论文信息
论文标题:Cooperative Classification and Rationalization for Graph Generalization
论文作者:岳临安、刘琪、刘烨、高伟博、姚方舟、李文峰
论文来源:WWW 2024
发布时间:2024
论文地址:link
论文代码:link
-
研究背景与问题:图神经网络(GNNs)在图分类任务中表现优异,但面对分布外(OOD)数据时泛化能力不足。现有解决思路存在缺陷:一是通过修改数据环境丰富普通分类的训练分布,但获取环境信息难度大;二是通过 “合理化” 提取预测所需的不变理据,但因学习信号有限,理据提取准确性低、预测效果受影响。
-
提出方法:设计协同分类与合理化(C2R)方法,包含分类模块与合理化模块,二者协同工作。
-
分类模块:假设存在多个环境,借助环境条件生成网络引入多样化训练分布,得到稳健的图表示。
-
合理化模块:用分离器识别相关理据子图,使剩余非理据子图与标签去相关;再通过知识蒸馏方法,将分类模块的图表示与理据子图表示对齐,增强理据的学习信号。
-
协同机制:收集非理据表示推断多个环境,将其整合到分类模块中实现协同学习。
-
实验与成果:在基准数据集和合成数据集上的大量实验证明了 C2R 方法的有效性,相关代码已公开(可通过文中链接获取)
2 研究动机&&研究问题
图神经网络(GNNs)在各类图分类任务(如分子性质预测、 motif 类型识别)中已取得显著成果,但现实场景中训练集与测试集的分布往往存在差异,导致 GNNs 面对分布外(OOD)数据时泛化能力严重下降 —— 这一问题的本质是传统 GNN 依赖训练数据中的统计关联(甚至虚假关联),而非与任务核心相关的不变特征。
现有两类主流方法均无法同时解决 “OOD 泛化” 与 “学习信号不足” 的核心矛盾:
为解决上述两类方法的局限,提出协同分类与合理化(C2R)框架:
-
通过分类模块生成鲁棒图表示,为合理化模块提供额外学习信号,减少理据探索空间;
-
通过合理化模块挖掘非理据子图的环境信息,反馈给分类模块以优化训练分布;
-
最终实现 “分类鲁棒性” 与 “理据准确性” 的双向促进,提升 GNN 在 OOD 数据上的泛化能力。
如何设计一种协同框架,同时解决 “环境信息获取难” 与 “理据学习信号不足” 两大问题,实现 GNN 在 OOD 数据上的高效泛化与可解释性?
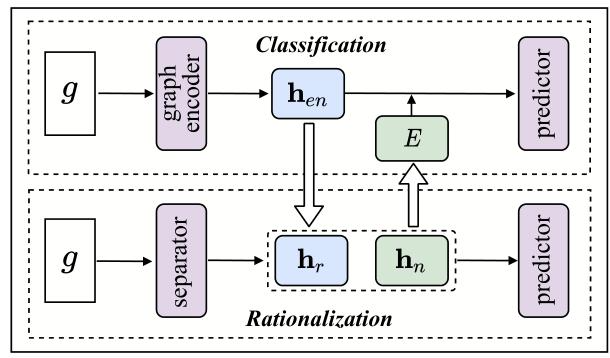
设计分类模块与合理化模块的协同架构,实现两者双向赋能,最终提升模型在分布外(OOD)数据上的泛化能力与可解释性。
-
分类模块:假设存在多环境,通过生成反事实样本学习跨环境的鲁棒图表示;
-
合理化模块:将图划分为理据子图(与标签相关)和非理据子图(与标签解耦),并利用分类模块的鲁棒表示优化理据提取;
-
协同闭环:通过非理据子图推断全局环境,反馈给下一轮分类模块,形成 “分类鲁棒表示→合理化理据优化→环境推断→分类模块迭代” 的协同训练流程。
通过环境条件生成反事实样本,丰富训练分布,学习不依赖特定环境的鲁棒图表示,同时为合理化模块提供知识蒸馏信号。
将输入图转换为节点级表示和图级表示,为后续反事实生成和预测提供基础特征。
采用任意 GNN 结构(如 GIN、GCN)作为编码器,公式如下:
$H_{en} = GNN_{en}(g), \quad h_{en} = READOUT(H_{en})$
-
符号说明:
-
$g$:输入图(含节点集 $V$ 和边集 $E$);
-
$GNN_{en}(\cdot)$ :图编码器(可替换为任意 GNN 架构);
-
$H_{en} \in \mathbb{R}^{|V| \times d}$ :节点级表示( $|V|$ 为节点数,d 为特征维度);
-
$READOUT(\cdot)$ :图级表示聚合操作(本文采用均值池化);
-
$h_{en} \in \mathbb{R}^{d}$ :最终输出的鲁棒图表示。
基于现有环境,将原始图表示映射到其他环境,生成反事实样本,以丰富训练分布的多样性。
-
每个样本关联一个特定环境 $e_m \in E$ ( $E = \{e_1, e_2, ..., e_k\}$ 为环境集合);
-
环境不影响任务标签(反事实样本标签与原始样本一致)。
-
环境采样:对每个样本,从环境集合中随机采样不同于当前环境的目标环境 $e_j$ ( $e_j \neq e_m$ );
-
反事实表示生成:通过生成器 $EG(\cdot)$ 将原始图表示 $h_{en}$ 映射到目标环境,公式如下:
$h_{en}^j = EG(h_{en}, e_j)$
-
目的:保证环境映射的有效性,确保反事实样本可还原为原始表示,避免生成无关特征;
-
数学定义:
