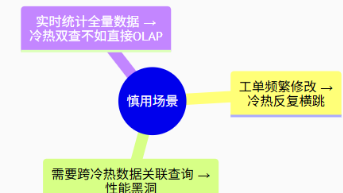
摘要: 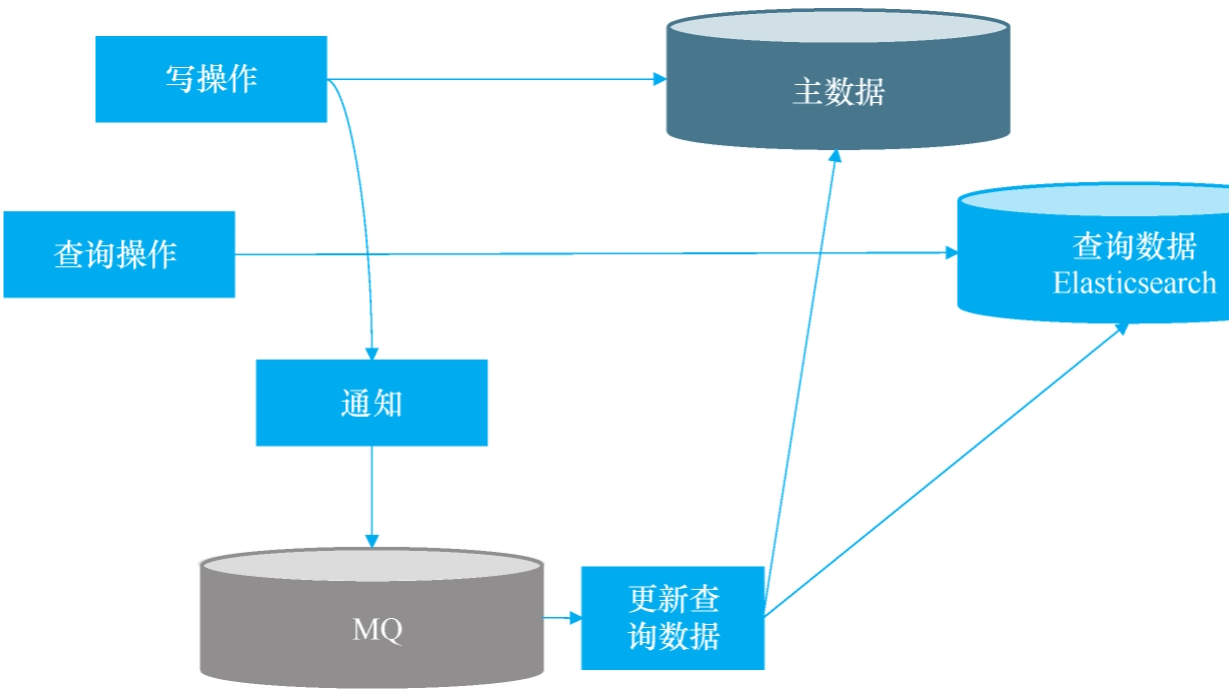 上一章中我们介绍到冷热分离,旨在快速交付。但是他仍存在一些问题,并不是完美的方案,比如限制了业务的操作,必须再特定的业务场景下(冷数据不允许修改、冷数据查询慢、不适合复杂查询)。本章将介绍新的方案,支持千万数据的快速查询。 阅读全文
上一章中我们介绍到冷热分离,旨在快速交付。但是他仍存在一些问题,并不是完美的方案,比如限制了业务的操作,必须再特定的业务场景下(冷数据不允许修改、冷数据查询慢、不适合复杂查询)。本章将介绍新的方案,支持千万数据的快速查询。 阅读全文
上一章中我们介绍到冷热分离,旨在快速交付。但是他仍存在一些问题,并不是完美的方案,比如限制了业务的操作,必须再特定的业务场景下(冷数据不允许修改、冷数据查询慢、不适合复杂查询)。本章将介绍新的方案,支持千万数据的快速查询。 阅读全文
posted @ 2025-10-29 11:45
yihuiComeOn
阅读(520)
评论(0)
推荐(1)
 大数据场景下的冷热数据分离实战 本文针对工单系统日均10万增长、数据量超1.5亿导致的性能问题,提出了冷热分离解决方案。核心痛点在于热数据(最近3个月)仅占极少比例却承担九成访问。通过分析数据库分区方案的缺陷,详细阐述了冷热分离实施策略:采用定时扫描触发迁移、批量处理与并发控制相结合、设计精妙的锁机制确保数据一致性,最终实现查询响应从2.1s降至0.2s。对于亿级冷数据,进一步介绍了迁移至HBase的优化方案,包括RowKey设计和存储架构。文章还总结了冷热分离的适用场景与实施原则,为高并发大数据系统
大数据场景下的冷热数据分离实战 本文针对工单系统日均10万增长、数据量超1.5亿导致的性能问题,提出了冷热分离解决方案。核心痛点在于热数据(最近3个月)仅占极少比例却承担九成访问。通过分析数据库分区方案的缺陷,详细阐述了冷热分离实施策略:采用定时扫描触发迁移、批量处理与并发控制相结合、设计精妙的锁机制确保数据一致性,最终实现查询响应从2.1s降至0.2s。对于亿级冷数据,进一步介绍了迁移至HBase的优化方案,包括RowKey设计和存储架构。文章还总结了冷热分离的适用场景与实施原则,为高并发大数据系统 ![[微服务进阶场景实战] - 如何处理好微服务之间千丝万缕的关系](https://img2024.cnblogs.com/blog/2428649/202601/2428649-20260106015512936-1613272495.png) 本文探讨了微服务架构中依赖关系复杂化的挑战及解决方案。通过分析商品、订单等核心服务的交互场景,揭示了聚合接口归属混乱和服务依赖网状化两大痛点。项目组引入API层和BFF模式进行架构优化:API层负责数据聚合与业务编排,BFF为不同客户端定制专属接口。技术实现采用Spring Cloud三层架构(网关、BFF、后台服务),并通过公共库、独立服务或容忍重复等策略解决代码复用问题。最终形成垂直领域团队与水平BFF团队的矩阵分工模式,在保持架构清晰的同时提升开发效率。该方案有效降低了微服务间的耦合度,为复杂业务系统
