


30分钟上手Web自动化测试:Python+Selenium零基础实战指南
前言
在数字化转型加速的今天,Web UI自动化测试已成为提升开发效率、保障产品质量的关键技能。本文专为初学开发者设计,从零开始手把手带你搭建环境、掌握核心技能,最终实现完整的自动化测试流程。无需编程经验,只需跟随步骤操作,你将学会:
-
快速部署Python和PyCharm开发环境,避开新手常见配置陷阱;
-
灵活运用Selenium框架,精准定位网页元素(按钮、输入框等),实现自动化交互;
-
实战脚本解析,以“百度搜索”为例,7行代码解锁自动化测试核心逻辑;
-
八大元素定位技巧,覆盖ID、XPath、CSS等策略,解决动态组件、加载延迟等难题。
无论你是测试工程师、开发者,还是希望提升效率的技术爱好者,本文均能助你30分钟内跑通第一个自动化脚本,用技术解放重复劳动!
快速上手Web UI自动化测试开发。我们将从环境搭建开始,逐步安装Python编程语言、PyCharm开发工具和Selenium浏览器自动化框架。掌握基础配置后,会重点演示如何通过元素定位技术获取网页按钮、输入框等关键组件,我们现在开始进入web网页UI自动化的流程:
一,先安装Python和客户端Pcharm
1、安装Python环境
a、在官网去下载python:https://www.python.org/downloads/ 在官网下载时,根据自己电脑的操作系统选择对应版本即可,
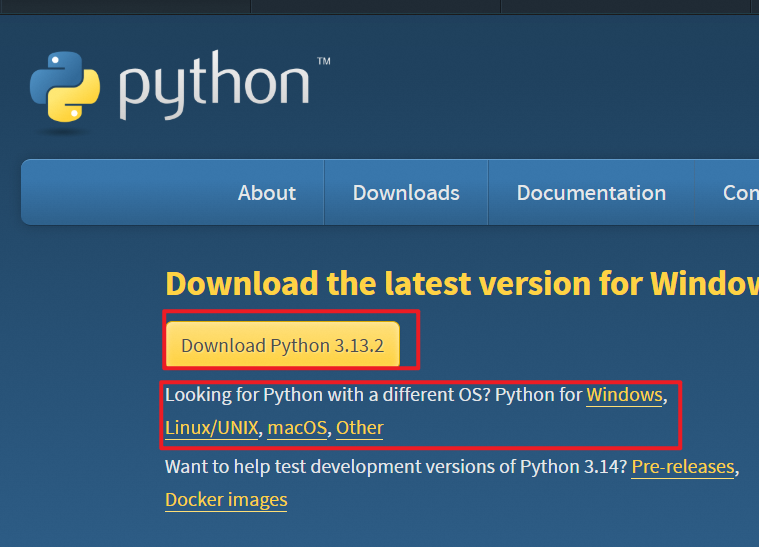
b、值得注意的是,在下载完成,正式安装的时候,尽量选择自定义安装:安装到非C盘,或者非系统文件夹。并且勾选将python添加到path环境变量,这样就不用再手动去电脑的高级设置中去配置环境变量了,其他就是一直点下一步就行,没什么需要特殊管的,具体如下图。

c、安装完成以后在cmd窗口中中,只要能像下图一样,输入python进入交互式环境,即代表安装成功,如果没有,先检查环境变量。

2、安装PyCharm
a、官网地址:https://www.jetbrains.com/pycharm/download/?section=windows
需要需要:下载页面,往下翻,下载社区版本:PyCharm Community Edition。免费的,足够日常使用了。

b、下载完成以后,一样,安装路径尽量自己去单独创建一个新的文件夹存放,以后写的代码也会直接保存到创建的文件夹中。且也需勾选创建环境变量。剩下的就是一直点下一步即可。

