爬取思路: 爬取网页数据首先需要请求网站响应,需要安装requests库,读取网页内容需要安装xml库,调用xml库中的etree模块来处理Xml和Html数据,再使用Xpath解析数据.
掌握 XPath 后,你可以高效地从网页或 XML 数据中提取所需信息,是爬虫开发和数据处理的必备技能。
需要学习和安装的库和框架也比较多,一个个的学,做案例积累经验:
pip install requests lxml beautifulsoup4 selenium pandas matplotlib fake_useragent tqdm openpyxl
初识爬虫
1.requests请求库模块
Pycharm终端安装requests请求库
①.导入requests请求库
②.定义个变量要抓取的页面:
③.构造请求头(伪装身份user-agent)
打开要抓取的网址,快捷键:F12→Network(网络)→Name(名称)→点一个文件→Header(标头)→user-agent(拉到底部就会看到)

#伪装成浏览器的身份进行抓取
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
④.发起请求并接收响应对象
response = requests.get(url = url, headers = headers)
encoding = 'utf-8'
bd_url = 'https://www.baidu.com/' # 定义要请求的url数据包
response = requests.get(url=bd_url) # 发起请求并且接收响应对象
response.encoding = 'utf-8' # 设置编码格式
print(response) # <Response [200]> 响应对象
print(response.text) # 获取文本内容
print(response.content) # 获取到进制格式的数据
print(response.headers) # 获取响应头信息
print(response.request.headers) # 获取请求头信息
print(response.status_code) # 获取状态码
print(response.encoding) # 获取当前编码格式
print(response.url) # 获取到当前请求的url
print(response.cookies) # 获取到用户身份对象
print(response.content.decode()) # .decode() 默认utf-8 进行解码 如果需要使用其他编码进行解码 传参即可
⑤.保存文件然后读取
#完整示例-爬图
import requests
url = 'https://pic.netbian.com/uploads/allimg/240924/081942-17271371826661.jpg'
response = requests.get(url=url)
# print(response.content)
with open('王楚然.jpg', 'wb') as f:
f.write(response.content)
#完整示例-爬音频
import requests
url = 'https://m701.music.126.net/20240924221116/8ec6067b2ae956d58df4deff0bdddaf9/jdyyaac/obj/w5rDlsOJwrLDjj7CmsOj/31433228192/7100/62f1/fd29/3833d333ff983ce8eebe35872a9484ee.m4a'
response = requests.get(url=url)
with open('大人中.mp3', 'wb') as f:
f.write(response.content)
#爬视频
import requests
cookies = {
'PEAR_UUID': '7b913605-1037-4a28-b16a-46e7657e6f03',
'Hm_lvt_9707bc8d5f6bba210e7218b8496f076a': '1727185861',
'HMACCOUNT': '33EE743B756BCDEE',
'Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a': '1727185870',
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
# 'cookie': 'PEAR_UUID=7b913605-1037-4a28-b16a-46e7657e6f03; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1727185861; HMACCOUNT=33EE743B756BCDEE; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1727185870',
'pragma': 'no-cache',
'priority': 'i',
'range': 'bytes=0-',
'referer': 'https://www.pearvideo.com/',
'sec-ch-ua': '"Google Chrome";v="129", "Not=A?Brand";v="8", "Chromium";v="129"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'video',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
response = requests.get(
'https://video.pearvideo.com/mp4/short/20171004/cont-1165391-10964201-hd.mp4',
cookies=cookies,
headers=headers,
)
print(response.content)
with open('1.mp4', 'wb') as f:
f.write(response.content)
Pycharm内置模块方法(不推荐使用)
from urllib.request import urlopen
url ='url'#要爬取的数据网页
html = urlopen(url)
#print(html.read().decode('utf-8'))
with open("爬取的文件.html", "w",encoding="utf-8") as f:
write = f.write(html.read().decode('utf-8'))
★用input方法的get请求
import requests
from urllib.parse import quote
import time
try:
# 获取用户输入并进行URL编码
content = input("请输入你要查询的内容:")
encoded_content = quote(content)
# 构建请求URL
url = f"https://www.sogou.com/web?query={encoded_content}"
# 设置请求头模拟浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36"
}
# 发送HTTP请求
print(f"正在请求: {url}")
resp = requests.get(url, headers=headers, timeout=10) # 设置超时时间
# 检查响应状态码
resp.raise_for_status() # 若状态码非200,抛出HTTPError
# 保存响应内容到文件
filename = f"爬取的{content[:10]}内容.html" # 文件名包含部分查询内容
with open(filename, "w", encoding="utf-8") as f:
f.write(resp.text) # 直接使用resp.text
print(f"✅ 文件已成功保存为: {filename}")
print(f"状态码: {resp.status_code}")
except requests.exceptions.HTTPError as e:
print(f"HTTP请求错误: {e}")
except requests.exceptions.Timeout:
print("请求超时,请重试")
except requests.exceptions.RequestException as e:
print(f"网络请求异常: {e}")
except Exception as e:
print(f"发生未知错误: {e}")
finally:
# 控制请求频率
time.sleep(1) # 等待1秒后结束程序
★用input方法的post请求
import requests
from urllib.parse import urlencode
import time
import json
try:
# 获取用户输入
keyword = input("请输入你要翻译的内容:")
# 百度翻译API的POST接口
url = "https://fanyi.baidu.com/sug"
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
# 构建POST请求的表单数据(百度翻译API需要的参数)
data = {
"kw": keyword # 百度翻译API使用'kw'参数传递要翻译的内容
}
# 发送POST请求
print(f"正在请求: {url}")
resp = requests.post(url, headers=headers, data=data, timeout=10) #发送post请求时,传参数用的是data.
# 检查响应状态码
resp.raise_for_status()
# 解析JSON响应
result = resp.json()
# 保存响应内容到文件
filename = f"翻译结果_{keyword[:10]}.json"
with open(filename, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"✅ 翻译结果已保存为: {filename}")
print(f"状态码: {resp.status_code}")
# 简单打印翻译结果
if result.get('errno') == 0 and 'data' in result:
print("\n翻译结果预览:")
for item in result['data'][:3]: # 只显示前3个结果
print(f"{item.get('k', '')} -> {item.get('v', '')}")
except requests.exceptions.HTTPError as e:
print(f"HTTP请求错误: {e}")
except requests.exceptions.Timeout:
print("请求超时,请重试")
except requests.exceptions.RequestException as e:
print(f"网络请求异常: {e}")
except json.JSONDecodeError:
print("无法解析JSON响应,可能是请求格式不正确")
except Exception as e:
print(f"发生未知错误: {e}")
finally:
# 控制请求频率
time.sleep(1)
参数请求与Cookie



import requests
url = "https://movie.douban.com/j/chart/top_list" #问号后面的参数可以用字典的形式传参数
data = {
"type":"13",
"interval_id":"100:90",
"action": "",
"start":"0",
"limit":"20"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
response = requests.get(url, params=data, headers=headers)#发送get请求时,传参数用的是params
print(response.json())
2.xpath数据解析(XML Path Language):是一种用于在 XML 或 HTML 文档中定位节点的查询语言和选择特定元素的表达式语言。它就像是一个路径导航系统,能帮助开发者快速准确地找到文档中的特定节点或节点集合。在网页数据抓取、XML 处理等场景中广泛应用。
- 数据提取:在网页爬虫中,当需要从复杂的 HTML 页面结构中提取特定信息,如标题、正文、链接等时,XPath 可以精确定位到包含这些信息的 HTML 元素,然后方便地提取出所需数据。
- 元素定位:在自动化测试中,需要操作网页上的各种元素,如点击按钮、填写表单等。XPath 可以帮助找到这些元素在页面中的位置,从而实现对它们的操作。
在编程语言中使用 XPath
pycharm终端安装lxml库:
pip install lxml
#或使用镜像下载安装
pip install lxml -i 镜像地址
pycharm终端查看当前环境下安装了哪些库
-
- 解析 XML/HTML 文档:可以从字符串、文件或 URL 加载 XML/HTML 内容。
- 构建文档:支持动态创建 XML/HTML 结构。
- 元素操作:提供简洁的 API 来遍历、修改和查询文档节点。
- XPath 支持:通过 XPath 表达式高效定位特定元素。
①.解析 XML 文档
2.2.etree.fromstring():可以将 XML/HTML 格式的字符串解析为树形结构(ElementTree 对象),以便于后续的遍历、查询和修改。
from lxml import etree
xml_str = '<book><title>Python编程</title><price>99.0</price></book>'
root = etree.fromstring(xml_str)
# 获取根节点标签
print(root.tag) # 输出: book
# 查找子节点
title = root.find('title').text
price = root.find('price').text
print(f"书名: {title}, 价格: {price}") # 输出: 书名: Python编程, 价格: 99.0
②.遍历元素
# 遍历所有子元素
for child in root:
print(child.tag, child.text) # 输出: element 内容
# 使用XPath查找元素
elements = root.xpath('//element')
# 创建新元素
new_element = etree.Element('new_element')
new_element.text = '新内容'
# 添加到根节点
root.append(new_element)
# 修改现有元素
root.find('element').text = '更新后的内容'
# 删除元素
root.remove(new_element)
④.输出文档
# 转换为字符串
xml_output = etree.tostring(root, pretty_print=True, encoding='unicode')
print(xml_output)
# 写入文件
# etree.ElementTree(root).write('output.xml', pretty_print=True)
from lxml import etree
#如果Pycharm报错可以考虑下面这种导入方式
from lxml imprt html
etree=html.etree
html = '<html><body><div class="content"><h1>Hello</h1></div></body></html>' tree = etree.HTML(html) # 选择所有<h1>元素的文本 titles = tree.xpath('//h1/text()') print(titles) # 输出: ['Hello'] # 选择class为"content"的<div>元素 divs = tree.xpath('//div[@class="content"]')
打开抓取的html文档然后读取
with open('抓取的文档.html', 'r', encoding='utf-8') as f:
html = f.read() # 读取
# print(html) # 读取出来的文本内容
# print(type(html)) # <class 'str'>查看类开,字符串类型
tree = etree.HTML(html) # 渲染html
// 选择第一个<h1>元素
const h1 = document.evaluate('//h1', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
// 选择所有<a>元素的href属性
const links = document.evaluate('//a/@href', document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
for (let i = 0; i < links.snapshotLength; i++) {
console.log(links.snapshotItem(i).value);
}
①.基本路径表达式
xpath 通过路径表达式从根节点(/)或当前节点(.)开始定位元素:
xpath方法返回值是列表 xpath语法规定索引值从1开始
xpath('/html/body/div/h1/') # 选择HTML文档中的<h1>元素
xpath('/html/body/div/h1/text()') # 选择HTML文档中的<h1>元素的数据
- 相对路径:从当前节点开始,使用
// 表示任意层级的子节点。
xpath('//div/p') # 选择所有<div>下的<p>元素(不限层级)
| 符号 |
作用 |
| // |
从任意位置开始选择节点。 |
| . |