本文探讨了微服务架构中依赖关系复杂化的挑战及解决方案。通过分析商品、订单等核心服务的交互场景,揭示了聚合接口归属混乱和服务依赖网状化两大痛点。项目组引入API层和BFF模式进行架构优化:API层负责数据聚合与业务编排,BFF为不同客户端定制专属接口。技术实现采用Spring Cloud三层架构(网关、BFF、后台服务),并通过公共库、独立服务或容忍重复等策略解决代码复用问题。最终形成垂直领域团队与水平BFF团队的矩阵分工模式,在保持架构清晰的同时提升开发效率。该方案有效降低了微服务间的耦合度,为复杂业务系统 ![[微服务进阶场景实战] - “微服务数据依赖症”](https://img2024.cnblogs.com/blog/2428649/202601/2428649-20260105095759528-1147748526.png) 本文探讨了微服务架构中服务间数据依赖问题的解决方案。针对供应链系统中商品、订单、采购服务间的数据查询需求,传统跨服务调用方案存在性能低下、服务过载和依赖链雪崩三大问题。提出数据冗余方案,通过同步或异步方式更新冗余数据,但面临同步更新导致核心流程被绑架、消息异步更新带来订阅泛滥和逻辑重复等问题。最终采用基于Bifrost的数据同步方案,将商品主数据实时同步至下游服务数据库,实现业务逻辑解耦。该方案具有配置简单、维护成本低等优势,但需注意同步延迟、只读原则和监控等关键事项,避免在核心流程中依赖同步数据。
本文探讨了微服务架构中服务间数据依赖问题的解决方案。针对供应链系统中商品、订单、采购服务间的数据查询需求,传统跨服务调用方案存在性能低下、服务过载和依赖链雪崩三大问题。提出数据冗余方案,通过同步或异步方式更新冗余数据,但面临同步更新导致核心流程被绑架、消息异步更新带来订阅泛滥和逻辑重复等问题。最终采用基于Bifrost的数据同步方案,将商品主数据实时同步至下游服务数据库,实现业务逻辑解耦。该方案具有配置简单、维护成本低等优势,但需注意同步延迟、只读原则和监控等关键事项,避免在核心流程中依赖同步数据。 ![[微服务进阶场景实战] - 数据一致性](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251231172110600-959933332.png) 本文探讨了微服务架构中的数据一致性问题及解决方案。针对最终一致性场景,提出基于消息队列的异步补偿方案,通过消息持久化和重试机制确保数据最终一致;对于强一致性需求,对比分析了TCC模式与Seata AT模式,重点推荐Seata AT方案,其通过自动生成回滚日志实现低侵入式分布式事务管理。实践表明,这两种方案能有效解决数据不一致问题,且不会显著增加开发负担,为微服务架构提供了可靠的数据一致性保障。
