
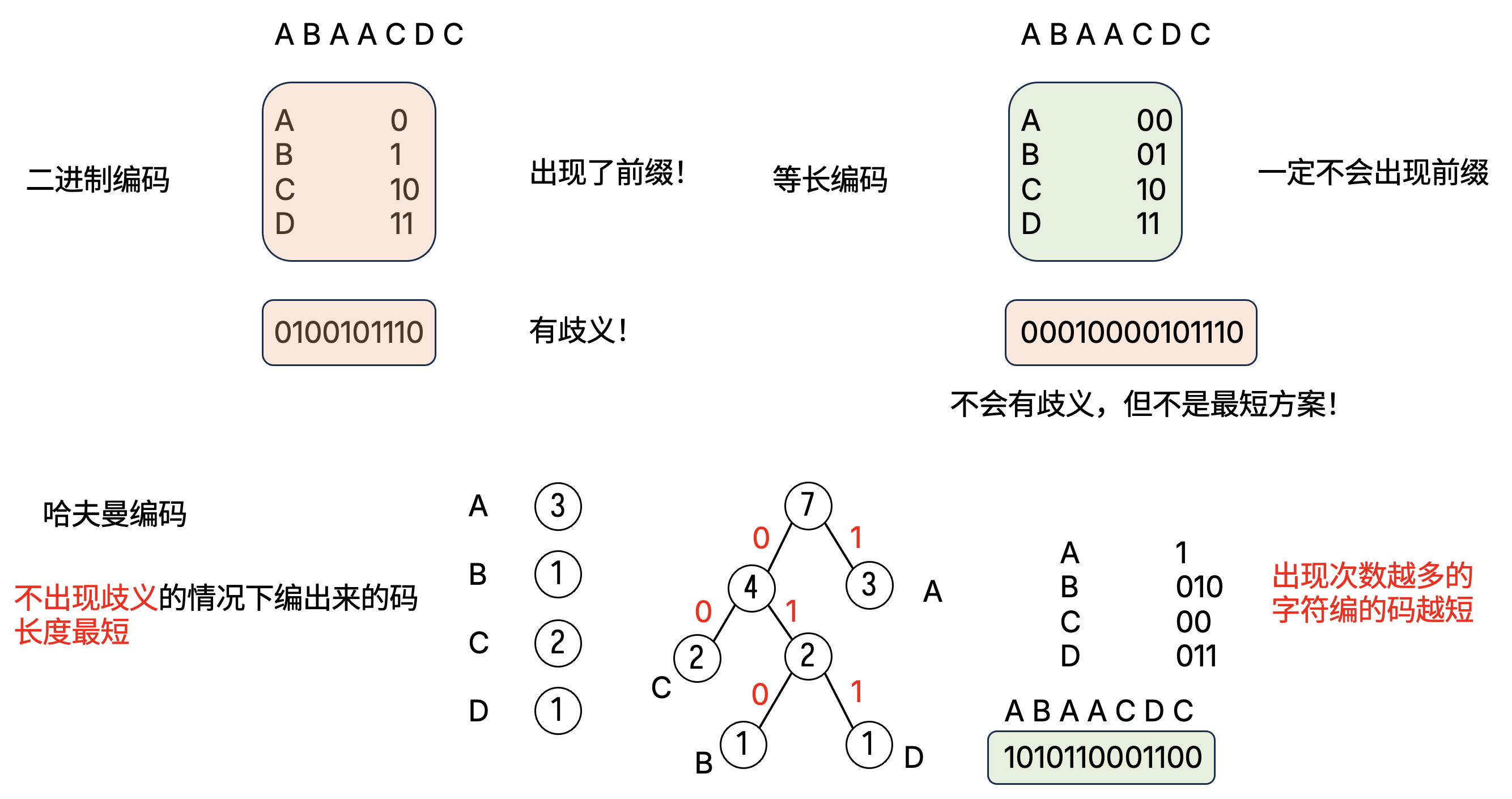
哈夫曼编码
选择题:以下对数据结构的表述不恰当的是?
- A. 队列是一种先进先出(FIFO)的线性结构
- B. 哈夫曼树的构造过程主要是为了实现图的深度优先搜索
- C. 散列表是一种通过散列函数将关键字映射到存储位置的数据结构
- D. 二叉树是一种每个节点最多有两个子节点的树结构
答案
不恰当的表述是 B。哈夫曼树是一种特殊的二叉树,它的主要用途是数据压缩。通过贪心算法构建哈夫曼树,可以为出现频率高的字符分配较短的编码,为频率低的字符分配较长的编码,从而实现最优的前缀编码,达到数据压缩的目的,它与图的深度优先搜索算法没有直接关系。
选择题:下列哪个问题不能用贪心法精确求解?