$\mathcal{L}_{cycle} = I\left(EG(h_{en}^j, e_m) ; h_{en}\right)$
-
符号说明: $I(\cdot;\cdot)$ 为互信息,最大化该值可保证 $EG(h_{en}^j, e_m)$ 与 $h_{en}$ 编码相同核心信息;
-
作用:约束生成器在环境转换中保留图的任务相关特征,仅改变环境相关噪声。
基于原始图表示和反事实图表示共同预测任务结果,迫使模型学习跨环境的通用特征。
-
原始样本预测: $\hat{y}_{en} = \Phi(h_{en})$ ,损失函数为:
$\mathcal{L}_{ori} = \mathbb{E}_{(g,y) \sim \mathcal{D}_G} \left[ \ell(\hat{y}_{en}, y) \right]$
-
反事实样本预测: $\hat{y}_e^j = \Phi(h_{en}^j)$ ,损失函数为:
$\mathcal{L}_{cou} = \mathbb{E}_{(g,y) \sim \mathcal{D}_G} \left[ \ell(\hat{y}_e^j, y) \right]$
精准提取与任务标签相关的理据子图,同时通过非理据子图推断全局环境,反馈给分类模块,实现协同优化。
将输入图划分为 “理据子图”(与标签强相关,决定预测结果)和 “非理据子图”(与标签解耦,对应环境噪声),并生成对应的表示。
-
理据概率预测:
-
通过编码器 $GNN_m(\cdot)$ 将节点转换为特征向量,再通过权重矩阵 $W_m$ 输出每个节点作为理据的概率分布:
$\tilde{M} = softmax\left(W_m(GNN_m(g))\right)$
-
符号说明: $\tilde{M} = \{\tilde{m}_i\}_{i}^{|V|}$ ( $\tilde{m}_i \in [0,1]$ 为第 i 个节点的理据概率), $W_m \in \mathbb{R}^{2 \times d}$ 为可学习权重矩阵。
-
可微掩码采样:
-
子图表示生成:
-
用额外编码器 $GNN_g(\cdot)$ 生成图的节点表示 $H_g$ ;
-
理据 / 非理据子图表示通过掩码与节点表示的元素积,再经 READOUT 聚合得到:
$h_r = READOUT(M \odot H_g), \quad h_n = READOUT((1-M) \odot H_g)$
-
符号说明:
仅基于理据子图表示进行任务预测,确保模型依赖核心特征而非环境噪声,同时保证与分类模块的参数共享。
$\hat{y}_r = \Phi(h_r), \quad \mathcal{L}_r = \mathbb{E}_{(g,y) \sim \mathcal{D}_G} \left[ \ell(\hat{y}_r, y) \right]$
合理化模块的理据学习信号仅来自 “预测结果与真实标签的对比”,探索空间极大,难以收敛到最优理据。
将分类模块学习的鲁棒图表示 $h_{en}$ 迁移到理据表示 $h_r$ ,为理据学习提供额外信号,缩小探索空间。
通过最大化 $h_r$ 与 $h_{en}$ 的互信息实现表示对齐:
$\mathcal{L}_{dis} = I(h_r ; h_{en})$
非理据子图捕捉了不同分布下的变异特征,是环境的判别性指标,可通过非理据表示推断全局环境。
-
收集所有样本的非理据子图表示 $h_n$ ;
-
采用 k-means 聚类算法对 $h_n$ 聚类,得到环境集合:
$E = k\text{-means}(h_n)$
-
将推断的环境反馈给下一轮分类模块,为反事实样本生成提供环境输入,完成协同闭环。
-
设定超参数( $\lambda_{cou}, \lambda_{cycle}, \lambda_{sp}, \lambda_{dis}$ 等);
-
初始化分类模块、合理化模块的网络参数(预测器参数共享)。
-
运行分离器,生成掩码 M、理据表示 $h_r$ 和非理据表示 $h_n$ ;
-
基于 $h_r$ 计算预测损失 $\mathcal{L}_r$ ;
-
收集所有样本的 $h_n$ ,通过 k-means 聚类推断初始环境 E。
-
融合分类模块与合理化模块的所有损失(含稀疏性约束损失 $\mathcal{L}_{sp}$ 和知识蒸馏损失 $\mathcal{L}_{dis}$ );
-
整体损失函数:
$\mathcal{L} = \underbrace{\mathcal{L}_{ori} + \lambda_{cou}\mathcal{L}_{cou} - \lambda_{cycle}\mathcal{L}_{cycle}}_{\text{分类模块损失}} + \underbrace{\mathcal{L}_r + \lambda_{sp}\mathcal{L}_{sp} - \lambda_{dis}\mathcal{L}_{dis}}_{\text{合理化模块损失}}$
