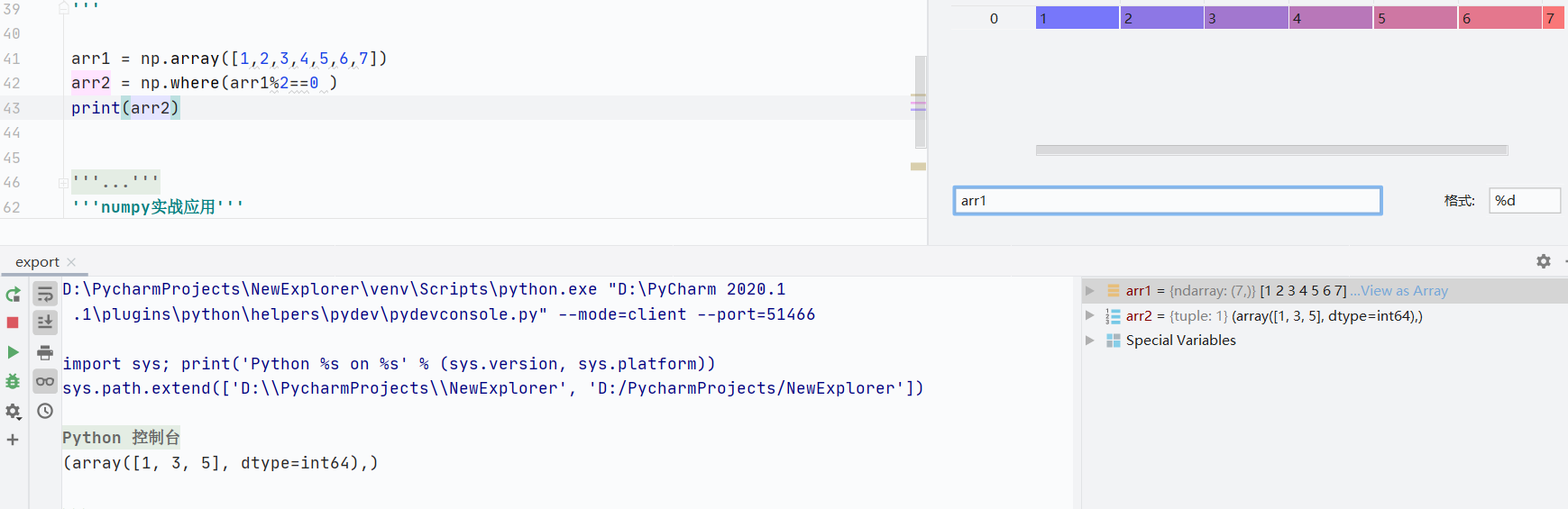
where()函数
根据条件返回满足条件的元素索引或替换纸
-
返回满足条件的索引
![]()
-
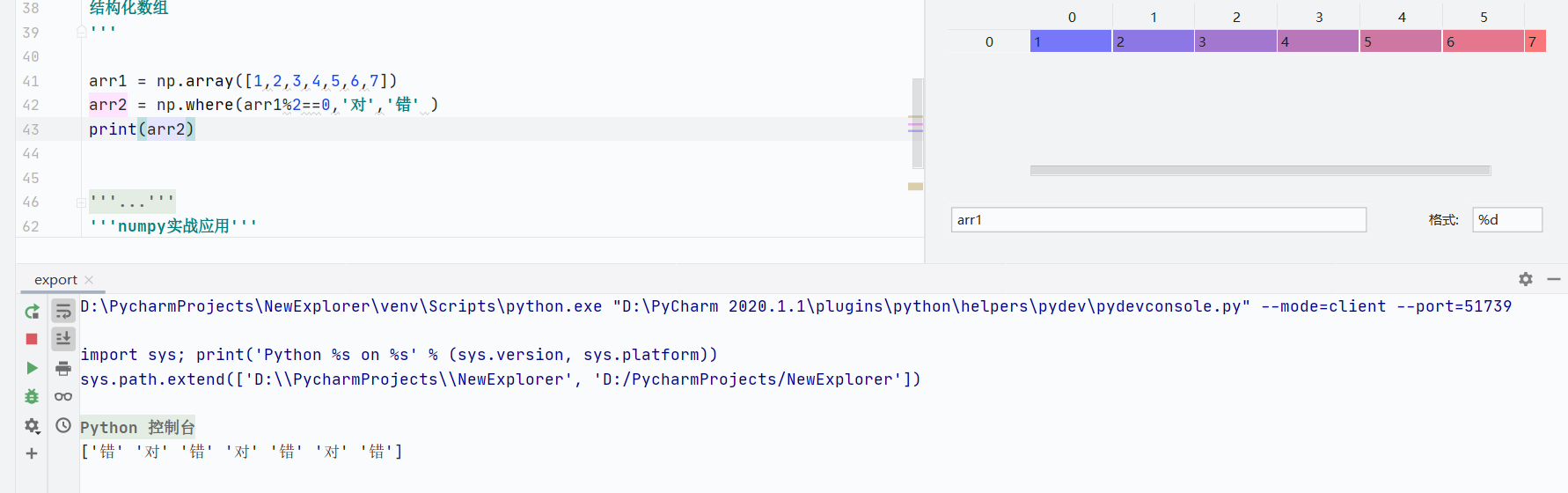
np.where(condition, value_if_true, value_if_false):条件替换
![]()
结构化数组
定义具有不同数据类型的数组,类似表格中的行
核心步骤:
定义数据类型:使用dtype指定每个字段的名称和类型
创建结构化数组:通过指定字段初始化数组
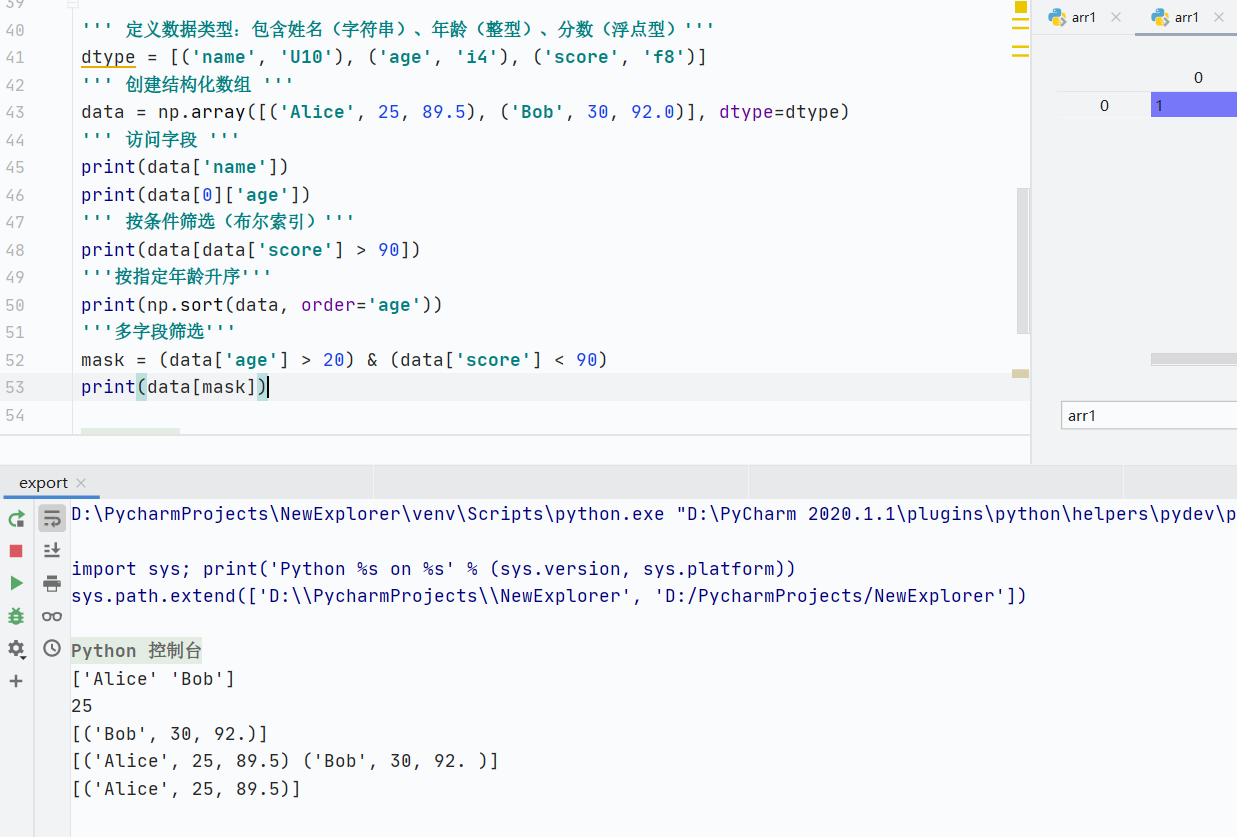
''' 定义数据类型:包含姓名(字符串)、年龄(整型)、分数(浮点型)'''
dtype = [('name', 'U10'), ('age', 'i4'), ('score', 'f8')]
''' 创建结构化数组 '''
data = np.array([('Alice', 25, 89.5), ('Bob', 30, 92.0)], dtype=dtype)
''' 访问字段 '''
print(data['name'])
print(data[0]['age'])
''' 按条件筛选(布尔索引)'''
print(data[data['score'] > 90])
'''按指定年龄升序'''
print(np.sort(data, order='age'))
'''多字段筛选'''