- A. 霍夫曼编码问题
- B. 0-1 背包问题
- C. 最小生成树问题
- D. 单源最短路径问题
答案
B。
贪心法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法策略。它不从整体最优上加以考虑,所做的只是在某种意义上的局部最优选择。
霍夫曼编码是一种用于无损数据压缩的熵编码算法。其核心思想是:将出现频率高的字符用较短的编码,将出现频率低的字符用较长的编码,从而使得最终编码的总长度最短。霍夫曼算法是一个典型的贪心算法,它每次都选取当前集合中频率最小的两个节点(字符或子树)合并成一个新的父节点,新节点的频率是两个子节点频率之和。这个过程不断重复,直到所有节点都合并成一棵树。这个贪心策略被证明是能够得到最优解(即总长度最短的编码)的。
最小生成树问题是在一个加权无向图中,找到一棵连接所有顶点的、总权重最小的树。解决这个问题的两个经典算法都是贪心算法:Prim 算法每次都选择连接已选顶点集合和未选顶点集合的权重最小的边;Kruskal 算法将所有边按权重从小大到大排序,每次都选择权重最小且不会形成环的边。这两个贪心策略都被证明能够精确地求得最小生成树。
单源最短路径问题是从一个指定的源点出发,找到到图中所有其他顶点的最短路径。Dijkstra 算法是解决这个问题的经典算法(在边权为非负的情况下)。Dijkstra 算法的核心思想也是贪心:每次都从“未确定最短路径”的顶点中,选择一个离源点最近的顶点,并将其“确定”,然后用它来更新其他相邻顶点的距离。这个贪心策略被证明是正确的。
0-1 背包问题是给定一组物品,每种物品都有自己的重量和价值,在限定的总重量内,如何选择才能使得物品的总价值最高。每种物品都只有一件,只能选择放或者不放。对于这个问题,一个很自然的贪心策略是优先选择“性价比”最高的物品,即价值与重量比值最高的物品。但是,这个贪心策略无法保证得到全局最优解。例如,背包重量 10kg,物品 A 价值 60 元,重量 5kg(性价比 12 元/kg),物品 B 价值 80 元,重量 8kg(性价比 10 元/kg)。如果贪心选择,放入物品 A 后,背包剩余容量为 5kg,无法再放入物品 B,最终总价值为 60 元。但是最优选择是只选择物品 B,最终总价值为 80 元。从反例可以看出,贪心选择(选 A)并没有得到最优解(选 B)。0-1 背包问题的最优解需要使用动态规划来求解。
选择题:假设有一组字符 \(\{ g,h,i,j,k,l \}\),它们对应的频率分别为 \(8\%,14\%,17\%,20\%,23\%,18\%\)。请问以下哪个选项是字符 \(g,h,i,j,k,l\) 分别对应的一组哈夫曼编码?