本文探讨了微服务架构中的数据一致性问题及解决方案。针对最终一致性场景,提出基于消息队列的异步补偿方案,通过消息持久化和重试机制确保数据最终一致;对于强一致性需求,对比分析了TCC模式与Seata AT模式,重点推荐Seata AT方案,其通过自动生成回滚日志实现低侵入式分布式事务管理。实践表明,这两种方案能有效解决数据不一致问题,且不会显著增加开发负担,为微服务架构提供了可靠的数据一致性保障。 ![[微服务进阶场景实战] 微服务痛点 - 用实际经历告诉你它有多少陷阱](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251231105243692-1476815581.png) 本文深入探讨了微服务架构的核心概念与实践挑战。通过对比单体架构与微服务架构在新零售系统中的实现差异,揭示了微服务在精准扩展、独立发布、技术异构和持续优化等方面的优势。同时重点剖析了微服务落地的四大痛点:服务边界划分困难(受康威定律支配)、服务粒度失控、系统全貌难以掌握以及代码重复问题。文章指出微服务拆分本质上是一个需要平衡技术、业务和组织因素的持续治理过程,而非纯粹的技术决策。这些见解为后续微服务实战提供了重要的理论基础和风险预判。
本文深入探讨了微服务架构的核心概念与实践挑战。通过对比单体架构与微服务架构在新零售系统中的实现差异,揭示了微服务在精准扩展、独立发布、技术异构和持续优化等方面的优势。同时重点剖析了微服务落地的四大痛点:服务边界划分困难(受康威定律支配)、服务粒度失控、系统全貌难以掌握以及代码重复问题。文章指出微服务拆分本质上是一个需要平衡技术、业务和组织因素的持续治理过程,而非纯粹的技术决策。这些见解为后续微服务实战提供了重要的理论基础和风险预判。 ![[微服务场景实战] - 限流 - 如何让服务器在亿级流量冲击下“活下去”](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251230154314116-2147043778.png) 本文探讨了在高并发秒杀场景下的限流技术。首先分析了亿级流量冲击的业务场景,指出限流是保证系统存活的关键策略。接着详细介绍了四种限流算法:固定时间窗口计数算法存在边界临界问题;滑动时间窗口算法通过子窗口划分提高精度但仍面临机器人抢购问题;漏桶算法通过恒定速率处理请求但无法解决瞬时峰值;令牌桶算法通过控制令牌生成速率和桶容量,既能平滑流量又能增加真实用户成功率。最后重点推荐了令牌桶算法在秒杀场景下的优化实现方案,通过限制瞬时可用令牌数量来有效缓解流量洪峰。
本文探讨了在高并发秒杀场景下的限流技术。首先分析了亿级流量冲击的业务场景,指出限流是保证系统存活的关键策略。接着详细介绍了四种限流算法:固定时间窗口计数算法存在边界临界问题;滑动时间窗口算法通过子窗口划分提高精度但仍面临机器人抢购问题;漏桶算法通过恒定速率处理请求但无法解决瞬时峰值;令牌桶算法通过控制令牌生成速率和桶容量,既能平滑流量又能增加真实用户成功率。最后重点推荐了令牌桶算法在秒杀场景下的优化实现方案,通过限制瞬时可用令牌数量来有效缓解流量洪峰。 ![[从程序员到架构师] 微服务场景实战 - 熔断](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251230103458605-1828584522.png) 本文探讨了微服务系统中的熔断机制应用场景与解决方案。