选择当前节点。 |
| .. |
选择当前节点的父节点。 |
| @ |
选择属性。 |
| * |
通配符,匹配任意节点或属性 |
| [ ] |
条件表达式,用于筛选节点。 |
| position |
当前节点的位置(如 [1] 表示第一个匹配的节点)。 |
③.常用函数
xpath('//div[text()="Hello World"]') # 选择文本内容为"Hello World"的<div>
xpath('//div[contains(text(), "World")]') # 选择包含"World"的<div>
属性匹配:
xpath('//a[@href="https://example.com"]') # 选择href属性为指定值的<a>标签
xpath('//input[@type="text"]') # 选择包含"World"的<div>
位置筛选:
xpath('//li[position()=1]') # 选择第一个<li>
xpath('//li[last()]') # 选择最后一个<li>.<li>
使用 and、or、not() 组合条件:
xpath('//div[@class="container" and @id="main"]') # 同时满足两个属性条件
xpath('//div[@class="item" or @class="product"] ') # 满足任一属性条件
xpath('//div[not(@class="ignore")]') # 排除特定属性的<div>
轴用于选择当前节点的相关节点(如父节点、兄弟节点等):
| 轴名称 |
作用 |
示例 |
| parent:: |
父节点 |
xpath('//h1/parent::div') |
| child:: |
子节点(默认) |
xpath('//div/child::p') |
| descendant |
所有后代节点(不限层级) |
xpath('//div/descendant::span') |
| ancestor:: |
所有祖先节点(包括父节点的父节点) |
xpath('//p/ancestor::body') |
| following-sibling:: |
后续兄弟节点 |
xpath('//li[1]/following-sibling::li') |
| preceding-sibling: |
前续兄弟节点 |
xpath('//li[3]/preceding-sibling::li') |
案例:
# 导入所需库
import requests # 用于发送HTTP请求,获取网页内容
from lxml import etree # 用于解析HTML文档,提取需要的信息
# 定义基本参数
# 目标网页URL(小说章节页面)
url = 'https://www.xs386.com/6661/32866513.html'
# 请求头信息,模拟浏览器访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
} # user-agent用于告诉服务器访问者的浏览器信息,避免被服务器识别为爬虫而拒绝访问。
# 发送GET请求获取网页内容
response = requests.get(url=url, headers=headers)
# 设置正确的编码,设置编码为utf-8,确保中文显示正常
response.encoding = 'utf-8'
# 将HTML文本解析为可操作的元素树对象
e = etree.HTML(response.text) # 将网页源代码转换为解析树,便于后续提取数据
# 使用XPath表达式提取id为"content"的div内的所有文本,注意返回的是列表
content_list = e.xpath('//div[@id="content"]//text()') # 查找整个文档中 id 属性为 "content" 的 div 元素并提取该 div 下所有层级的文本内容
# 判断是否成功提取到内容
if content_list:
# 将列表内容合并为字符串
content = '\n'.join(content_list)
# 清理内容中的多余空格和换行
content = content.strip()
# 保存到文件(使用utf-8编码)
with open('上门龙婿.txt', 'w', encoding='utf-8') as f:
f.write(content)
print("内容保存成功")
else:
print("未找到指定内容")
3.JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,以易于人阅读和编写的文本格式存储和表示数据,同时也易于机器解析和生成,在前后端数据交互、配置文件等场景中被广泛使用。
- 轻量级:相比 XML 等格式,JSON 的数据结构更简洁,文件体积更小,传输效率更高。
- 跨语言兼容:几乎所有编程语言都支持 JSON 的解析和生成,便于不同系统间的数据交互。
- 可读性强:采用键值对(key-value)结构,格式清晰,易于理解和维护。
- 结构灵活:支持嵌套对象和数组,能表示复杂的数据结构。
数据类型与表示
- 对象(Object):用
{}包裹,由键值对组成,键和值用:分隔,多个键值对用,分隔。
- 数组(Array):用
[]包裹,元素可以是任意数据类型,元素间用,分隔。
- 键值对:键必须是字符串,值可以是字符串、数字、布尔值、null、对象或数组。
{
"id": 1001,
"hobbies": ["阅读", "编程"],
"isStudent": false,
"address": null
}
格式要求
- 键名必须用双引号
""包裹(部分语言支持单引号,但标准 JSON 要求双引号)。
- 逗号分隔时,最后一个键值对后不能有多余的逗号(部分环境支持,但可能导致兼容性问题)。
- 起源:JSON 最初是 JavaScript 的子集,但现在已独立为跨语言的标准格式。
- 在 JavaScript 中的使用:
- 可以直接通过
JSON.parse()将 JSON 字符串转换为 JavaScript 对象。
- 通过
JSON.stringify()将 JavaScript 对象转换为 JSON 字符串。
// 示例:JSON与JavaScript对象的转换
const jsonStr = '{"name":"张三","age":25}';
const obj = JSON.parse(jsonStr); // 转换为对象
console.log(obj.name); // 输出:张三
const data = { city: "北京", population: 2100 };
const jsonData = JSON.stringify(data); // 转换为JSON字符串
console.log(jsonData); // 输出:{"city":"北京","population":2100}
- 前后端数据交互:Web 应用中,前端通过 API 请求从服务器获取 JSON 数据,或向服务器发送 JSON 格式的请求参数。
- 配置文件:如项目配置文件(
package.json)、系统配置等,用 JSON 存储结构化配置信息。
- 数据存储:NoSQL 数据库(如 MongoDB)支持 JSON 格式的文档存储,部分关系型数据库也支持 JSON 字段。
- API 接口规范:RESTful API 通常以 JSON 作为数据交换格式,例如 OpenAPI(Swagger)规范。
3.1.json.dump():用于将 Python 对象(如字典、列表)转换为 JSON 格式的字符串,并将其写入文件或类文件对象(如网络连接、内存缓冲区等)。这一过程也被称为序列化(Serialization)。
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw)
参数说明:
obj:需要序列化的 Python 对象(如字典、列表)。fp:文件对象(如open('data.json', 'w')返回的对象),用于写入 JSON 数据。indent:可选参数,指定缩进空格数,用于美化 JSON 格式(如indent=2)。ensure_ascii:是否确保所有非 ASCII 字符被转义(默认True,中文会被转义为\uXXXX)。sort_keys:是否按字典键排序(默认False)。
import json
data = {
"name": "张三",
"age": 30,
"hobbies": ["阅读", "编程"],
"address": {"city": "北京", "zipcode": "100000"}
}
# 将数据写入JSON文件
with open("data.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
ensure_ascii=False:确保中文等非 ASCII 字符正确写入文件。indent=2:使用 2 个空格缩进,让 JSON 文件更易读。
若需将 JSON 数据打印到控制台或日志中,可结合sys.stdout使用:
import json
import sys
data = {"code": 200, "message": "操作成功", "data": [1, 2, 3]}
json.dump(data, sys.stdout, ensure_ascii=False, indent=2)
# 输出结果:
'''{
"code": 200,
"message": "操作成功",
"data": [
1,
2,
3
]
}'''
3.2.json.dumps():用于将 Python 对象(如字典、列表)转换为 JSON 格式的字符串。这一过程也被称为序列化(Serialization)。与json.dump()(写入文件)不同,json.dumps()返回字符串,适用于网络传输、打印输出或内存处理。
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw)
import json
data = {
"name": "张三",
"age": 30,
"hobbies": ["阅读", "编程"],
"is_student": False,
"address": {"city": "北京", "zipcode": "100000"}
}
# 将Python对象转换为JSON字符串
json_str = json.dumps(data, ensure_ascii=False, indent=2)
print(json_str)
输出结果
{
"name": "张三",
"age": 30,
"hobbies": ["阅读", "编程"],
"is_student": false,
"address": {
"city": "北京",
"zipcode": "100000"
}
}
在 API 接口或网络通信中,常将数据序列化为 JSON 字符串后发送:
import requests
import json
data = {"user_id": 123, "action": "login"}
json_payload = json.dumps(data)
try:
response = requests.post(
"https://api.example.com/user", # 替换为实际API地址
data=json_payload,
headers={"Content-Type": "application/json"}
)
response.raise_for_status() # 检查请求是否成功(状态码200)
except requests.exceptions.ConnectionError as e:
print(f"网络连接错误: {e}")
print("请检查域名是否正确、网络是否正常连接。")
except requests.exceptions.Timeout:
print("请求超时,请稍后重试。")
except requests.exceptions.HTTPError as e:
print(f"HTTP错误: {e}")
except requests.exceptions.RequestException as e:
print(f"请求发生异常: {e}")
else:
print("请求成功!")
print(response.json()) # 处理响应数据
| 函数名 |
功能描述 |
| json.dumps() |
将 Python 对象序列化为字符串(返回值为字符串,适用于网络传输)。 |
| json.dump() |
将 Python 对象序列化并写入文件(需传入文件对象,如open('data.json', 'w'))。 |
| json.loads() |
将 JSON 字符串反序列化为 Python 对象(解析字符串)。 |
| json.load() |
从文件中读取 JSON 数据并反序列化为 Python 对象。 |
4.re正则表达式数据解析(Regular Expression,简称 Regex 或 RE)是一种强大的文本模式匹配工具,用于在字符串中查找、提取或替换符合特定模式的文本片段。正则表达式数据解析就是利用这种模式匹配能力,从复杂的文本数据中提取出结构化的信息。
正则表达式在数据解析中广泛应用于以下场景:
- 文本提取:从网页、日志文件、配置文件等非结构化文本中提取特定信息
- 数据验证:检查输入数据是否符合特定格式(如邮箱、URL、电话号码)
-
- 文本替换:根据特定模式批量替换文本内容
- 字符串分割:根据特定分隔符将字符串分割成多个部分
- 日志分析:从系统日志中提取关键信息(如时间戳、错误代码)
- 普通字符:匹配自身,如
a匹配字符 "a"
- 元字符:具有特殊含义的字符,如
.匹配任意字符
- 字符类:用
[]表示,匹配方括号内的任意一个字符,如[abc]匹配 "a"、"b" 或 "c"
- 量词:控制匹配次数,如
*表示 0 次或多次,+表示 1 次或多次,?表示 0 次或 1 次
- 边界符:如
^表示字符串开始,$表示字符串结束
- 分组:用
()表示,可以捕获匹配的内容,如(abc)匹配并捕获 "abc"
①.基本元字符
| 元字符 |
描述 |
. |
匹配除换行符外的任意单个字符 |
^ |
匹配字符串的开始位置 |
$ |
匹配字符串的结束位置 |
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
? |
匹配前面的子表达式零次或一次 |
{n} |
匹配前面的子表达式恰好 n 次 |
{n,} |
匹配前面的子表达式至少 n 次 |
{n,m} |
匹配前面的子表达式至少 n 次,最多 m 次 |
②.字符类元字符
[] - 定义字符类,匹配方括号内的任意一个字符
- 例如:
[abc] 匹配 'a'、'b' 或 'c'
- 可以使用连字符表示范围:
[a-z] 匹配任意小写字母
- 开头使用
^ 表示取反:[^0-9] 匹配任意非数字字符
| 特殊字符 |
描述 |
\d |
匹配任意数字,等价于 [0-9] |
\D |
匹配任意非数字,等价于 [^0-9] |
\w |
匹配任意字母、数字或下划线,等价于 [a-zA-Z0-9_] |
\W |
匹配任意非字母、数字或下划线,等价于 [^a-zA-Z0-9_] |
\s |
匹配任意空白字符,包括空格、制表符、换页符等 |
\S |
匹配任意非空白字符 |
④.分组和引用
例如:(ab)+ 匹配一个或多个连续的 "ab"
可以捕获匹配的内容,用于后续引用
\1, \2, ... - 反向引用,引用前面捕获的分组
例如:(\w+) \1 匹配重复的单词,如 "hello hello"
| - 逻辑或,匹配两个或多个模式中的任意一个
例如:cat|dog 匹配 "cat" 或 "dog"
\ - 转义字符,用于取消元字符的特殊含义
例如:\. 匹配字面意义的点号,也用于表示特殊字符类,如 \d、\s 等
✍(?=...) - 正向肯定预查,匹配后面紧跟指定模式的位置
例如:\w+(?=\d) 匹配后面跟数字的单词
✍(?!...) - 正向否定预查,匹配后面不紧跟指定模式的位置
例如:\w+(?!\d) 匹配后面不跟数字的单词
✍(?<=...) - 反向肯定预查,匹配前面是指定模式的位置
例如:(?<=\$)\d+ 匹配前面是美元符号的数字
✍(?<!...) - 反向否定预查,匹配前面不是指定模式的位置
例如:(?<!\$)\d+ 匹配前面不是美元符号的数字
✍\b - 匹配单词边界,如 \bcat\b 只匹配独立的 "cat" 单词
✍\B - 匹配非单词边界
✍(?:...) - 非捕获组,分组但不捕获匹配的内容
⑨.贪婪匹配和惰性匹配
贪婪匹配:.* 意思是尽可能多的去匹配结果
惰性匹配:.*? 意思是尽可能少的去匹配结果
⑩.常用的正则表达式格式
re.findall(pattern, string, flags=0)
pattern:正则表达式模式字符串string:需要被搜索的原始字符串flags:可选参数,用于指定匹配模式(如忽略大小写、多行匹配等)
re.findall()的返回结果取决于正则表达式中是否包含捕获组:
- 无捕获组:直接返回所有匹配的子字符串列表
- 有一个捕获组:返回每个匹配中捕获组的内容列表
- 有多个捕获组:返回元组列表,每个元组包含一个匹配中所有捕获组的内容
import re
# 示例1:无捕获组,匹配所有数字
text1 = "hello 123 world 456"
result1 = re.findall(r'\d+', text1)
print(f"示例1结果: {result1}") # 输出: ['123', '456']
# 示例2:有一个捕获组,提取所有括号内的内容
text2 = "apple (red), banana (yellow), cherry (red)"
result2 = re.findall(r'\((.*?)\)', text2)
print(f"示例2结果: {result2}") # 输出: ['red', 'yellow', 'red']
# 示例3:有多个捕获组,提取所有水果和颜色
text3 = "apple=red, banana=yellow, cherry=red"
result3 = re.findall(r'(\w+)=(\w+)', text3)