二:安装对应的框架。
1、打开PyCharm终端
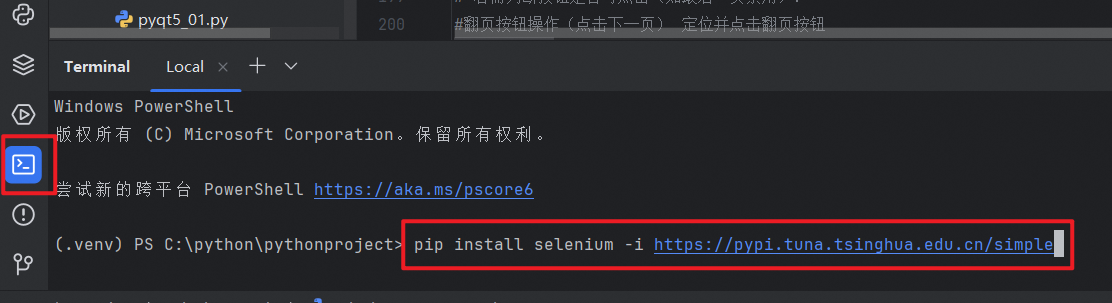
点击底部 Terminal 标签页,输入以下命令:
pip install selenium
若下载缓慢,可附加国内镜像源地址:指定镜像源加速下载
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
2、安装浏览器驱动
-华为镜像云下载地址:进入网站后,直接按照自己浏览器的版本号去找对应或者接近的版本即可:
Chrome浏览器驱动:https://mirrors.huaweicloud.com/chromedriver/
FireFox浏览器的驱动: https://mirrors.huaweicloud.com/geckodriver/
Opera浏览器引擎驱动:https://mirrors.huaweicloud.com/operadriver/
下载好以后,解压到电脑的本地地址,后续的代码中会用到。
三:UI自动化脚本实操
我们写了一个最简单的代码,一共7行,用来实现,使用Python,驱动浏览器打开百度的首页,并搜索关键词:“娃哈哈”。可以直接借鉴使用。
# 导入Selenium的webdriver模块,用于控制浏览器 from selenium import webdriver # 从webdriver.chrome.service模块导入Service类,用于指定ChromeDriver的路径 from selenium.webdriver.chrome.service import Service # 初始化浏览器对象 # webdriver.Chrome()用于创建一个Chrome浏览器的实例 # service=Service(executable_path='D:\\chromedriver.exe')指定了ChromeDriver的路径 # ChromeDriver是Selenium用于与Chrome浏览器通信的独立服务器 driver = webdriver.Chrome(service=Service(executable_path='D:\\chromedriver.exe')) # 使用driver对象的get方法打开指定的网页 # 此处打开的是百度首页 driver.get('https://www.baidu.com') # 或者其他任何网站 # 执行搜索操作 # driver.find_element()方法用于在网页中查找元素 # 第一个参数是定位元素的策略,此处使用'name'策略 # 'wd'是百度搜索框的name属性值 # send_keys()方法用于模拟在输入框中输入文本 # 此处输入的是'娃哈哈' driver.find_element('name', 'wd').send_keys('娃哈哈') # 再次使用driver.find_element()方法查找元素 # 此次使用'id'策略,'su'是百度搜索按钮的id属性值 # click()方法用于模拟鼠标点击操作 # 此处点击的是搜索按钮 driver.find_element('id', 'su').click() # 使用input函数等待用户输入 # 这里的提示信息是"按回车键关闭浏览器..." # 当用户按下回车键时,input函数返回,程序继续执行下面的代码 # 下面的代码(未给出)通常会包含driver.quit()用于关闭浏览器和结束ChromeDriver进程 input("按回车键关闭浏览器...")
四:元素的定位以及使用
一、什么是元素?
在Web自动化中,元素(Web Element) 是网页的构成单元,对应HTML文档中的标签(Tag)及其内容。每个元素可以是以下任意一种:
可见组件:如输入框、按钮、链接、图片、下拉框等。
不可见组件:如隐藏的<input>、<div>容器、元数据标签(如<meta>)。
动态内容:通过JavaScript生成的元素(如弹窗、异步加载的列表)。
元素的核心属性:
标签名:如<input>, <a>, <div>。
属性:如id, name, class, href, value等。
内容:标签内的文本(如<button>提交</button>中的“提交”)。
我们现在,在浏览器F12工具中,来观察一下百度输入框的元素,先打开F12工具,在选项卡中选择“元素”,然后点击左上角的定位工具,然后鼠标点击输入框,即可查看输入框的元素信息。如下图:
这个输入框,我们可以用id定位器来定位,value为kw,也可以用name定位器,value为wd,当然也可用class定位器。
具体的实操,大家可以都尝试一下。