通过新零售系统中用户服务的两个核心接口案例,揭示了慢请求和流量洪峰如何引发系统级雪崩效应。针对线程隔离和快速失败恢复的需求,对比了Hystrix和Sentinel两种主流熔断框架的特性差异,最终选择Hystrix作为解决方案。文章强调熔断机制的核心在于 异常不访问 和 超时不硬等原则,并区分了熔断与限流的关键特征,为构建弹性微服务系统提供了实践指导。
本文探讨了微服务系统中的熔断机制应用场景与解决方案。通过新零售系统中用户服务的两个核心接口案例,揭示了慢请求和流量洪峰如何引发系统级雪崩效应。针对线程隔离和快速失败恢复的需求,对比了Hystrix和Sentinel两种主流熔断框架的特性差异,最终选择Hystrix作为解决方案。文章强调熔断机制的核心在于 异常不访问 和 超时不硬等原则,并区分了熔断与限流的关键特征,为构建弹性微服务系统提供了实践指导。 ![[从程序员到架构师] 微服务场景实战 - 全链路日志](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251229110947470-468785729.png) 本文探讨了微服务架构下全链路日志管理的挑战与解决方案。通过真实案例揭示了传统日志方式的不足,提出采用OpenTracing标准实现日志串联,并选择SkyWalking作为技术方案。文章详细分析了技术选型标准,包括数据结构支持、存储系统适配、性能影响控制等核心考量,最终推荐SkyWalking作为兼顾性能与功能的优选方案。同时强调了异步日志收集机制的重要性,避免业务系统与日志系统的强耦合。该方案能有效提升故障排查效率,为微服务系统提供完整的调用链追踪能力。
本文探讨了微服务架构下全链路日志管理的挑战与解决方案。通过真实案例揭示了传统日志方式的不足,提出采用OpenTracing标准实现日志串联,并选择SkyWalking作为技术方案。文章详细分析了技术选型标准,包括数据结构支持、存储系统适配、性能影响控制等核心考量,最终推荐SkyWalking作为兼顾性能与功能的优选方案。同时强调了异步日志收集机制的重要性,避免业务系统与日志系统的强耦合。该方案能有效提升故障排查效率,为微服务系统提供完整的调用链追踪能力。 ![[从程序员到架构师] 微服务场景实战 - 注册发现](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251226211113233-1714412455.png) 各位,咱们继续盘微服务这个“硬核玩具”。上回说到要从接地气的场景开始,今天这个场景,那可太“接地气”了——接地气到让人脚趾抠地。业务场景:如何对几十个后台服务进行高效管理
**给50个“娃”当保姆是种什么体验? **想象一下,你手底下有50多个后台服务,个个都是亲生的(Java、Go、Node.js 什么语言都有)。它们关系复杂,互相调用,活像一个大型幼儿园。这时候,Spring Cloud、Dubbo 这些“名牌家教”只教 Java 娃,其他娃咋办?