-
反向传播更新所有网络参数。
-
每轮训练结束后,重新通过环境归纳器更新环境 E;
-
重复步骤 2-4,直至模型收敛。
推理阶段优先使用合理化模块的输出,兼顾预测性能与可解释性(理据子图可作为预测依据)。
-
输入测试图 $g_{test}$ ;
-
运行合理化模块的分离器,生成掩码 $M_{test}$ 和理据子图表示 $h_{r, test}$ ;
-
调用共享预测器 $\Phi(\cdot)$ ,基于 $h_{r, test}$ 输出最终预测结果 $\hat{y}_{test}$ ;
-
(可选)输出掩码 $M_{test}$ 对应的理据子图,提供预测可解释性。
围绕 5 个研究问题(RQ1-RQ5)验证所提 C2R 方法的有效性,具体目标如下:
-
C2R w/o cycle:移除分类模块的循环一致性约束(\(\mathcal{L}_{cycle}\));
-
C2R w/o cou:移除分类模块的反事实样本(不计算 \(\mathcal{L}_{cou}\));
-
C2R w/o dis:移除跨模块的知识蒸馏(不计算 \(\mathcal{L}_{dis}\))。
-
预测性能:Spurious-Motif/MNIST-75sp 用准确率(ACC);OGB-Mol 系列用 AUC;
-
理据提取精度:Precision@5(Spurious-Motif 数据集,因含真实理据)—— 衡量 Top-5 提取理据与真实理据的匹配度;
-
实验重复:5 次随机种子训练,报告测试集的均值 ± 标准差(取验证集性能最优 epoch 的结果);
-
硬件环境:单张 A100 GPU。
-
传统 GNN 因依赖训练数据的统计关联,在 OOD 数据上性能较差,验证了 OOD 泛化研究的必要性;
-
现有合理化方法因理据学习信号不足,性能不及 C2R;
-
C2R 通过分类与合理化的协同训练,既提升了 OOD 预测性能,又保证了理据提取的准确性。
在 OGB 数据集上,对比 C2R 与 3 个消融变体的 AUC 性能,验证核心组件的必要性。
分类模块的循环一致性约束、反事实样本,以及跨模块的知识蒸馏,均为 C2R 的关键组件,缺一不可。
-
实验设置:在 Spurious-Motif(bias=0.9)和 MolSIDER 上,测试 k=3,5,10,20,30 时的性能。
-
实验结果(图 5):
-
结论:环境数量需适配数据集特性,并非越多越好,需与数据的真实环境复杂度匹配。
-
实验设置:对比 3 种对齐方法 —— 互信息(MI)最大化(C2R)、KL 散度最小化(C2R-KL)、MSE 最小化(C2R-MSE)。
-
实验结果(图 4):C2R(MI 最大化)在所有 OGB 数据集上的 AUC 均高于 C2R-KL 和 C2R-MSE。
-
结论:互信息最大化能更有效地对齐鲁棒表示与理据表示,传递泛化能力。
在 MolSIDER 数据集上,记录 C2R 的分类模块、合理化模块,以及单独训练的 “纯分类模块”“纯合理化模块” 的 AUC 随训练 epoch 的变化(图 6)。
-
训练全程:C2R 的分类模块和合理化模块的 AUC 均高于单独训练的模块;
-
初始阶段:分类模块 AUC 高于合理化模块(因合理化模块初期理据提取不充分);
-
后期阶段:两者 AUC 差距缩小(协同训练使理据提取精度提升,合理化模块性能追赶)。
分类与合理化模块的协同训练策略有效,能实现双向赋能,提升整体性能。
将 C2R 的合理化模块替换为现有主流合理化方法(DIR、DisC、GREA、GSAT、DARE),形成 “方法 + C2R” 混合框架,在 OGB 数据集上对比原始方法与混合框架的性能。
C2R 框架具有良好的扩展性,可作为现有合理化方法的增强模块,提升其 OOD 泛化能力。
在 Spurious-Motif(bias=0.9)上训练 C2R(GIN 为骨干),对测试集中的 Cycle-Wheel、House-Tree、Crane-Ladder 三类图,可视化提取的理据子图(图 7)。
C2R 能准确提取与任务相关的核心理据子图,为预测结果提供可解释性,验证了合理化模块的有效性。
-
C2R 在合成与真实数据集上均实现了最优的 OOD 泛化性能,解决了传统 GNN 和现有合理化方法的核心局限;
-
分类模块的反事实样本生成、循环一致性约束,以及跨模块的知识蒸馏,是 C2R 性能优越的关键;
-
协同训练策略实现了分类与合理化模块的双向赋能,框架扩展性强;
-
C2R 能精准提取核心理据子图,兼具泛化性与可解释性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号