print(f"示例3结果: {result3}") # 输出: [('apple', 'red'), ('banana', 'yellow'), ('cherry', 'red')]
# 示例4:使用标志参数忽略大小写
text4 = "Hello World, HELLO PYTHON"
result4 = re.findall(r'hello', text4, re.IGNORECASE)
print(f"示例4结果: {result4}") # 输出: ['Hello', 'HELLO']
# 示例5:多行匹配模式
text5 = "Line 1\nLine 2\nLine 3"
result5 = re.findall(r'^Line \d', text5, re.MULTILINE)
print(f"示例5结果: {result5}") # 输出: ['Line 1', 'Line 2', 'Line 3']
贪婪匹配与非贪婪匹配:
正则表达式中的 * 和 + 是贪婪的,会尽可能多地匹配字符
在量词后加 ? 可以使其变为非贪婪模式,尽可能少地匹配字符
边界处理:
使用 ^ 和 $ 匹配字符串的开始和结束
使用 \b 匹配单词边界,避免部分匹配
转义字符:
正则表达式中的特殊字符(如 ., *, + 等)需要使用 \ 进行转义
可以使用原始字符串(在字符串前加 r)避免 Python 字符串转义的干扰
捕获组的使用:
不需要提取内容时,可以使用非捕获组 (?:...) 提高效率
多个捕获组的结果按元组形式返回,注意顺序和数量
- 提取数据:从日志、HTML、JSON 等文本中提取关键信息
- 数据验证:检查输入是否符合特定格式(如邮箱、手机号)
- 文本分割:根据特定模式分割字符串
- 替换操作:配合
re.sub() 进行复杂的文本替换
4.2.re.finditer("正则表达式","原字符串","可选参数"):主要作用是在字符串中查找所有非重叠的匹配项,并返回一个包含匹配对象的迭代器。
re.finditer(pattern, string, flags=0)
# 或(使用预编译的正则对象)
pattern_obj.finditer(string)
- 返回值:一个迭代器,每个元素是
Match 对象(包含单次匹配的详细信息)。
- 返回迭代器:相比
findall() 直接返回匹配结果列表,finditer() 返回的迭代器更节省内存(尤其处理大字符串时)。
- 保留匹配细节:每个
Match 对象包含匹配的文本、位置、分组等信息(如命名分组、索引分组)。
- 非重叠匹配:只返回不重叠的匹配项(例如用
'aa' 匹配 'aaaa',会得到 ['aa', 'aa'] 而非 ['aa', 'aa', 'aa'])。
通过迭代器获取的 Match 对象有以下常用方法 / 属性:
group(n):返回第 n 个分组的匹配结果(n=0 或省略时返回整个匹配文本;命名分组可用 group('name'))。groups():返回所有分组的匹配结果组成的元组。span():返回匹配文本在原始字符串中的起始和结束索引(元组 (start, end))。
import re
# 假设这是从网页获取的 HTML 片段(简化版)
html = '''
<div class="item">
<span class="title">肖申克的救赎</span>
</div>
<div class="item">
<span class="title">霸王别姬</span>
</div>
'''
# 预编译正则(匹配电影名称)
pattern = re.compile(r'<span class="title">(?P<name>.*?)</span>', re.S)
# 使用 finditer() 查找所有匹配
matches = pattern.finditer(html)
# 遍历迭代器,提取每个匹配的信息
for match in matches:
# 获取整个匹配的文本(包含标签)
print("完整匹配:", match.group(0)) # <span class="title">肖申克的救赎</span>
# 获取命名分组 'name' 的内容(电影名称)
print("电影名称:", match.group('name')) # 肖申克的救赎
# 获取匹配的位置(在原始字符串中的索引)
print("位置:", match.span()) # (例如 (19, 45),具体值取决于字符串)
print("---")
4.3.re.sub("正则表达式","替换的字符串","原字符串","可选参数"):用于在字符串中替换所有匹配正则表达式的子串。这是处理文本数据时非常常用的功能,比如清洗数据、格式化文本等。
re.sub(pattern, repl, string, count=0, flags=0)
pattern:正则表达式模式字符串,用于匹配需要替换的子串repl:替换字符串或可调用对象,用于替换匹配到的内容string:需要被处理的原始字符串count:可选参数,指定最多替换次数(默认为 0,表示全部替换)flags:可选参数,用于指定匹配模式(如忽略大小写、多行匹配等)
当 repl 是字符串时,可以使用以下特殊语法:
\g<group>:引用指定编号或名称的捕获组\1, \2, ...:引用第 1、2 等捕获组\g<0>:引用整个匹配的子串
import re
# 示例1:简单替换,将所有数字替换为X
text1 = "hello 123 world 456"
result1 = re.sub(r'\d', 'X', text1)
print(f"示例1结果: {result1}") # 输出: hello XXX world XXX
# 示例2:使用捕获组,交换姓名顺序
text2 = "Zhang San, Li Si, Wang Wu"
result2 = re.sub(r'(\w+) (\w+)', r'\2 \1', text2)
print(f"示例2结果: {result2}") # 输出: San Zhang, Si Li, Wu Wang
# 示例3:使用命名捕获组,格式化日期
text3 = "2023-10-01"
result3 = re.sub(r'(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})',
r'\g<month>/\g<day>/\g<year>', text3)
print(f"示例3结果: {result3}") # 输出: 10/01/2023
# 示例4:使用函数进行动态替换,将数字乘以2
def double_number(match):
return str(int(match.group(0)) * 2)
text4 = "A1B2C3"
result4 = re.sub(r'\d', double_number, text4)
print(f"示例4结果: {result4}") # 输出: A2B4C6
# 示例5:限制替换次数
text5 = "apple apple apple"
result5 = re.sub(r'apple', 'orange', text5, count=2)
print(f"示例5结果: {result5}") # 输出: orange orange apple
# 示例6:忽略大小写替换
text6 = "Hello World, hello Python"
result6 = re.sub(r'hello', 'hi', text6, flags=re.IGNORECASE)
print(f"示例6结果: {result6}") # 输出: hi World, hi Python
当 repl 是一个函数时,每次匹配成功后,该函数会被调用,传入匹配对象(match)作为参数,并返回替换字符串。这在需要根据匹配内容进行动态替换时非常有用。
例如,将字符串中的所有数字替换为其平方值:
def square_number(match):
num = int(match.group(0))
return str(num ** 2)
text = "a1b2c3"
result = re.sub(r'\d', square_number, text)
print(result) # 输出: a1b4c9
- 数据清洗:移除或替换特殊字符、多余空格等
- 文本格式化:将日期、电话号码等转换为统一格式
- 敏感信息处理:替换或掩码化敏感数据(如身份证号、信用卡号)
- 语法转换:在不同编程语言或格式之间转换语法
- 模板替换:根据规则动态生成文本内容
正则表达式中的特殊字符需要使用 \ 进行转义
可以使用原始字符串(如 r'\d+')避免 Python 字符串转义的干扰
使用 () 定义捕获组,可以在替换字符串中引用
使用非捕获组 (?:...) 避免不必要的捕获,提高效率
替换字符串中的反斜杠需要转义(如 \\ 表示一个反斜杠)
- 可以使用原始字符串简化处理(如
r'\\section')
通过合理使用 re.sub(),可以高效地完成各种复杂的文本替换任务。
re.finditer(pattern, string, flags=0)
group(0):返回整个匹配的字符串start():返回匹配开始的位置end():返回匹配结束的位置span():返回一个元组 (start, end)
result = re.finditer(r"\d+", "我今年42岁,我有2000000元")
for item in result:
print(item.group(0))
#输出结果:42 2000000
import re
# 使用 re.finditer() 查找所有数字
result = re.finditer(r"\d+", "我今年42岁,我有2000000元")
# 遍历迭代器并打印匹配结果
for match in result:
print(f"匹配到的数字: {match.group(0)}")
print(f"位置: {match.start()} - {match.end()}")
print(f"原始字符串中的片段: {match.string[match.start():match.end()]}")
print("-" * 20)
"""输出结果:
匹配到的数字: 42
位置: 3 - 5
原始字符串中的片段: 42
--------------------
匹配到的数字: 2000000
位置: 8 - 15
原始字符串中的片段: 2000000
--------------------"""
re.findall():返回所有匹配的字符串列表re.finditer():返回一个迭代器,每次迭代返回一个匹配对象
当处理大量数据时,re.finditer() 更节省内存,因为它不需要一次性存储所有匹配结果。
4.5.re.search("正则表达式","原字符串","可选参数"):用于在字符串中搜索第一个匹配正则表达式的位置。与 re.findall() 和 re.finditer() 不同,re.search() 只返回第一个匹配结果,如果没有找到则返回 None。
re.search(pattern, string, flags=0)
pattern:正则表达式模式字符串string:需要被搜索的原始字符串flags:可选参数,用于指定匹配模式(如忽略大小写、多行匹配等)
如果找到匹配项,返回一个 匹配对象(match object),否则返回 None。匹配对象包含以下常用方法和属性:
group(0):返回整个匹配的字符串group(1), group(2), ...:返回第 1、2 等捕获组的内容start():返回匹配开始的位置end():返回匹配结束的位置span():返回一个元组 (start, end)
import re
# 示例1:查找第一个数字
text1 = "hello 123 world 456"
match1 = re.search(r'\d+', text1)
if match1:
print(f"找到数字: {match1.group(0)}") # 输出: 123
print(f"位置: {match1.start()} - {match1.end()}") # 输出: 6 - 9
else:
print("未找到匹配项")
# 示例2:使用捕获组提取信息
text2 = "我的邮箱是 [email protected],请查收"
match2 = re.search(r'(\w+)@(\w+\.\w+)', text2)
if match2:
print(f"完整邮箱: {match2.group(0)}") # 输出: [email protected]
print(f"用户名: {match2.group(1)}") # 输出: example
print(f"域名: {match2.group(2)}") # 输出: domain.com
# 示例3:忽略大小写查找
text3 = "Hello World"
match3 = re.search(r'world', text3, re.IGNORECASE)
if match3:
print(f"找到匹配: {match3.group(0)}") # 输出: World
# 示例4:多行模式下的搜索
text4 = "第一行\n第二行\n第三行"
match4 = re.search(r'^第(.*)行$', text4, re.MULTILINE)
if match4:
print(f"匹配行内容: {match4.group(0)}") # 输出: 第一行
print(f"捕获内容: {match4.group(1)}") # 输出: 一
import re
# 通过用户输入获取密码
password = input("请输入密码:")
if re.search(r'^[a-zA-Z0-9]+$', password):
print("密码格式有效")
else:
print("密码格式无效,只能包含字母和数字")
import re
# 定义要搜索的文本
text = "这是一个测试,商品价格:99.99元"
match = re.search(r'价格:(\d+\.\d+)元', text)
if match:
price = float(match.group(1))
print(f"商品价格: {price} 元")
else:
print("未找到价格信息")
#输出结果:商品价格: 99.99 元
#从用户输入获取 text
import re
# 从用户输入获取文本
text = input("请输入包含价格的文本(例如:商品价格:99.99元):")
# 修改正则表达式,允许匹配整数或小数价格
match = re.search(r'价格:(\d+(?:\.\d+)?)元', text)
if match:
try:
price = float(match.group(1))
print(f"成功提取价格: {price} 元")
except ValueError:
print("错误:无法将提取的内容转换为价格")
else:
print("未找到符合格式的价格信息")
print("提示:请确保输入的文本包含如'价格:99.99元'或'价格:100元'的格式")
import re
# 从文件读取文本
try:
with open('input.txt', 'r', encoding='utf-8') as file:
text = file.read()
except FileNotFoundError:
print("文件未找到,请检查文件路径")
exit()
match = re.search(r'价格:(\d+\.\d+)元', text)
if match:
price = float(match.group(1))
print(f"商品价格: {price} 元")
else:
print("未找到价格信息")
import re
# 通过用户输入获取电话号码
phone_number = input("请输入电话号码:")
if re.search(r'^\d{11}$', phone_number):
print("手机号码格式正确")
else:
print("手机号码格式错误,必须是11位数字"
-
匹配对象的判断:
- 由于
re.search() 可能返回 None,在使用前应先检查是否为 None
- 示例:
match = re.search(pattern, string) → if match:
-
捕获组的编号:
- 捕获组从 1 开始编号,
group(0) 表示整个匹配
- 嵌套捕获组的编号按照左括号出现的顺序确定
-
正则表达式的边界:
- 使用
^ 和 $ 来限制匹配的范围
- 例如:
re.search(r'^hello$', text) 要求整个字符串必须是 "hello"
- 通过合理使用
re.search(),可以高效地完成各种文本搜索和提取任务。
4.6.re.match("正则表达式","原字符串","可选参数"):主要用于在字符串的起始位置对正则表达式进行匹配。要是匹配成功,它会返回一个匹配对象;要是匹配失败,则返回None。
re.match(pattern, string, flags=0)
- pattern:此为必选参数,代表的是要进行匹配的正则表达式。
- string:同样是必选参数,指的是需要被匹配的字符串。
- flags:这是可选参数,用于指定匹配模式,像忽略大小写、多行匹配等。该参数的值可以是多个标志的按位或运算结果(例如
re.I | re.M)。
- 仅匹配开头:
re.match只会从字符串的起始位置开始尝试匹配。若起始位置不符合正则表达式,即便后续部分有符合的内容,也会匹配失败。
- 返回匹配对象:一旦匹配成功,就会返回一个包含匹配信息的对象。借助这个对象,你可以获取匹配的内容、位置等信息。
当re.match返回匹配对象后,可以使用以下方法获取匹配信息:
group([group1, ...]):用于获取一个或多个分组的匹配内容。若不指定参数,则返回整个匹配结果。groups():返回一个包含所有分组匹配结果的元组。start([group]):返回指定分组匹配的起始位置。若未指定分组,则返回整个匹配的起始位置。end([group]):返回指定分组匹配的结束位置(不包含该位置的字符)。span([group]):返回一个元组,包含指定分组匹配的起始和结束位置。
re.match:只在字符串的起始位置进行匹配。re.search:会在整个字符串中进行搜索匹配,只要找到第一个匹配项就会返回。
import re
string = "Hello, world!"