A. g: 1100, h: 1101, i: 111, l: 10, k: 00, j: 01
B. g: 0000, h: 001, i: 010, l: 011, k: 10, j: 11
C. g: 111, h: 110, i: 101, l: 100, k: 01, j: 00
D. g: 110, h: 111, i: 101, l: 100, k: 0, j: 01
答案

例题:P1090 [NOIP 2004 提高组] 合并果子
因为每次合并消耗的体力等于两堆果子的重量之和,所以最终消耗的体力总和就是每堆果子的重量乘它参与合并的次数。这恰好对应一个二叉哈夫曼树问题,果子堆的重量就是叶子节点的权值,参与合并的次数就是叶子到根的距离。
建立一个小根堆,插入所有果子堆的重量。不断取出堆中最小的两个值,把它们的和插入堆,同时累加到答案中。直至最后堆的大小为 \(1\) 时,输出答案即可。
参考代码
#include <cstdio>
#include <queue>
using namespace std;
// 使用小根堆(优先队列)来维护果子堆,每次能以 O(log n) 的复杂度取出当前最小的两堆
priority_queue<int, vector<int>, greater<int>> hp;
int main()
{
int n;
// 读入果子的种类数
scanf("%d", &n);
// 将所有果子堆的大小插入小根堆
for (int i = 0; i < n; i++) {
int x;
scanf("%d", &x);
hp.push(x);
}
int ans = 0;
// 贪心策略:每次从当前所有堆中选出重量最小的两堆进行合并
// 这样可以保证较小的重量被重复计算(合并)的次数尽可能多,而较大的重量被计算的次数较少
while (hp.size() > 1) {
// 取出当前最小的两堆
int min1 = hp.top();
hp.pop();
int min2 = hp.top();
hp.pop();
// 合并这两堆,并计算本次合并消耗的体力
int newmin = min1 + min2;
ans += newmin;
// 将合并后的新堆重新放回堆中,参与后续合并
hp.push(newmin);
}
// 输出最小的总耗费体力
printf("%d\n", ans);
return 0;
}
本题还有另一种方法。
观察到如果每次取出的都是当前最小的两堆,那么它们合并后的新堆大小,随着时间的推移,也是单调递增的。例如有初始排列顺序 \(1, 2, 5, 10\),第一次合并 \(1+2=3\),新产生的 \(3\) 一定不比 \(1\) 和 \(2\) 小,如果下一轮合并的是 \(3\) 和 \(5\)(得到 \(8\)),生成的数会越来越大。
因此可以使用两个队列 \(q_1\) 和 \(q_2\):
- \(q_1\) 存放初始的果子堆,预先排序,保证单调递增。
- \(q_2\) 存放每次合并后生成的新堆,根据上面分析的性质,\(q_2\) 中的元素也自然是单调递增的。
这样一来每次需要取当前最小的某一堆果子时,实际上只可能是 \(q_1\) 的队头或 \(q_2\) 的队头。而每次合并取出最小两堆后,只需要将合并结果插入 \(q_2\) 的队尾。
参考代码
#include <cstdio>
#include <queue>
#include <algorithm>
using namespace std;
const int N = 1e4 + 5;
int a[N];
// q1 存放初始的果子堆,q2 存放合并后产生的新堆
// 使用两个队列是为了在 O(n) 时间内模拟优先队列的行为(利用了合并产生值的单调性)
queue<int> q1, q2;
// 从 q1 和 q2 的队头取出当前最小的一个元素
int get() {
int val;
// 如果 q2 为空,或者 q1 不为空且 q1 队头元素小于 q2 队头元素
// 则取 q1 的队头,否则取 q2 的队头
if (!q1.empty() && (q2.empty() || q1.front() < q2.front())) {
val = q1.front(); q1.pop();
} else {
val = q2.front(); q2.pop();
}
return val;
}
int main()
{
int n;
scanf("%d", &n);
// 读入果子数量
for (int i = 0; i < n; i++) scanf("%d", &a[i]);
// 初始排序,保证 q1 中的元素是单调递增的
sort(a, a + n);
// 将排序后的元素放入 q1
for (int i = 0; i < n; i++) q1.push(a[i]);
int ans = 0;
// 总共需要进行 n-1 次合并
for (int i = 1; i < n; i++) {
// 取出当前最小的两堆果子
int val1 = get();
int val2 = get();
// 计算合并后的新堆重量,并累加体力消耗
int val = val1 + val2;
ans += val;
// 将合并后的新堆放入 q2
// 由于每次都是取最小的合并,生成的 val 也是单调递增的,所以 q2 也是有序的
q2.push(val);
}
printf("%d\n", ans);
return 0;
}
习题:P6033 [NOIP 2004 提高组] 合并果子 加强版
本题需要使用快读。
解题思路
由于 \(n\) 可以达到 \(10^7\),std::sort 会超时。观察到重量的值域很小(只到 \(10^5\)),可以使用计数排序。
单次合并不能是 \(O(\log n)\),要使用双队列的思路来优化。
参考代码
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