mask = (data['age'] > 20) & (data['score'] < 90)
print(data[mask])
性能优化
向量化操作 VS 循环
向量化的本质:将操作从“逐个处理元素”变为“批量处理整个数组”,底层通过优化的 C/Fortran 代码和 CPU 的 SIMD 指令(单指令多数据)并行计算。
-
向量化操作
利用numpy内置底层C/Fortran 实现的高效函数,直接对整个数组进行操作。 -
循环
通过 Python 层级的 for 循环逐个处理元素,效率极低
内存布局:C顺序 VS F顺序
-
C顺序
内存中相邻的行元素连续存储(如 arr[i, j] 和 arr[i, j+1] 相邻) -
F 顺序(列优先)
内存中相邻的列元素连续存储(如 arr[i, j] 和 arr[i+1, j] 相邻)
视图与副本
-
视图(View)
- 共享原始数组的数据内存,不复制数据
- 修改视图会影响原始数组
- 常见操作:切片,转置,重塑形状
-
副本(Copy)
- 完全独立的新数组,复制数据导新内存
- 修改副本不影响原始数组
- 常见操作:显示调用,高级索引等
输入输出
保存和加载数组;二进制格式(.npy,.npz)
-
np.save()保存;np.load()加载- 保存单个数组为
.npy二进制文件(保留形状和数据类型) - 加载时回复数组原装
- 保存单个数组为
-
np.savez()保存;np.load()加载- 保存多个数组导
.npz压缩文件(类似字典格式) - 可指定关键字命名数组
- 保存多个数组导
文本文件;不规则数据(如每行列数不同)则失败
-
np.loadtxt()读取文本文件常用参数:
delimiter:分隔符dtype:指定数据类型skiprows:跳过N行usecols:选择特定列
-
np.savetxt()写入文本文件常用参数:
fmt:格式字符串(如 '%.2f' 保留两位小数)header:文件头部注释
内存映射文件
用途:
- 处理超大型数组(无法一次性加载到内存)
- 多进程共享数据:不同进程可访问同一内存映射文件
import numpy as np
# 创建一个内存映射文件(如果文件不存在则初始化)
shape = (1000, 1000)
dtype = np.float32
filename = 'large_array.dat'
# 创建或加载内存映射
mmap_arr = np.memmap(filename, dtype=dtype, mode='w+', shape=shape)
# 写入数据(延迟到文件关闭或删除对象时同步)
mmap_arr[:10, :10] = np.random.rand(10, 10)
# 显式同步到磁盘(可选)
mmap_arr.flush()
# 重新以只读模式打开
mmap_readonly = np.memmap(filename, dtype=dtype, mode='r', shape=shape)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号