match = re.match("world", string) # 匹配失败,返回None
search = re.search("world", string) # 匹配成功,返回匹配对象
print(match) # 输出:None
print(search.group()) # 输出:world
- 正则表达式的转义:在正则表达式里,像
.、*、+这类字符有特殊含义。如果要匹配它们的字面意思,需要使用反斜杠\进行转义。
- 原始字符串:编写正则表达式时,建议使用原始字符串(即在字符串前加
r),这样可以避免 Python 本身的转义问题。例如,匹配反斜杠本身时,使用r'\\'比'\\\\'更清晰。
4.7.re.compile("正则表达式","可选参数"):用于将正则表达式模式编译为一个正则表达式对象。编译后的对象可以多次使用,叫做预加载,提高匹配效率,尤其在需要重复匹配相同模式的场景下性能更优。
re.compile(pattern, flags=0)
pattern:要编译的正则表达式模式。flags:可选参数,用于指定正则表达式的匹配模式,如忽略大小写、多行匹配等。
import re
# 编译正则表达式
pattern = re.compile(r'\d+') # 匹配一个或多个数字
# 使用编译后的对象进行匹配
text = "Hello 123 World 456"
# 查找所有匹配
matches = pattern.findall(text)
print(f"所有匹配: {matches}") # 输出: ['123', '456']
# 使用 search 方法查找第一个匹配
match = pattern.search(text)
if match:
print(f"第一个匹配: {match.group(0)}, 位置: {match.start()}") # 输出: 第一个匹配: 123, 位置: 6
直接使用 re 模块的函数(如 re.findall()、re.search())时,Python 会在内部自动编译正则表达式。而使用 re.compile 可以显式编译正则表达式,避免重复编译,提高性能。
import re
text = "Hello 123 World 456"
matches = re.findall(r'\d+', text) # 每次调用都编译一次正则表达式
print(matches)#输出:['123','456']
import re
pattern = re.compile(r'\d+') # 编译一次
matches1 = pattern.findall("Hello 123") # 直接使用已编译的对象
matches2 = pattern.findall("World 456") # 再次使用,无需重新编译
print(matches1) # 输出: ['123']
print(matches2) # 输出: ['456']
编译后的正则表达式对象支持与 re 模块相同的方法,例如:
pattern.match(string[, pos[, endpos]]):从字符串的起始位置开始匹配。pattern.search(string[, pos[, endpos]]):在字符串中搜索第一个匹配项。pattern.findall(string[, pos[, endpos]]):返回所有匹配的字符串列表。pattern.finditer(string[, pos[, endpos]]):返回匹配对象的迭代器。pattern.sub(repl, string[, count]):替换匹配的子串。
import re
# 预编译正则表达式
email_pattern = re.compile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b')
# 待验证的邮箱列表
emails = ["[email protected]", "invalid.email", "[email protected]"]
# 循环验证邮箱
for email in emails:
if email_pattern.match(email):
print(f"{email} 是有效的邮箱地址")
else:
print(f"{email} 不是有效的邮箱地址")
re.compile 支持与 re 模块函数相同的标志参数,例如:
re.IGNORECASE 或 re.I:忽略大小写。re.MULTILINE 或 re.M:多行匹配模式。re.DOTALL 或 re.S:使 . 匹配包括换行符在内的所有字符。
import re # 添加模块导入语句
pattern = re.compile(r'hello', re.IGNORECASE) # 忽略大小写的匹配
print(pattern.search("Hello World").group(0)) # 输出: Hello
总之,re.compile 是优化正则表达式性能的重要工具,尤其适用于需要重复使用同一模式的场景。
4.8.re.S: 匹配模式修饰符,也可以写作 re.DOTALL。
它的作用是改变 .(点号)的匹配行为:
- 默认情况下,
. 可以匹配除换行符 \n 之外的任意字符
- 当使用
re.S 模式后,. 可以匹配包括换行符 \n 在内的任意字符
import re
text = "hello\nworld"
# 不使用 re.S,无法匹配换行符
print(re.findall("hello.world", text)) # 输出: []
# 使用 re.S,点号可以匹配换行符
print(re.findall("hello.world", text, re.S)) # 输出: ['hello\nworld']
这个修饰符在需要匹配多行文本时非常有用,比如处理包含换行的字符串或多行文本内容。re.DOTALL 是更具描述性的别名,功能与 re.S 完全相同。
re正则表达式代码示例:
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>', re.S)
代码解释:
这段代码使用 Python 的 re.compile() 函数编译了一个正则表达式模式,用于从 HTML 文本中提取特定标签内的内容。以下是逐部分解释:
re.compile(pattern, flags) 是 Python 正则模块 re 的核心函数,作用是将正则表达式字符串预编译为一个正则对象(这里赋值给 obj)。预编译的好处是:如果需要多次使用该正则表达式(比如循环匹配多页内容),编译后可以提高执行效率。
这是一个原始字符串(前缀 r 表示不解析转义字符,避免正则中的 \ 被误处理),用于精准匹配 HTML 中特定结构的内容:
<div class="item">:匹配 HTML 中 class 属性为 item 的 <div> 标签(豆瓣 Top250 中每个电影条目都包裹在这样的 <div> 里,是单个电影信息的外层容器)。.*?:非贪婪匹配(.* 匹配任意字符,? 表示尽可能少匹配),用于跳过 <div> 和 <span> 之间的内容。<span class="title">:匹配 class 属性为 title 的 <span> 标签(豆瓣电影名称通常放在这个标签内),是电影名称的 “开始标记”。(?P<name>.*?):命名分组(核心部分):(?P<name>...) 是 Python 正则的语法,给括号内匹配的内容起一个名字(这里叫 name),后续可以通过 group('name') 直接提取该部分内容,无需记索引位置。*? 非贪婪匹配 <span class="title"> 和 </span> 之间的文本(即我们要提取的电影名称)。</span>:匹配 <span> 标签的闭合标签,作为电影名称的 “结束标记”,确保只提取标签内的文本。
re.S 是正则表达式的标志位(也可写作 re.DOTALL),作用是:让 .(匹配任意字符)可以匹配换行符 \n。
在 HTML 中,标签可能跨多行(如:
<div class="item">
<div class="other-info">...</div>
<span class="title">肖申克的救赎</span>
</div>
如果不加 re.S,.*? 会在换行符处停止匹配,导致无法跨越换行找到 <span class="title">;加了 re.S 后,.*? 可以匹配包括换行在内的所有字符,确保整个结构被正确匹配。
这段代码的作用是:
预编译一个正则表达式,专门用于从豆瓣
Top250 页面的 HTML 中,匹配每个电影条目
(<div class="item">)内的电影名称标签(
<span class="title">),并将标签内的电影名称提取出来,命名为
name 以便后续使用。
搭配 finditer() 等方法使用时,就能批量提取页面中的所有电影名称了(例如:for item in obj.finditer(html): print(item.group('name')))。
import requests
import re
# 1. 获取页面
url = 'https://movie.douban.com/top250'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8' # 正确设置编码的方式
# 2. 正则表达式提取电影名称
# 编译正则表达式
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>', re.S)
# 查找所有匹配结果
result = obj.finditer(response.text)
# 遍历结果并打印
for item in result: # 正确的循环语法:for ... in ...
print(item.group('name'))
5.CSV文件写入(内置模块)
import csv
# 数据
data = [
["姓名", "年龄", "城市"],
["张三", 25, "北京"],
["李四", 30, "上海"],
["王五", 28, "广州"]
]
# 写入CSV文件
with open("people.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# 写入多行
writer.writerows(data)
# 也可以单行写入
# writer.writerow(["赵六", 35, "深圳"])
import csv
# 数据
data = [
{"姓名": "张三", "年龄": 25, "城市": "北京"},
{"姓名": "李四", "年龄": 30, "城市": "上海"},
{"姓名": "王五", "年龄": 28, "城市": "广州"}
]
# 字段名(表头)
fieldnames = ["姓名", "年龄", "城市"]
with open("people_dict.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入数据
writer.writerows(data)
# 单行写入
# writer.writerow({"姓名": "赵六", "年龄": 35, "城市": "深圳"})
import csv
with open("custom_sep.csv", "w", newline="", encoding="utf-8") as file:
# 使用制表符作为分隔符(类似TSV文件)
writer = csv.writer(file, delimiter="\t")
writer.writerows([["a", "b", "c"], ["1", "2", "3"]])
- 使用
newline=""参数可以避免在 Windows 系统中出现多余的空行
- 指定
encoding="utf-8"可以确保中文正常显示
- 写入完成后,文件会自动关闭(因为使用了
with语句)
这些方法可以满足大多数 CSV 文件写入需求,根据你的数据格式选择合适的方式即可。
5.4.enumerate(迭代对象,[0]:):枚举对象转换:用于将一个可迭代对象(如列表、元组、字符串等)转换为一个枚举对象,在遍历过程中同时返回「元素的索引」和「元素的值」。
enumerate(iterable, start=0)
iterable:需要遍历的可迭代对象(如列表、字符串等)start:可选参数,指定索引的起始值,默认从 0 开始
当你需要遍历一个序列,同时又需要知道每个元素在序列中的位置(索引)时,enumerate() 可以简化代码。
例如,不使用 enumerate() 时,可能需要这样写:
fruits = ['apple', 'banana', 'cherry']
index = 0
for fruit in fruits:
print(f"Index: {index}, Fruit: {fruit}")
index += 1 # 手动维护索引
而使用 enumerate() 后,代码更简洁:
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits):
print(f"Index: {index}, Fruit: {fruit}")
'''
输出结果:
Index: 1, Fruit: apple
Index: 2, Fruit: banana
Index: 3, Fruit: cherry
'''
如果从第二个数据(banana)开始迭代,可以先对列表进行切片处理,从索引 1 开始(因为 Python 列表索引从 0 开始,第二个元素的索引是 1),再传入enumerate()函数中。
fruits = ['apple', 'banana', 'cherry']
# 从索引1开始切片,只处理'banana'和'cherry'
for index, fruit in enumerate(fruits[1:]):
# 注意:此时的index是相对于切片后列表的索引(从0开始)
# 如果需要显示原列表中的真实索引,需要加上偏移量1
print(f"原索引: {index + 1}, Fruit: {fruit}")
'''
输出结果:
原索引: 1, Fruit: banana
原索引: 2, Fruit: cherry
'''
简单说,enumerate() 的核心作用就是在遍历过程中同时获取元素及其位置信息,让代码更简洁高效。
自动爬虫
1.selemium:是一套用于Web应用程序自动化测试的工具集,同时也广泛用于网络数据爬取(合规场景下)、自动化操作浏览器(如自动填写表单、模拟用户交互等)。它的核心能力是直接控制浏览器(如 Chrome、Firefox),模拟真实用户的操作行为(点击、输入、跳转等),是 Web 自动化领域最流行的工具之一。
Selenium 并非单一工具,而是由多个组件构成,不同组件适用于不同场景:
Selenium 实现浏览器控制的核心是 “WebDriver + 浏览器驱动” 的协作模式,流程如下:
- 开发者编写代码:通过 Python/Java 等语言调用 Selenium WebDriver 的 API(如
click()、send_keys())。
- WebDriver 转发指令:WebDriver 将代码中的操作指令(如 “点击按钮”)转换为浏览器能识别的协议(如 W3C WebDriver 协议)。
- 浏览器驱动执行:需提前安装对应浏览器的 “驱动程序”(如 Chrome 对应
chromedriver),驱动接收指令后,控制浏览器执行具体操作。
- 浏览器返回结果:操作结果(如页面渲染、元素状态变化)通过驱动反馈给 WebDriver,最终可在代码中获取(如获取页面源码、元素文本)。
简单来说:代码 → WebDriver → 浏览器驱动 → 浏览器,形成一套完整的 “指令下发 - 执行 - 反馈” 闭环。
-
- Chrome(需
chromedriver)
- Firefox(需
geckodriver)
- Edge(需
msedgedriver)
- Safari(macOS 自带驱动,需手动开启)
-
多编程语言支持
提供丰富的语言绑定,开发者可使用熟悉的语言编写脚本:
- 主流语言:Python、Java、JavaScript(Node.js)、C#、Ruby
- 小众语言:Perl、PHP
-
模拟真实用户操作
支持几乎所有用户在浏览器上的操作,覆盖复杂交互场景:
- 基础操作:点击(
click())、输入文本(send_keys())、清空内容(clear())、刷新页面(refresh())
- 进阶操作:鼠标悬停(
ActionChains)、下拉滚动(execute_script() 执行 JS)、切换窗口 /iframe(switch_to)、处理弹窗(alert)
- 等待机制:支持 “显式等待”(等待特定元素加载完成)和 “隐式等待”(全局等待超时),解决页面异步加载导致的元素定位失败问题。
-
元素定位能力
提供 8 种主流元素定位方式,可精准定位页面中的任何元素(如按钮、输入框、列表)
以最常用的 Python + Chrome 组合为例,演示核心流程:
通过 pip 安装 Python 版本的 Selenium:
- 查看本地 Chrome 版本:打开 Chrome → 右上角三个点 → 帮助 → 关于 Google Chrome(如版本 141.0.7390.54)。
- 官方地址:ChromeDriver - WebDriver for Chrome
(注意:驱动版本需与 Chrome 版本完全匹配,或兼容匹配,否则无法启动浏览器)。
- 配置驱动:将下载的
chromedriver.exe(Windows)或 chromedriver(macOS/Linux)放在 Python 安装目录,或添加到系统环境变量。


下面代码实现 “打开百度 → 输入关键词 → 点击搜索 → 获取搜索结果” 的自动化流程:
#1.导包
from selenium import webdriver
import time
from selenium.webdriver.common.by import By #定义类
from selenium.webdriver.common.keys import Keys #定义键盘类
web = webdriver.Chrome()
web.maximize_window() #窗口最大化
web.get('https://www.baidu.com/')
print(web.title) #获取百度网站标题 百度一下,你就知道
ipt = web.find_element(By.ID,"chat-textarea")
ipt.send_keys('美女',Keys.ENTER) #自动回车
time.sleep(5)
web.quit()
#2.导包
from selenium.webdriver import Chrome
import time
from selenium.webdriver.common.by import By #定义类
from selenium.webdriver.common.keys import Keys #定义键盘类
web = webdriver.Chrome()
web.maximize_window() #窗口最大化
web.get('https://www.baidu.com/')
ipt = web.find_element(By.ID,"chat-textarea")
ipt.send_keys('美女')
web.find_element(By.ID,"chat-submit-button").click()#自动点击
time.sleep(5)
web.quit()
web.minimize_window() # 窗口最小化