各位,咱们继续盘微服务这个“硬核玩具”。上回说到要从接地气的场景开始,今天这个场景,那可太“接地气”了——接地气到让人脚趾抠地。业务场景:如何对几十个后台服务进行高效管理
**给50个“娃”当保姆是种什么体验? **想象一下,你手底下有50多个后台服务,个个都是亲生的(Java、Go、Node.js 什么语言都有)。它们关系复杂,互相调用,活像一个大型幼儿园。这时候,Spring Cloud、Dubbo 这些“名牌家教”只教 Java 娃,其他娃咋办?  之前的文章中我们已经演练了缓存的三种“招式”:用读缓存化解数据库查询压力,靠写缓存扛住流量洪峰,再通过消息队列从容同步数据。这套组合拳——先缓冲、再异步、平稳落库——正是接下来面对真刀真枪的秒杀场景时,我们要继续运用的核心战术。
之前的文章中我们已经演练了缓存的三种“招式”:用读缓存化解数据库查询压力,靠写缓存扛住流量洪峰,再通过消息队列从容同步数据。这套组合拳——先缓冲、再异步、平稳落库——正是接下来面对真刀真枪的秒杀场景时,我们要继续运用的核心战术。 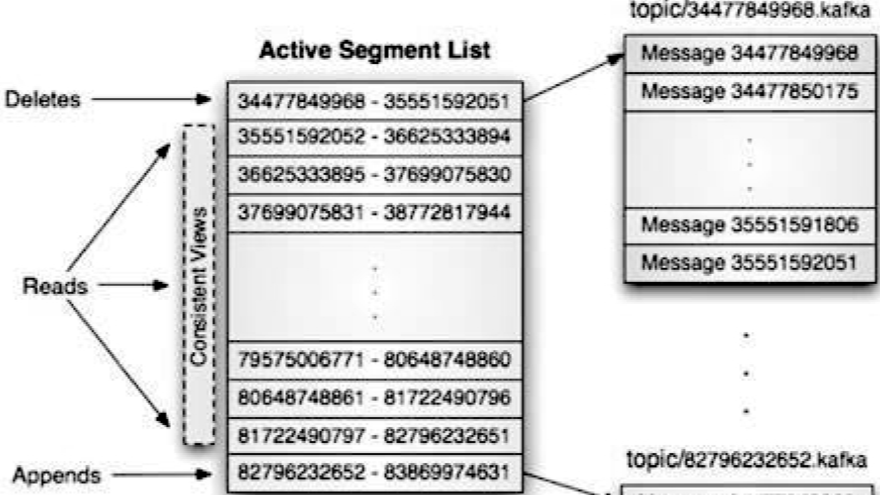 上一章咱们给数据库装了个“写缓存”,相当于在市中心车库外建了个临时停车场。确实,车流(写操作)不堵门了。但问题是——这停车场是露天的,且只有三个车位。一旦遇上“双十一”式的高频数据洪流(想象一群饿疯了的吃货同时涌向自助餐厅),这方案立刻露出短板:缓存写满的速度比手机掉电还快,数据要么排队等到天荒地老,要么面临丢失风险。显然,临时方案扛不住持久战。接下来咱们关掉美颜,直面痛点,一步步拆解如何为持续的高频写入设计一个既扛得住、又稳得起的系统方案。道路就在前方,咱们开始铺路。
上一章咱们给数据库装了个“写缓存”,相当于在市中心车库外建了个临时停车场。确实,车流(写操作)不堵门了。但问题是——这停车场是露天的,且只有三个车位。一旦遇上“双十一”式的高频数据洪流(想象一群饿疯了的吃货同时涌向自助餐厅),这方案立刻露出短板:缓存写满的速度比手机掉电还快,数据要么排队等到天荒地老,要么面临丢失风险。显然,临时方案扛不住持久战。接下来咱们关掉美颜,直面痛点,一步步拆解如何为持续的高频写入设计一个既扛得住、又稳得起的系统方案。道路就在前方,咱们开始铺路。  浙公网安备 33010602011771号
浙公网安备 33010602011771号