二、元素定位的核心方法
以下是8种常用定位策略,按优先级和效率排序:
1. 通过id定位
语法:
find_element(By.ID, "id_value")
原理:id是HTML元素的唯一标识符。
示例:
<input id="username" type="text"> #HTML代码
driver.find_element(By.ID, "username").send_keys("test") #在python中实际用法
优点:定位速度最快,且唯一性高。
缺点:部分网站动态生成id(如含随机字符串)。
2. 通过name定位
语法:
find_element(By.NAME, "name_value")
示例:
<input name="password" type="password">
driver.find_element(By.NAME, "password").send_keys("123456")
适用场景:表单元素常用name属性。
3. 通过class name定位
语法:
find_element(By.CLASS_NAME, "class_value")
注意:若class有多个值(如class="btn btn-primary"),需完全匹配其中一个。
示例:
<button class="submit-btn">登录</button>
driver.find_element(By.CLASS_NAME, "submit-btn").click()
4. 通过tag name定位
语法:
find_element(By.TAG_NAME, "tag_name")
适用场景:定位特定标签(如<table>, <img>)。
示例:
<img src="logo.png" alt="Logo">
image = driver.find_element(By.TAG_NAME, "img")
5. 通过link text定位超链接
语法:
find_element(By.LINK_TEXT, "链接文本")
示例:
<a href="/about">关于我们</a>
driver.find_element(By.LINK_TEXT, "关于我们").click()
6. 通过partial link text模糊匹配链接
语法:
find_element(By.PARTIAL_LINK_TEXT, "部分文本")
示例:
<a href="/contact">联系我们-2023</a>
driver.find_element(By.PARTIAL_LINK_TEXT, "联系").click()
7. 通过XPath定位
语法:
find_element(By.XPATH, "xpath表达式")
核心语法:
//:从任意位置搜索
[@attribute='value']:按属性过滤
/或//:层级关系
示例:
<div class="header"> <input id="search" placeholder="输入关键词"> </div>
# 绝对路径(不推荐) driver.find_element(By.XPATH, "/html/body/div/input") # 相对路径 + 属性 driver.find_element(By.XPATH, "//input[@id='search']") # 文本匹配 driver.find_element(By.XPATH, "//button[text()='提交']") # 包含部分属性值 driver.find_element(By.XPATH, "//input[contains(@class, 'search-input')]")
优点:灵活性极高,支持复杂逻辑。
缺点:性能略低,路径易受页面结构变化影响。
8. 通过CSS Selector定位
语法:
find_element(By.CSS_SELECTOR, "css选择器")
核心语法:
#id:按id选择
.class:按class选择
[attribute=value]:按属性选择
>:直接子元素
示例:
<ul class="menu"> <li><a href="/home">首页</a></li> </ul>
# 按class选择 driver.find_element(By.CSS_SELECTOR, ".menu") # 层级选择 driver.find_element(By.CSS_SELECTOR, "ul.menu > li > a") # 属性选择 driver.find_element(By.CSS_SELECTOR, "a[href='/home']")
优点:执行速度快,语法简洁。
缺点:不支持文本直接匹配。
三、快速定位元素的技巧
1. 使用浏览器开发者工具
Chrome DevTools:
右键页面元素 → 选择“检查”(或按F12)。
在Elements面板中查看元素的HTML结构。
右键元素 → 选择“Copy” → 复制XPath或CSS Selector。
2. 使用插件辅助
ChroPath:Chrome插件,自动生成XPath和CSS选择器。
SelectorGadget:交互式选择元素并生成选择器。
3. 动态元素处理
部分匹配:使用contains()或starts-with():
# XPath部分匹配class driver.find_element(By.XPATH, "//div[contains(@class, 'dynamic-')]") # CSS选择器匹配属性开头 driver.find_element(By.CSS_SELECTOR, "div[class^='dynamic-']")
4. 优先选择稳定属性
避免使用以下属性:
动态生成的id(如id="button-1690xxxxx")。
可能重复的class(如class="item")。
优先选择:
业务相关的name或id(如name="email")。
带语义的data-*属性(如data-testid="submit-button")。
四、最佳实践
定位策略优先级:
ID > Name > CSS Selector > XPath > 其他。
避免绝对路径:
使用相对XPath或CSS选择器,减少对页面结构的依赖。
处理加载延迟:
结合显式等待(Explicit Wait)确保元素加载完成:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "username")) )
处理iframe:
切换至iframe后再定位内部元素:
driver.switch_to.frame("iframe-name")
五、常见错误与解决
错误场景 解决方案
NoSuchElementException 检查元素是否存在、是否在iframe中、是否需等待加载。
元素交互失败(如点击无效) 使用execute_script("arguments.click();", element)强制点击。
XPath/CSS语法错误 通过在线验证工具(如XPath Tester)调试。
通过以上方法,可以快速、精准地定位Web元素,提升自动化脚本的稳定性和可维护性。
结语
亲爱的朋友:
希望本文中描述的问题以及解决方案,可以帮助到您。当然,我们深知,问题和挑战总是层出不穷,新的情况也在不断涌现。如果读者朋友您有更好的方案,或者在实际应用中发现了文中的不足之处,请不吝分享您的宝贵建议。诚挚地邀请每一位读者加入我们的行列,共同完善这份教程。
感谢您的阅读与支持!
Dear frends,
We hope that the questions and solutions presented in this article can be of assistance to you. Of course, we are fully aware that problems and challenges are always emerging in an endless stream, and new situations are constantly arising. If you, our readers, have better solutions or have discovered any deficiencies in this article through practical application, please do not hesitate to share your valuable suggestions with us. We sincerely invite every reader to join us in continuously improving this tutorial.
Thank you for your reading and support!
See you,Parting is for better meeting!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号