web.set_window_size(1000, 500) #设置固定的窗口大小
ipt = web.find_element(By.CLASS_NAME, 's_ipt') # 如果需要用CLASS_NAME 需要注意 只适用于class值只有一个的情况
ipt = web.find_element(By.XPATH, '//*[@id="chat-textarea"]') #Xpath正则表达式
web.find_element(By.XPATH, '//div[@class="c-container"]').screenshot('截图.png') # screenshot截图方法 传参截图存储路径
web.save_screenshot('浏览器窗口.png') # 截图浏览器内部窗口图片
ps = web.page_source # 获取元素面板的html结构数据
b = web.find_element(By.LINK_TEXT, '贴吧') # 通过文本值去定位 文本值需要是标签里面的全部文本
print(b.text) # 获取标签文本内容
print(b.get_attribute('href')) # 获取属性值 传参属性名
print(b.location) # 获取标签左上角点相对于浏览器窗口原点的 坐标 {'x': 191, 'y': 19}
print(b.size) # 标签宽高尺寸 {'height': 23, 'width': 26}
b = web.find_element(By.PARTIAL_LINK_TEXT, '贴') # 通过文本值去定位 文本值可以是部分文本
# print(b)
from selenium import webdriver
from selenium.webdriver.common.by import By # 定位类
import time
web = webdriver.Chrome() # 实例化浏览器对象
web.maximize_window() # 窗口最大化
web.implicitly_wait(3) # 隐式等待 轮询
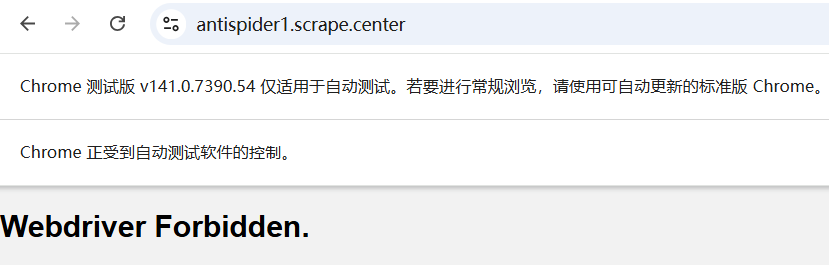
web.get('https://antispider1.scrape.center/')
time.sleep(1900)
web.quit() # 关闭浏览器
显示结果:
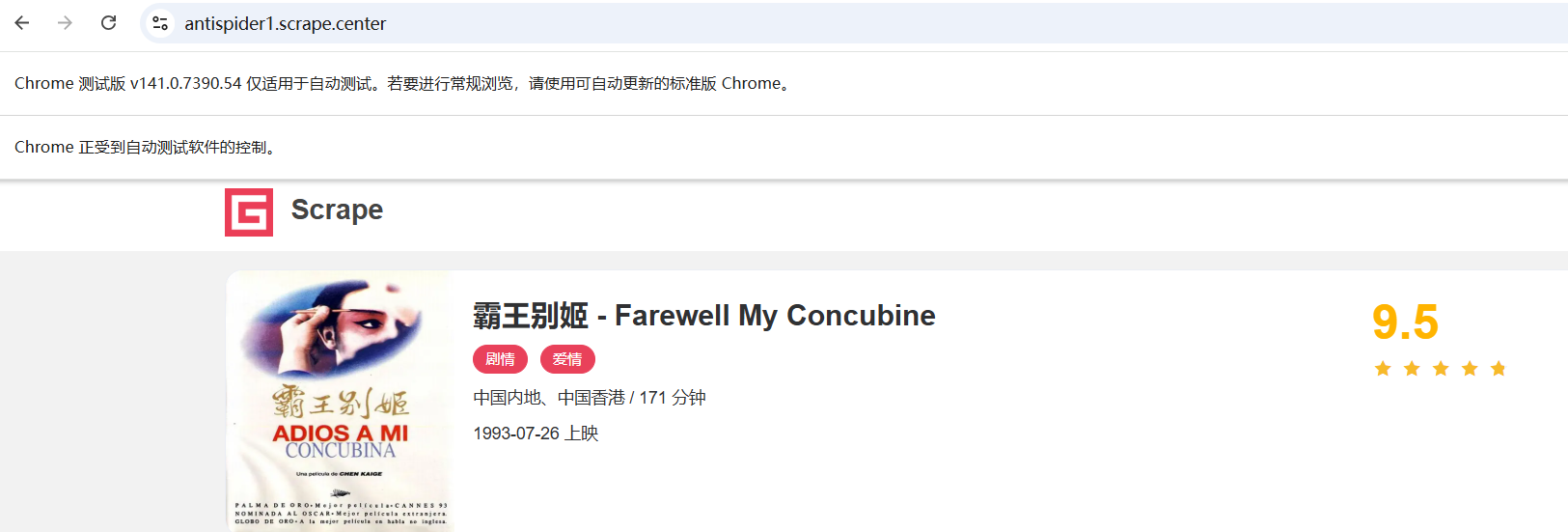
添加规避检测代码后会正常显示
from selenium import webdriver
from selenium.webdriver.common.by import By # 定位类
import time
web = webdriver.Chrome() # 实例化浏览器对象
web.maximize_window() # 窗口最大化
web.implicitly_wait(3) # 隐式等待 轮询
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => false
})"""
}) # 规避检测 当获取navigator下面的webdriver的时候 篡改为false
web.get('https://antispider1.scrape.center/')
time.sleep(1900)
web.quit() # 关闭浏览器
⑤.浏览器自动关闭与保持打开的3种方案
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # 用于detach配置
import time
# ==============================
# 方案1:固定时间等待(脚本暂停N秒后关闭,适合自动测试)
# ==============================
print("=== 运行方案1:固定时间等待 ===")
# 初始化浏览器
web1 = webdriver.Chrome()
web1.maximize_window()
web1.get('https://www.baidu.com/')
# 关键:固定等待10秒(可修改数字调整等待时长)
time.sleep(10)
# 等待结束后关闭当前浏览器(避免多窗口干扰)
web1.quit()
print("方案1执行完毕,浏览器已关闭\n")
# ==============================
# 方案2:用户输入等待(按回车键才关闭,适合手动操作浏览器)
# ==============================
print("=== 运行方案2:用户输入等待 ===")
# 初始化浏览器
web2 = webdriver.Chrome()
web2.maximize_window()
web2.get('https://www.baidu.com/')
# 关键:等待用户在控制台按回车键(按前浏览器保持打开)
input("方案2提示:请在控制台按【回车键】关闭浏览器...")
# 用户按回车后关闭浏览器
web2.quit()
print("方案2执行完毕,浏览器已关闭\n")
# ==============================
# 方案3:detach配置(脚本结束后浏览器仍保持打开,需手动关闭)
# ==============================
print("=== 运行方案3:detach配置(浏览器将保持打开) ===")
# 1. 创建Chrome配置对象,添加“进程分离”参数
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) # 核心配置:浏览器不随脚本关闭
# 2. 初始化浏览器时传入配置
web3 = webdriver.Chrome(options=chrome_options)
web3.maximize_window()
web3.get('https://www.baidu.com/')
print("方案3执行完毕,浏览器已启动(需手动点击窗口右上角关闭)")
-
Web 自动化测试
这是 Selenium 的核心场景:开发者 / 测试工程师编写脚本,自动验证 Web 应用的功能(如登录、支付、表单提交),替代人工测试,提高效率并减少重复工作。例如:验证 “用户输入错误密码时,登录按钮是否提示错误”。
-
合规网络爬虫
对于动态渲染的网页(如 JavaScript 加载的内容,普通爬虫无法获取),Selenium 可模拟浏览器加载完整页面,再提取数据。注意:需遵守网站的 robots.txt 协议,避免非法爬取。
-
浏览器自动化操作
- 自动填写重复性表单(如每日打卡、报表提交);
- 自动监控网页内容变化(如商品价格、公告更新);
- 批量执行浏览器操作(如批量下载文件、批量截图)。
①.驱动版本不匹配
报错表现:SessionNotCreatedException。
解决:确保浏览器版本与驱动版本完全一致(或查看驱动官网的 “兼容版本说明”)。
②.元素定位失败
常见原因:
- 页面未加载完成就定位元素:使用 “显式等待”(
WebDriverWait)替代 “强制等待”(time.sleep());
- 元素在
iframe 中:需先通过 driver.switch_to.frame(iframe元素) 切换到 iframe,再定位元素;
在 Selenium 中切换 iframe(内嵌框架)是处理嵌套页面元素的常见操作,主要通过以下几种方法实现,核心是使用switch_to.frame()方法:
如果 iframe 有唯一的id或name属性,直接传入该属性值即可:
from selenium import webdriver
web = webdriver.Chrome()
web.get("目标页面URL")
# 通过id切换
web.switch_to.frame("iframe_id")
# 或通过name切换
web.switch_to.frame("iframe_name")
先定位到 iframe 元素,再传入该元素对象(适用于无 id/name 或属性不唯一的情况):
# 先定位iframe元素(可用xpath、css selector等)
iframe_element = web.find_element(By.XPATH, "//iframe[@class='xxx']")
# 切换到该iframe
web.switch_to.frame(iframe_element)
如果 iframe 在页面中的位置固定,可通过索引(从0开始)切换(不推荐,因页面结构变化可能导致索引失效):
# 切换到第1个iframe(索引0)
web.switch_to.frame(0)
操作完 iframe 内的元素后,需切换回主页面,否则无法操作主文档的元素:
# 切回主文档
web.switch_to.default_content()
如果 iframe 嵌套在另一个 iframe 内,可通过以下方法返回上一级 iframe:
# 切换到父级iframe
web.switch_to.parent_frame()
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 等待iframe加载并切换
WebDriverWait(driver, 10).until(
EC.frame_to_be_available_and_switch_to_it((By.ID, "iframe_id"))
)
- 若 iframe 是动态生成的(如
id带随机值),优先用WebElement方法定位(通过其他稳定属性,如class、src等)。
- 元素是动态生成的(如点击后才出现):确保操作顺序正确,先触发元素生成,再定位。
③.浏览器无头模式
若不需要可视化浏览器窗口(如服务器环境),可开启 “无头模式”(Headless),减少资源占用:
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless=new") # 开启无头模式(Chrome 112+ 推荐)
driver = webdriver.Chrome(options=chrome_options)
总之,Selenium 是 Web 自动化领域的 “瑞士军刀”,灵活性高、功能全面,尤其适合需要模拟真实用户交互的场景。掌握它需要熟悉 “元素定位” 和 “等待机制” 这两个核心点,再结合具体场景扩展即可。
八、验证码
①.自动拖动(滑动)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains # 动作链类
web = webdriver.Chrome()
web.maximize_window()
web.implicitly_wait(3)
web.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 通过id去定位iframe
# web.switch_to.frame('iframeResult')
# # 通过selenium定位标签对象去定位iframe
web.switch_to.frame(web.find_element(By.XPATH, '//*[@id="iframeResult"]'))
btn = web.find_element(By.ID, 'draggable')
# 动作链
action = ActionChains(web) # 实例化动作链类 传参浏览器对象
action.click_and_hold(btn) # 按下鼠标左键不松开
# action.move_by_offset(249, 0) # 鼠标向右移动249个距离 x向右是正数 左是负 y向下是正 上是负
for i in range(10):
action.move_by_offset(24.9, 12) # 鼠标向右移动249个距离
action.release() # 松开鼠标左键
action.perform() # 执行动作链当中的动作
time.sleep(5)
web.quit()
"""
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动多少距离
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
"""
②.字母识别
pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
import time
import ddddocr
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化浏览器
web = webdriver.Chrome()
web.maximize_window()
web.implicitly_wait(3)
web.get('https://www.chaojiying.com/user/login/')
# 输入账号密码
web.find_element(By.NAME, 'user').send_keys('3010784452')
time.sleep(1)
web.find_element(By.NAME, 'pass').send_keys('T147258369')
# 截取验证码图片文本识别
web.find_element(By.XPATH, '//div[@class="login_form"]//img').screenshot('code.png')
# 使用ddddocr识别验证码(得到字符串结果)
ocr = ddddocr.DdddOcr()
with open('code.png', 'rb') as f:
im = f.read()
code = ocr.classification(im) # 识别出的验证码字符串
# 将验证码字符串输入输入框(关键修正:传入code而非im)
web.find_element(By.NAME, "imgtxt").send_keys(code)
# 可选:点击登录按钮
web.find_element(By.XPATH, '//input[@class="login_submit"]').click()
③.文字识别
Tesseract-ocr:免费的,简单的验证码识别率为70%-90%,复杂验证码识别率为10%-50%,适用场景为无干扰、无扭曲的数字 / 字母验证码。付费的可以用超级鹰。
1.安装 Tesseract-OCR 引擎:
-
- Windows:下载安装包(UB-Mannheim/tesseract),记住安装路径(如
C:\Program Files\Tesseract-OCR\tesseract.exe);
- Linux:
sudo apt install tesseract-ocr;
- Mac:
brew install tesseract。
2.安装 Python 依赖
pip install pytesseract pillow opencv-python requests
import cv2
import numpy as np
import pytesseract
from PIL import Image
import requests
from io import BytesIO
# ---------------------- 配置项 ----------------------
# Windows需指定Tesseract路径,Linux/Mac无需
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
# 验证码图片URL(替换为目标验证码接口)
CAPTCHA_URL = "https://example.com/api/captcha"
# 字符集(仅识别数字+大写字母,提升准确率)
CHAR_WHITELIST = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# ---------------------- 核心函数 ----------------------
def get_captcha_img(url):
"""抓取验证码图片(接口下载,比截图更清晰)"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# 转为PIL图片对象
img = Image.open(BytesIO(response.content))
img.save("captcha_raw.png") # 保存原始图片
return img
def preprocess_img(img_path):
"""图片预处理:去噪、二值化、矫正(核心优化步骤)"""
# 1. 读取图片(OpenCV格式)
img = cv2.imread(img_path)
# 2. 转为灰度图(减少颜色干扰)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 3. 二值化(黑白对比,阈值可调整,127为中间值)
# THRESH_BINARY_INV:反转黑白(字符为白,背景为黑)
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
# 4. 去噪(腐蚀+膨胀,去除细小干扰线)
kernel = np.ones((1, 1), np.uint8) # 核大小,可调整(2,2)增强去噪
erode = cv2.erode(binary, kernel, iterations=1) # 腐蚀
dilate = cv2.dilate(erode, kernel, iterations=1) # 膨胀
# 保存预处理后的图片
cv2.imwrite("captcha_processed.png", dilate)
return dilate
def ocr_captcha(img_path):
"""Tesseract识别验证码"""
# 读取预处理后的图片
img = Image.open(img_path)
# 配置识别参数:
# -c tessedit_char_whitelist:仅识别指定字符
# --psm 8:假设验证码是单个字符块(可调整:6=单行,10=单个字符)
config = f'-c tessedit_char_whitelist={CHAR_WHITELIST} --psm 8'
# 识别文字
text = pytesseract.image_to_string(img, config=config)
# 清洗结果:去空格、换行、制表符
text = text.strip().replace(" ", "").replace("\n", "").replace("\t", "")
return text
# ---------------------- 执行流程 ----------------------
if __name__ == "__main__":
# 1. 抓取验证码图片
get_captcha_img(CAPTCHA_URL)
# 2. 预处理图片
preprocess_img("captcha_raw.png")
# 3. 识别验证码
captcha_text = ocr_captcha("captcha_processed.png")
print(f"原始识别结果:{captcha_text}")
print(f"清洗后结果:{captcha_text}")
- 字符集限制:通过
whitelist只保留需要的字符(如仅数字),过滤无关字符;
- PSM 模式调整:
--psm 6:假设验证码是单行字符(最常用);--psm 8:单个字符块;--psm 10:单个字符(适合 4 位验证码拆分成 4 张图识别);
- 预处理参数调优:
- 二值化阈值:根据验证码亮度调整(如 150、200);
- 核大小:干扰线多则调大
kernel = np.ones((2,2))。
| 验证码类型 |
Code-Type |
适用场景 |
| 通用数字字母 |
1902 |
4-6 位数字 / 字母混合验证码 |
| 汉字验证码 |
9004 |
汉字、点选验证码 |
| 纯数字 |
1004 |
4-6 位纯数字验证码 |
| 滑块验证码 |
2005 |
拼图 / 缺口滑块(返回缺口坐标) |
适合场景:有干扰线、扭曲、汉字、点选的验证码(如抖音 / B 站 / 金融平台验证码)。
- 注册超级鹰账号:https://www.chaojiying.com/;
- 充值点数(1 元≈100 次识别);
- 创建软件 ID(进入「用户中心 - 软件 ID」创建,记录 ID);
- 下载超级鹰 Python SDK:官方下载,将
chaojiying.py放在代码同目录。
import requests
from PIL import Image
from io import BytesIO
from chaojiying import Chaojiying_Client
# ---------------------- 超级鹰配置(替换为自己的) ----------------------
CHAOJIYING_USER = "你的超级鹰用户名" # 账号
CHAOJIYING_PWD = "你的超级鹰密码" # 密码
CHAOJIYING_SOFT_ID = 123456 # 软件ID
CHAOJIYING_CODE_TYPE = 1902 # 验证码类型(1902=通用数字字母,9004=汉字,参考官网文档)
# ---------------------- 核心函数 ----------------------
def get_captcha_img(url):
"""抓取验证码图片(同上,支持接口/截图)"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
img = Image.open(BytesIO(response.content))
img.save("captcha_complex.png")
return img
def chaojiying_ocr(img_path, code_type):
"""调用超级鹰API识别验证码"""
# 初始化超级鹰客户端
cjy = Chaojiying_Client(CHAOJIYING_USER, CHAOJIYING_PWD, CHAOJIYING_SOFT_ID)
# 读取图片二进制数据
with open(img_path, "rb") as f:
img_bytes = f.read()
# 调用识别接口
result = cjy.PostPic(img_bytes, code_type)
# 解析结果
if result["err_no"] != 0:
raise Exception(f"识别失败:{result['err_str']}")
# pic_str:识别出的验证码文字
captcha_text = result["pic_str"].strip()
return captcha_text
# ---------------------- 执行流程 ----------------------
if __name__ == "__main__":
# 1. 抓取复杂验证码图片(替换为目标URL)
CAPTCHA_URL = "https://example.com/api/complex_captcha"
get_captcha_img(CAPTCHA_URL)
# 2. 调用超级鹰识别
try:
captcha_text = chaojiying_ocr("captcha_complex.png", CHAOJIYING_CODE_TYPE)
print(f"超级鹰识别结果:{captcha_text}")
except Exception as e:
print(f"识别出错:{e}")
Beautiful Soup(简称 BS4)爬虫
BS4是 Python 中一个强大的 HTML 和 XML 解析库,它能够从网页中提取数据,处理不规范标记(“-tag soup”),并将复杂的 HTML 文档转换为一个易于遍历的树形结构,方便开发者快速定位和提取所需信息。
-
解析 HTML/XML 文档
支持多种解析器(如 Python 内置的 html.parser、lxml、html5lib 等),能处理不完整或格式混乱的标记。
-
遍历和搜索节点
提供直观的 API 用于查找、遍历 HTML 元素(如标签、属性、文本)。
-
修改文档结构
支持添加、删除、修改标签或属性。
BS4的安装方法:
pip install beautifulsoup4
通常搭配解析器 lxml(速度快,支持 XML)或 html5lib(兼容性好)使用:
pip install lxml # 推荐
# 或
pip install html5lib
实例化Beautiful Soup对象:
#导包
from bs4 import BeautifulSoup
# 解析字符串#本地Html文档加载
#将此Html文档保存为Html文件到本地
"""
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试BS4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="https://song.com" title="赵匡胤" target="_self">
<span>this is span </span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
<a href="" class="du">总为浮动能蔽日,长安不见使人愁</a>
<img src="http://baidu.com/meiny.jpg" alt=""/>
</div>
<div class="tang">
<ul>
<li><a href="http://baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
<li><a href="http://163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不叫胡马度阴山</a></li>
<li><a href="http://126.com" title="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢春</a></li>
<li><a href="http://sina.com" title="du">杜甫</a></li>
<li><a href="http://baidu.com" title="du">杜牧</a></li>
<li><b>杜小月/b></li>
<li><i>度蜜月</i></li>
<li><a href="http://haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴空花草埋幽径,晋代衣冠成古丘</a></li>
</ul>
</div>
</body>
</html>
"""
with open(r"E:\Python code\cls32爬虫\BS4\BS4.html", "r", encoding="utf-8") as fp:
soup = BeautifulSoup(fp, 'lxml') print(soup)
定位查找解析标签和属性的方法:
print(soup.div)#标签定位
print(soup.find('div',class_ = 'tang')) """标签和属性的定位查找
class是Python中的关键字,不能直接作为参数名使用。在Beautiful Soup 中,当需要按类名查找元素时,应该使用class_(后面加一个下划线)来代替class
"""
print(soup.find_all('a')) #定位查找所有包含的标签,返回的是列表。
print(soup.select('.tang'))#选择器定位查找。
print(soup.select('.tang > ul > li > a')[0])#选择器层级定位查找 >表示的是一个层级
print(soup.select('.tang > ul a')[0])#选择器层级定位查找 空格表示的是多个层级,也就是跨层级
获取标签之间的文本数据
print(soup.a.text) #或
print(soup.a.get_text()) #可以获取某个标签中所有的文本内容
print(soup.a.string) #只可以获取该标签下真系的文本内容
print(soup.select('.tang > ul > li a')[0]['href']) #获取标签中的属性值的文本内容
Scrapy框架
Scrapy是由Scrapinghub公司开发的异步爬虫框架,基于Twisted(异步网络引擎)构建,核心目标是「高效、可扩展地爬取网站数据并结构化存储」
- 异步非阻塞:基于 Twisted 事件循环,单进程即可处理高并发请求(比 requests + 多线程效率高 10 倍 +);
- 全流程封装:内置「请求调度、数据解析、去重、持久化、反爬处理」等爬虫核心功能,无需从零封装;
- 结构化解析:内置 XPath/CSS 选择器、正则表达式,轻松提取页面结构化数据(如标题、价格、链接);
- 高度可扩展:支持自定义中间件(处理反爬、代理、Cookie)、管道(处理数据存储)、扩展(监控、日志);
- 通用性强:支持爬取静态网页、动态网页(结合 Splash/Playwright)、API 接口,适配绝大多数场景;
- 内置工具:提供
scrapy shell(调试解析规则)、scrapy crawl(启动爬虫)、scrapy check(校验爬虫)等工具,提升开发效率。
- 大规模数据采集(如电商商品、新闻资讯、社交媒体内容);
- 结构化数据爬取(需提取固定字段,如标题、价格、发布时间);
- 分布式爬虫(结合 Scrapy-Redis 实现多节点协作);
- 定时 / 增量爬虫(仅爬取新增数据)。
Scrapy遵循「组件化设计」,核心组件及数据流向如下:
爬虫发起请求 → Engine(引擎)→ Scheduler(调度器)→ Downloader(下载器)→ 爬虫解析 → Item Pipeline(管道)→ 数据存储
| 组件 |
作用 |
| Engine(引擎) |
核心调度器,协调所有组件工作,是爬虫的 “大脑” |
| Scheduler(调度器) |
接收引擎的请求,按规则排队(去重、优先级),返回给引擎待下载的请求 |
| Downloader(下载器) |
下载网页内容(基于 Twisted 异步下载),返回响应给爬虫 |
| Spider(爬虫) |
核心业务逻辑:定义爬取规则(起始 URL、解析规则),提取数据 / 新请求 |
| Item Pipeline(管道) |
处理爬虫提取的结构化数据(清洗、去重、存储到 MySQL/Redis/CSV 等) |
| Downloader Middlewares(下载中间件) |
拦截请求 / 响应(处理代理、Cookie、User-Agent、反爬验证) |
| Spider Middlewares(爬虫中间件) |
拦截爬虫与引擎之间的交互(处理请求 / 响应的预处理) |
数据流向(关键):
- 爬虫(Spider)定义起始 URL,提交给 Engine;
- Engine 将请求传给 Scheduler 排队;
- Scheduler 取出请求,通过 Engine 传给 Downloader;
- Downloader 下载页面,返回响应(Response)给 Engine;
- Engine 将响应传给 Spider,Spider 解析出「数据(Item)」或「新请求」;
- 数据(Item)传给 Item Pipeline 处理(存储),新请求回到 Scheduler 循环;
- 无新请求时,爬虫结束。
先安装Wheel:是 Python 的一种官方标准预编译软件包格式(.whl)。本质上是一个经过标准化打包的 ZIP 压缩文件,包含了 Python 包运行所需的所有文件(预编译的扩展模块、纯 Python 代码、配置文件等),可直接解压安装,无需本地编译。
# 标准安装(使用系统默认 Python 环境)
pip install wheel
# 阿里云镜像(推荐)
pip install wheel -i https://mirrors.aliyun.com/pypi/simple/
# 清华镜像
pip install wheel -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 豆瓣镜像
pip install wheel -i https://pypi.doubanio.com/simple/
再安装pywin32依赖:是Python访问 Windows API 的核心扩展库,是实现 Windows 系统深度操控的必备工具.功能是覆盖窗口操控、Office自动化、注册表 / 进程 / 服务管理等,核心模块为 win32api、win32gui、win32com.client;深度 Windows 自动化场景(如办公批量处理、窗口控制、系统服务管理),简单场景可选择 pyautogui、xlwings。
# 标准安装(使用系统默认 Python 环境)
pip install pywin32
# 多 Python 环境下,指定 Python 版本安装(如 Python 3.10)
python3 -m pip install pywin32
# 或 Windows 特有
pip3 install pywin32
# 阿里云镜像(推荐)
pip install pywin32 -i https://mirrors.aliyun.com/pypi/simple/
# 清华镜像
pip install pywin32 -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 豆瓣镜像
pip install pywin32 -i https://pypi.doubanio.com/simple/
Twisted是Python生态中最经典的异步网络编程框架,专注于构建高并发、可扩展的网络应用(如服务器、客户端、爬虫、消息队列等),核心基于「事件驱动」和「异步 I/O」模型,能高效处理大量并发连接(比如上万级别的 TCP 连接),且内置了丰富的网络协议实现(TCP/UDP/HTTP/FTP/SMTP 等)。
- 纯异步事件驱动:不同于多线程 / 多进程的 “阻塞式” 并发,Twisted 通过「Reactor 事件循环」处理 I/O 事件(如网络连接、数据读写),避免线程切换开销,单进程即可支撑高并发;
- 一站式网络协议支持:内置 HTTP、TCP、UDP、SSH、SMTP、POP3、IRC 等数十种协议的客户端 / 服务器实现,无需从零封装底层网络交互;
- 跨平台:支持 Windows、Linux、macOS,且兼容 Python 2/3(新版仅支持 Python 3);
- 灵活的编程模型:基于「Deferred(延迟对象)」处理异步回调,替代传统的嵌套回调(避免 “回调地狱”),也支持结合
async/await 语法(新版适配);
- 可扩展:支持自定义协议、插件化架构,适合构建复杂的网络服务(如游戏服务器、代理服务器、分布式爬虫)。
- 高并发 TCP/UDP 服务器(如物联网设备通信、实时消息推送);
- 异步网络客户端(如批量爬虫、多节点监控);
- 自定义协议实现(如私有通信协议的服务器 / 客户端);
- 替代
socket 模块封装复杂网络逻辑(如带重连、超时、心跳的 TCP 连接)。
Twisted 的 “心脏”,是事件循环的核心:
- 负责监听 I/O 事件(如客户端连接、数据到达);
- 当事件触发时,调用预先注册的回调函数处理;
- 常用操作:
reactor.run() 启动事件循环,reactor.stop() 停止循环。
处理异步结果的核心工具,替代传统回调:
- 异步操作(如网络请求)返回
Deferred 对象,通过 addCallback() 注册 “成功回调”,addErrback() 注册 “异常回调”;
- 避免嵌套回调,支持链式调用(类似 Promise)。
Protocol:定义网络交互的逻辑(如 dataReceived() 处理收到的数据,connectionMade() 处理连接建立);Factory:用于创建 Protocol 实例(每建立一个客户端连接,Factory 就生成一个 Protocol 实例处理该连接)。
# 基础安装(Windows/Linux/macOS通用)
pip install scrapy
# 国内镜像加速
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
# Windows 若报错(缺少Twisted),先装Twisted预编译包(参考之前Twisted安装),再装Scrapy
安装Twisted
# 基础安装(最新稳定版)
pip install twisted
# 国内用户建议用镜像源加速(避免下载超时)
pip install twisted -i https://pypi.tuna.tsinghua.edu.cn/simple
# 若需指定版本(如适配旧项目)
pip install twisted==22.10.0 # 推荐稳定版,兼容Python 3.7+
pip install twisted==20.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
import twisted
print(twisted.__version__) # 打印Twisted版本号,如 25.5.0
(快速上手)示例1:简单的 TCP 服务器
from twisted.internet import reactor, protocol
# 定义协议:处理客户端连接和数据
class EchoProtocol(protocol.Protocol):
# 客户端连接建立时触发
def connectionMade(self):
print(f"客户端 {self.transport.getPeer()} 已连接")
# 收到客户端数据时触发
def dataReceived(self, data):
# 回显数据(Echo服务器)
self.transport.write(f"服务器收到:{data.decode('utf-8')}".encode('utf-8'))
# 若收到"quit",关闭连接
if data.decode('utf-8').strip() == "quit":
self.transport.loseConnection()
# 连接断开时触发
def connectionLost(self, reason):
print(f"客户端 {self.transport.getPeer()} 断开连接")
# 定义工厂:创建Protocol实例
class EchoFactory(protocol.Factory):
def buildProtocol(self, addr):
return EchoProtocol()
# 启动TCP服务器,监听8000端口
if __name__ == "__main__":
reactor.listenTCP(8000, EchoFactory())
print("TCP Echo服务器启动,监听8000端口...")
reactor.run() # 启动事件循环
from twisted.internet import reactor, defer
from twisted.web.client import Agent, readBody
from twisted.web.http_headers import Headers
from twisted.internet.ssl import ClientContextFactory
from OpenSSL import SSL
# 简化SSL上下文(忽略警告,仅保证功能)
class SimpleSSLContext(ClientContextFactory):
def getContext(self, hostname=None, port=None):
ctx = SSL.Context(SSL.TLS_CLIENT_METHOD)
ctx.set_verify(SSL.VERIFY_NONE, lambda conn, cert, errno, depth, ok: True)
return ctx
# 核心请求函数
def http_get(url):
agent = Agent(reactor, contextFactory=SimpleSSLContext())
d = agent.request(b"GET", url.encode("utf-8"), Headers({b"User-Agent": [b"Mozilla/5.0"]}), None)
d.addCallback(lambda resp: readBody(resp))
return d
# 回调+启动
if __name__ == "__main__":
d = http_get("https://www.baidu.com")
d.addCallback(lambda data: (print(data.decode()[:200]), reactor.stop()))
d.addErrback(lambda err: (print(err), reactor.stop()))
reactor.run()
scrapy version --verbose :是 Scrapy 框架提供的一个 命令行工具命令,用于 查看当前环境中 Scrapy 的详细版本信息和依赖库状态。
运行该命令后,会输出:
- Scrapy 的版本号
- Python 版本
- 操作系统信息
- 所有关键依赖库(如 Twisted、lxml、cssselect、parsel、w3lib 等)的版本
- 安装路径等调试信息
这对于排查环境问题、提交 bug 报告、确认兼容性 非常有用。

# 创建项目(项目名:douban_top250)
scrapy startproject douban_top250
# 进入项目目录
cd douban_top250
# 创建爬虫(爬虫名:top250,爬取域名:douban.com)
scrapy genspider douban_spider movie.douban.com
douban_top250/
├── douban_top250/ # 核心配置目录
│ ├── __init__.py
│ ├── items.py # 定义结构化数据字段(如电影名称、评分)
│ ├── middlewares.py # 下载/爬虫中间件(反爬、代理)
│ ├── pipelines.py # 数据处理管道(存储到MySQL/CSV)
│ ├── settings.py # 全局配置(请求延迟、User-Agent、管道开关)
│ └── spiders/ # 爬虫脚本目录
│ ├── __init__.py
│ └── douban_top250.py # 核心爬虫脚本(定义爬取/解析规则)
└── scrapy.cfg # 项目部署配置
import scrapy
class DoubanTop250Item(scrapy.Item):
rank = scrapy.Field() # 排名
title = scrapy.Field() # 电影名
rating = scrapy.Field() # 评分
link = scrapy.Field() # 链接
quote = scrapy.Field() # 引言(经典台词)
步骤5:编写 Spider 爬虫逻辑
编辑 spiders/douban_spider.py:
import scrapy
from douban_top250.items import DoubanTop250Item
class DoubanSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
custom_settings = {
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36'
}
def parse(self, response):
for movie in response.css('ol.grid_view li'):
item = DoubanTop250Item()
item['rank'] = movie.css('em::text').get()
item['title'] = movie.css('.title::text').get()
item['rating'] = movie.css('.rating_num::text').get()
item['link'] = movie.css('.pic a::attr(href)').get()
item['quote'] = movie.css('.inq::text').get()
yield item
# 翻页
next_page = response.css('.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
步骤6:配置输出格式(可选)
在 settings.py 中添加(保存为 CSV或JSON格式):
FEEDS = {
'douban_top250.csv': {
'format': 'csv',
'encoding': 'utf-8',
'overwrite': True,
}
}
步骤7:运行爬虫
在项目根目录执行:
scrapy crawl douban_spider
爬取结果将自动保存到 douban_top250.csv或douban_top250.json
步骤8:扩展建议(可选)
- 存入数据库(MongoDB / MySQL)→ 编写
pipelines.py
- 使用
scrapy-rotating-proxies + scrapy-user-agents 应对更强反爬
- 添加日志记录和异常重试机制
Setting.py:全局配置文件,用于控制爬虫的行为、性能、反爬策略、数据管道等。合理的设置能显著提升爬取成功率和稳定性。
1.基础必要设置(几乎每次都要配)
①.User-Agent(防403)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36'
豆瓣、知乎等网站会拦截默认 Scrapy UA,必须修改。
②.请求延迟(防封IP)
DOWNLOAD_DELAY = 1 # 每次请求间隔1秒
RANDOMIZE_DOWNLOAD_DELAY = 0.5 # 在0.5~1.5秒间随机延迟(默认开启)
避免被识别为机器人,尤其对小网站或严格反爬站点。
③.是否遵守 robots.txt
ROBOTSTXT_OBEY = False # 默认 True,但很多网站的 robots.txt 会禁止爬虫
生产环境建议设为 False(除非你明确要遵守)。
2.反爬与请求增强
④.自动限速(AutoThrottle)——推荐开启
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1
AUTOTHROTTLE_MAX_DELAY = 10
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
Scrapy 会根据响应时间动态调整请求频率,智能防封。
⑤.启用 Cookies(如需登录状态)
COOKIES_ENABLED = True # 默认 True,但有些场景需关闭(如避免会话跟踪)
⑥.设置请求头(Headers)
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
补充 Accept、Language 等字段,更像真实浏览器。
3.数据输出与格式
⑦.导出数据格式(Feed Export)
FEEDS = {
'results.json': {
'format': 'json',
'encoding': 'utf-8',
'overwrite': True, # 覆盖旧文件
},
# 或导出 CSV
# 'results.csv': {'format': 'csv', 'overwrite': True},
}
替代命令行 -o 参数,支持多格式、压缩、自定义字段等。
4.pipeline.py(中间件与管道)
⑧.启用 Item Pipeline(处理数据)
ITEM_PIPELINES = {
'myproject.pipelines.DuplicatesPipeline': 300,
'myproject.pipelines.SaveToMySQLPipeline': 400,
}
数字越小优先级越高。用于去重、清洗、存数据库等。
⑨.启用自定义中间件(可选)
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.RandomUserAgentMiddleware': 543,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None, # 禁用默认重试
}
可用于随机 UA、代理 IP、JS 渲染等。
5.并发与性能调优
⑩.并发请求数
CONCURRENT_REQUESTS = 16 # 全局最大并发
CONCURRENT_REQUESTS_PER_DOMAIN = 8 # 每个域名最大并发
CONCURRENT_REQUESTS_PER_IP = 0 # 若按IP限制,设为 >0
小网站建议降低(如 2~4),大站可适当提高。
⓫.超时与重试
DOWNLOAD_TIMEOUT = 15
RETRY_TIMES = 3
RETRY_HTTP_CODES = [500, 502, 503, 504, 408, 429]
6.其他实用设置
⓬.日志级别(调试用)
LOG_LEVEL = 'INFO' # 可选:DEBUG, INFO, WARNING, ERROR,CRITICAL (必须是大写)
#如果你只是想减少日志输出,也可以设置为:WARNING,推荐,会隐藏 DEBUG 和 INFO
#完全关闭日志(不推荐):False
# LOG_FILE = 'scrapy.log' # 输出到文件
⓭.关闭 Telnet 控制台(安全)
TELNETCONSOLE_ENABLED = False
⓮.禁用 Referer(某些网站校验)
🚫 常见错误配置
| 错误 |
后果 |
忘记改 USER_AGENT |
被返回 403 Forbidden |
DOWNLOAD_DELAY=0 + 高并发 |
很快被封 IP |
重写了 CrawlSpider 的 parse() 方法 |
导致 rules 失效 |
| ROBOTSTXT_OBEY=True |
可能无法爬任何页面 |
| 页面结构变动 |
豆瓣可能更新 HTML 结构,需检查选择器是否仍有效(建议用浏览器开发者工具验证 CSS/XPath) |
✅ 推荐模板(通用版)
# settings.py
BOT_NAME = 'my_spider'
SPIDER_MODULES = ['myproject.spiders']
NEWSPIDER_MODULE = 'myproject.spiders'
ROBOTSTXT_OBEY = False
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36'
DOWNLOAD_DELAY = 1
CONCURRENT_REQUESTS_PER_DOMAIN = 4
FEEDS = {
'output.json': {'format': 'json', 'overwrite': True}
}
ITEM_PIPELINES = {
# 'myproject.pipelines.MySQLPipeline': 300,
}
# AUTOTHROTTLE_ENABLED = True # 可选开启
pipeline.py(中间件与管道):是用于 处理爬取到的 Item(数据) 的核心组件。它通常负责:数据清洗、去重、验证、存储(如保存到文件、数据库、API 等)。
是否需要配置 pipelines.py 取决于你的需求。如果你只是用 scrapy crawl xxx -o data.json 导出数据,可以不用写 Pipeline;但一旦涉及去重、存数据库、复杂处理,就必须使用。
1.Pipeline 的基本结构
每个 Pipeline 是一个 Python 类,必须实现 process_item(self, item, spider) 方法。
# pipelines.py 示例
class MyPipeline:
def process_item(self, item, spider):
# 处理 item
return item # 必须返回 item 或抛出 DropItem 异常
2.常见 Pipeline 功能及代码示例
①.数据清洗与标准化
class CleanDataPipeline:
def process_item(self, item, spider):
if item.get('title'):
item['title'] = item['title'].strip()
if item.get('rating'):
item['rating'] = float(item['rating'])
return item
②.去重(防止重复数据)
from scrapy.exceptions import DropItem
class DuplicatesPipeline:
def __init__(self):
self.seen_titles = set()
def process_item(self, item, spider):
title = item.get('title')
if title in self.seen_titles:
raise DropItem(f"Duplicate item found: {title}")
self.seen_titles.add(title)
return item
💡 更高效的方式:用 Redis 或数据库做持久化去重。
3.保存到 JSON / CSV 文件(不推荐,Scrapy 内置更优)
一般用 FEEDS 配置即可,无需手写。
FEEDS = {
'douban_top250.csv': {
'format': 'Csv',
'encoding': 'utf-8',
'overwrite': True,
}
}
4.保存到 MySQL(常用)
import pymysql
class MySQLPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='scrapy_db',
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
self.conn.close()
def process_item(self, item, spider):
sql = """
INSERT INTO movies (rank, title, rating, link, quote)
VALUES (%s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['rank'],
item['title'],
item['rating'],
item['link'],
item['quote']
))
self.conn.commit()
return item
🔐 安全建议:使用连接池或 ORM(如 SQLAlchemy)。
5.保存到 MongoDB
import pymongo
class MongoPipeline:
def open_spider(self, spider):
self.client = pymongo.MongoClient('mongodb://localhost:27017/')
self.db = self.client['scrapy_db']
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db.movies.insert_one(dict(item))
return item
. 图片/文件下载(配合 FilesPipeline / ImagesPipeline)
Scrapy 内置了:
scrapy.pipelines.files.FilesPipelinescrapy.pipelines.images.ImagesPipeline
你只需继承并配置:
from scrapy.pipelines.images import ImagesPipeline
class MyImagesPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None, *, item=None):
return f"{item['title']}.jpg"
并在 settings.py 中设置:
ITEM_PIPELINES = {
'myproject.pipelines.MyImagesPipeline': 1,
}
IMAGES_STORE = './images'
3.启用 Pipeline(关键!)
即使写了 pipelines.py,也必须在 settings.py 中启用:
# settings.py
ITEM_PIPELINES = {
'myproject.pipelines.DuplicatesPipeline': 300,
'myproject.pipelines.MySQLPipeline': 400,
}
- 键:完整类路径(
项目名.pipelines.类名)
- 值:优先级(数字越小越先执行)
📌 如果不配置 ITEM_PIPELINES,Pipeline 不会生效!
💫在Pipelines中也可以存储文件
class YouxiPipeline:
def process_item(self, item, spider):
# 分别安全地获取每个字段的值
name = item.get("name", "")
url = item.get("url", "")
category = item.get("category", "")
# 将所有值转换为字符串并拼接(例如用逗号分隔)
line = f"{name},{url},{category}\n"
with open("games.csv", "a", encoding="utf-8") as f:
f.write(line)
4.高级技巧
①.根据 Spider 启用不同 Pipeline
def process_item(self, item, spider):
if spider.name == 'douban':
# 只处理豆瓣爬虫的数据
...
return item
②.异步存储(如用 asyncio + aiomysql)
适用于高并发场景,但需自定义。
③.批量插入(提升性能)
不要每条 item 都 commit,可缓存 N 条后批量写入。
❌ 常见错误
| 错误 |
后果 |
忘记在 settings.py 中注册 Pipeline |
数据不处理、不存储 |
process_item 没有 return item |
后续 Pipeline 中断 |
| 数据库连接未关闭 |
资源泄漏 |
在 __init__ 中建立数据库连接 |
多进程/多线程下可能出错(应使用 open_spider) |
CrawlSpiders:是 Scrapy 框架中提供的一种 专门用于自动跟踪链接(link following)的爬虫基类,它继承自普通的 Spider 类,但增加了 自动发现和跟进页面链接的能力,非常适合用于全站爬取、分页抓取、目录遍历 等场景。
🧩 一、CrawlSpider 的核心特点
| 特性 |
说明 |
| ✅ 自动提取链接 |
通过定义 Rule 规则,自动从响应中提取符合规则的 URL |
| ✅ 自动发起请求 |
对提取到的链接自动发送新的 Request |
| ✅ 支持回调函数 |
可为不同规则指定不同的解析回调函数(如 parse_item) |
| ✅ 避免重复抓取 |
内置去重机制(依赖 Scrapy 的 DUPEFILTER) |
| ❌ 不适合静态列表页 |
如果只是抓取固定几页(如 Top250),用普通 Spider 更简单 |
💡 简单说:CrawlSpider = Spider + 自动翻页/跳转逻辑
🛠️ 二、基本使用结构
要使用 CrawlSpider,需:
- 继承
scrapy.spiders.CrawlSpider
- 定义
rules 属性(类型为 tuple,包含一个或多个 Rule 对象)
- 实现具体的解析回调方法(如
parse_item)
示例模板:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from myproject.items import MyItem
class MyCrawlSpider(CrawlSpider):
name = 'my_spider'
allowed_domains = ['example.com']
start_urls = ['https://example.com/start']
rules = (
# 规则1:提取列表页中的详情页链接,并用 parse_item 处理
Rule(LinkExtractor(allow=r'/item/\d+'), callback='parse_item', follow=False),
# 规则2:继续跟进分页链接(不回调,只跟进)
Rule(LinkExtractor(allow=r'page=\d+'), follow=True),
)
def parse_item(self, response):
item = MyItem()
item['title'] = response.css('h1::text').get()
return item

创建Crawl Spider
scrapy startproject XXX
scrapy genspider -t crawl XXX xxx.com #与scrapy不同的是多了 -t crawl命令参数
🔍 三、关键组件详解
1. LinkExtractor(链接提取器)
用于从 HTML 中提取符合规则的链接。
常用参数:
allow: 正则表达式,匹配要提取的 URL(如 r'/movie/\d+')deny: 排除某些 URLrestrict_xpaths: 限定在某个 XPath 范围内提取(如 //div[@class="content"]//a)restrict_css: 类似 restrict_xpaths,但用 CSS 选择器
LinkExtractor(allow=r'/subject/\d+', restrict_css='.item a')
2. Rule(规则):定义如何处理提取到的链接。
| 参数 |
作用 |
| link_extractor |
必填,指定 LinkExtractor 实例 |
| callback |
可选,处理该链接响应的函数名(字符串) |
| follow |
是否继续从该页面提取新链接(默认:True 如果没设 callback,否则 False) |
| process_links |
自定义处理提取到的链接列表(如去重、过滤) |
| process_request |
自定义修改 Request(如添加 headers、meta) |
⚠️ 注意:如果设置了 callback,默认 follow=False
如果你想既解析页面又继续跟进链接,必须显式写 follow=True
抓取起始(1)页数据:
def parse_start_url(self,response,**kwargs)
print(response)
📌 四、典型应用场景
场景 1:爬取新闻网站所有文章
- 列表页:
https://news.example.com/page=1
- 详情页:
https://news.example.com/article/12345
rules = (
Rule(LinkExtractor(allow=r'article/\d+'), callback='parse_news'),
Rule(LinkExtractor(allow=r'page=\d+'), follow=True),
)
场景 2:电商商品全站爬取
rules = (
Rule(LinkExtractor(restrict_css='.category a'), follow=True), # 进入分类
Rule(LinkExtractor(restrict_css='.product-item a'), callback='parse_product'), # 商品详情
)
⚠️ 五、注意事项与常见误区
❌ 误区 1:重写 parse() 方法
CrawlSpider 的 parse() 方法已被内部占用!
如果你写了下面代码会导致 rules 失效!
def parse(self, response): # ❌ 不要重写!
...
✅ 正确做法:不要定义 parse 方法,用其他名字如 parse_item、parse_detail。
❌ 误区 2:callback 和 follow 冲突
Rule(LinkExtractor(allow=r'/post/\d+'), callback='parse_post')
# 默认 follow=False,不会继续从 post 页面提取新链接
❌ 误区 3:正则写错导致漏抓
allow=r'/\d+' 可能匹配到 /123、/abc/456,不够精确- 建议用更具体的模式:
r'/movie/\d+\.html'
✅ 六、何时用 CrawlSpider?何时用普通 Spider?
| 场景 |
推荐 |
| 固定几页(如豆瓣 Top250) |
✅ 普通 Spider(手动翻页) |
| 全站爬取、未知深度 |
✅ CrawlSpider |
| 需要复杂登录/JS 渲染 |
❌ 两者都不适合,考虑 Selenium + Scrapy |
| 只抓首页数据 |
✅ 普通 Spider |
Selector对象提取数据:从 HTML 或 XML 文档中提取数据的核心工具。它基于 parsel 库(Scrapy 内置),支持 XPath 和 CSS 选择器。
提取数据的 4 种核心方法
| 方法 |
返回类型 |
是否推荐 |
说明 |
| .get() |
str / None |
✅ 强烈推荐 |
Scrapy 1.0+ 标准 |
| .extract_first() |
str / None |
⚠️ 旧版兼容 |
功能同 .get() |
| .getall() |
list[str] |
✅ 推荐 |
替代 .extract() |
| .extract() |
list[str] |
❌ 不推荐 |
旧版,语义不清 |
📌 官方文档已建议使用 .get() 和 .getall()
示例
def parse(self, response):
for li in response.xpath("//ul[@class='tm_list']/li"):
name = li.xpath("./a/text()").get() # 游戏名
url = li.xpath("./a/@href").get() # 链接
category = li.xpath("./em/text()").get() # 分类
yield {
'name': name.strip() if name else '',
'url': response.urljoin(url) if url else '',
'category': category
}
yield:将一个普通函数转变为“生成器函数”(generator function),使得该函数可以逐个返回值、暂停并恢复执行状态,而不是一次性返回所有结果,适合处理大数据,比return好。
| 特性 |
return |
yield |
| 返回次数 |
只能返回一次 |
可多次 yield 多个值 |
| 函数状态 |
执行完就销毁 |
暂停后可恢复 |
| 返回类型 |
具体值(如 int, str) |
生成器对象(Generator) |
| 内存占用 |
一次性生成全部数据 |
按需生成,节省内存 |
★导入新建的Python File文件.py并调用和执行的方法
在项目第一层目录新建.Py文件并写入以下代码:
from scrapy.cmdline import execute
if __name__ == '__main__':
execute("scrapy crawl XXX".split())
#右键运行
#crawl后面XXX是项目文件.py中name属性里的值
#此方法是用来测试和调试爬虫项目用的,代替了scrapy crawl XXX


Pytest框架:用于编写简单到复杂的函数测试、单元测试、集成测试和端到端测试。
✅ 优势:
- 语法简洁,无需继承
unittest.TestCase
- 自动发现测试函数(以
test_ 开头)
- 强大的 Fixture 机制(替代
setup/teardown)
- 支持参数化测试
- 丰富的插件生态(如
pytest-html, pytest-cov, pytest-playwright)
- 与 CI/CD(GitHub Actions、Jenkins 等)无缝集成
Pytest安装
验证安装
pytest --version
# pytest 9.02
pip install pytest -U
# 升级pytest
💡不需要单独安装 unittest,Pytest 可运行 unittest 风格的测试。
1.创建测试基本要求:
必须以test_开头,assesrt断言,不可自定义参数和返回值
- 测试文件名:
test_*.py 或 *_test.py
- 测试函数名:必须以
test_ 开头
def test_yonge():
a = 1
b = 2
assert 1 >=2
2.执行框架:
#创建一个main.py文件打开写入以下代码
import pytest
if __name__ == "__main__":
pytest.main()#启动test 测试框架
main.py执行的结果:

3.assert断言
Pytest 使用原生 assert,失败时会智能显示差异,失败时会高亮,显示值差异。
def test_list():
assert [1, 2, 3] == [1, 2, 4] # 失败时会高亮 3 vs 4
def test_dict():
assert {"a": 1} == {"a": 2} # 显示 key "a" 的值差异
Pytest执行结果分为以下几个部分:
- 执行环境:操作系统、Python版本、Pytest版本
- 执行过程:根目录、实例收集情况、实例名称、实例执行进度和执行结果
- 失败详情:实例名称、实例内容、变量内容、断言提示
- 整体摘要:结果数量 、花费时间、失败的文件和实例
Pytest执行的结果:

Pytest场景结果缩写:
| 缩写 |
单词 |
含义 |
| . |
passed |
通过 |
| F |
failed |
失败 |
| E |
error |
错误 |
| s |
skipped |
跳过 |
| X |
Xpassed |
意外通过 |
| x |
Xfailed |
预期失败 |
4.实例发现规则:Pytest识别、加载实例的过程称之为实例发现。具体规则如下:
- 遍历所有的目录(venv和.开头除外)
- 加载符合要求的文件(test_开头或者_test结尾)
- 遍历符合要求的类class(Test开头且没有__int__)
- 收集符合要求的函数或者方法(test开头)
Pytest核心利器(Fixture夹子或称之为夹具)
①.Fixture:在实例执行之前、执行之后自动运行代码(准备、请求动作)。
场景:
- 之前:启动浏览器 之后:关闭浏览器
- 之前:连接数据库 之后:关闭数据库连接
- 之前:注册账号 之后:删除账号
②.创建Fixture
- 创建一个函数(不要test开头)
- 添加装饰器(@pytest.fixture)
- 添加关键字(yield)
import pytest
@pytest.fixture
def func():
print("之前:在用例执行前")
yield 123 #返回值
print("之后:在用例执行后")
③.请求Fixture:请求框架调用fixture,并返回结果。
- 把fixture名字写在实例参数列表(可以接收结果) 💖推荐使用!
- 使用@pytest.mark.usefixtures标记(不可以接收结果)
- 不允许直接调用fixtures
import pytest
@pytest.fixture
def db_connection():
print("【连接数据库】")
conn = "mock_db_connection"
yield conn
print("【关闭数据库】")
def test_user_query(db_connection):
assert db_connection == "mock_db_connection"
请求Fixture自动化实例
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import pytest
@pytest.fixture
def driver():
# 启动浏览器
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()yield driver
# 关闭浏览器
driver.quit()
def test_baidu_search_pytest(driver):
search_box = driver.find_element(By.XPATH, '//*[@id="chat-textarea"]')
search_box.clear()
search_box.send_keys("pytest")
search_box.send_keys(Keys.ENTER)
# 等待搜索结果加载
time.sleep(2)
# 验证:页面中包含 "pytest"(更可靠)
assert "pytest" in driver.page_source.lower()
# 可选:验证标题
# assert "pytest" in driver.title.lower()
④.Fixture作用域:它是通过定义来进行控制
pytest支持五级作用域
| Scope(域&范围) |
说明 |
| function(函数 默认) |
每个测试函数调用一次 |
| class(类) |
每个测试类调用一次 |
| module(模块&文件) |
每个模块(.py 文件)调用一次 |
| package(目录&包) |
在同一个目录中,不会重复执行 |
| session(全局&会话) |
整个测试会话只调用一次 |
@pytest.fixture(scope="session")
def browser():
print("启动浏览器(整个测试只启动一次)")
yield "chromium"
print("关闭浏览器")
自动使用(autouse):所有测试都会自动执行此 fixture。
@pytest.fixture(autouse=True)
def log_test_start():
print("\n--- 开始测试 ---")
yield
print("--- 结束测试 ---")
⑤.Fixture参数化测试(Parametrize):谨慎使用,优先考虑使用mark实现参数化
避免重复写相似测试:会生成 4 个独立测试用例,任一失败不影响其他。
# test_add.py
def add(a, b):
"""被测试的函数"""
return a + b
import pytest
@pytest.mark.parametrize("a, b, expected", [
(2, 3, 5),
(0, 0, 0),
(-1, 1, 0),
(100, -50, 50),
])
def test_add_param(a, b, expected):
assert add(a, b) == expected
⑥.conftest.py:跨文件共享fixture,能实现自动发现和加载fixture。
#建议在根目录创建conftest.py文件。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pytest
@pytest.fixture
def driver():
# 启动浏览器
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()yield driver
# 关闭浏览器
driver.quit()
⚠️


 浙公网安备 33010602011771号
浙公网安备 33010602011771号