// 常量定义:A 为果子重量的最大值
const int A = 100005;
// cnt 数组用于计数排序,统计每种重量的果子堆数
int cnt[A];
// q1 存放初始的果子堆(已排序),q2 存放合并后产生的新堆
queue<ll> q1, q2;
// 快读函数:由于 n 到达 10^7,需要使用快速读入以减少耗时
int read() {
int num = 0;
char ch = getchar();
while (!isdigit(ch)) {
ch = getchar();
}
while (isdigit(ch)) {
num = num * 10 + ch - '0';
ch = getchar();
}
return num;
}
// 辅助函数:从 q1 和 q2 的队头中取出当前全局最小的元素
// 核心原理:初始果子已排序,且合并产生的新果子堆大小也是单调递增的
ll get_top() {
if (q2.empty() || (!q1.empty() && q1.front() < q2.front())) {
ll ret = q1.front();
q1.pop();
return ret;
} else {
ll ret = q2.front();
q2.pop();
return ret;
}
}
int main()
{
// n 为果子堆数,maxa 记录果子重量的最大值
int n = read(), maxa = 0;
for (int i = 0; i < n; i++) {
int x = read();
if (x > maxa) maxa = x;
++cnt[x]; // 桶计数
}
// 计数排序逻辑:将统计好的果子按重量从小到大放入队列 q1
// 这样 q1 内部就自然保持了单调递增
for (int i = 1; i <= maxa; ++i) {
for (int j = 0; j < cnt[i]; ++j) {
q1.push(i);
}
}
ll ans = 0;
// 进行 n-1 次合并操作
for (int i = 1; i < n; i++) {
// 贪心策略:每次取出当前最小的两堆进行合并
ll top1 = get_top();
ll top2 = get_top();
ll merge = top1 + top2;
// 将合并后的新堆放入 q2
// 由于贪心合并的性质,q2 也会保持单调递增,无需再次排序
q2.push(merge);
// 累计消耗的体力
ans += merge;
}
// 输出最终结果
printf("%lld\n", ans);
return 0;
}
例题:P2827 [NOIP 2016 提高组] 蚯蚓
如果 \(q=0\),即蚯蚓不会变长,那么本题相当于维护一个数据结构,支持查询最大值、删除最大值、插入新的值。这是堆或 STL set 能够完成的基本操作,时间复杂度为 \(O(m \log (n+m))\)。
当 \(q \gt 0\) 时,除了最大值拆成的两个数之外,其他数都会增加 \(q\)。设最大值为 \(x\),不妨认为产生了两个大小为 \(\lfloor px \rfloor -q\) 和 \(x-\lfloor px \rfloor -q\) 的新数,然后再把整个数据结构中的元素都加上 \(q\),这与之前的操作是等价的。
于是,可以维护一个变量 \(\Delta\) 表示整个结构的“偏移量”,里面的数加上 \(\Delta\) 是它的真实数值。起初,\(\Delta=0\)。对于每一秒:
- 取出最大值 \(x\),令 \(x \leftarrow x + \Delta\)。
- 把 \(\lfloor px \rfloor - \Delta - q\) 和 \(x - \lfloor px \rfloor - \Delta - q\) 插入。
- 令 \(\Delta \leftarrow \Delta + q\)。
重复上述步骤 \(m\) 轮,即可得到最终所有数的值。然而,本题中 \(m\) 的范围过大,\(O(m \log(n+m))\) 的算法无法通过全部测试点。
实际上本题有隐含的单调性,假设某一秒切了两只蚯蚓,长度分别为 \(x_1\) 和 \(x_2\),且 \(x_1 \gt x_2\)。切分后:
- \(x_1\) 变成 \(\lfloor p x_1 \rfloor\) 和 \(x_1 - \lfloor p x_1 \rfloor\)。
- \(x_2\) 变成 \(\lfloor p x_2 \rfloor\) 和 \(x_2 - \lfloor p x_2 \rfloor\)。
可以证明(在 \(0 \lt p \lt 1\) 且其余蚯蚓都在增长的情况下):先切长的蚯蚓产生的两段,一定比后切短的蚯蚓产生的对应两段要长(或者相等)。即:随着时间推移,切掉的蚯蚓越来越短(相对于同一基准),切出来的两段新蚯蚓也会越来越短。
因此,可以不需要用堆或 set,而是用三个普通队列来维护:
- 队列 1:存储初始的 \(n\) 只蚯蚓,需先从大到小排序。
- 队列 2:存储切分后长度为 \(\lfloor p x \rfloor\) 的那一段。
- 队列 3:存储切分后长度为 \(x - \lfloor p x \rfloor\) 的那一段。
由于单调性,这三个队列内部始终是有序的(单调递减)。每次要找最长的蚯蚓时,只需要比较这三个队列的队首元素,取最大者即可,这样整个算法的时间复杂度为 \(O(m + n \log n)\)。
参考代码
#include <cstdio>
#include <queue>
#include <algorithm>
using namespace std;
const int N = 1e5 + 5;
const int INF = 2e9;
int a[N];
int main()
{
int n, m, q, u, v, t;
// n: 初始蚯蚓数量, m: 时间秒数, q: 增长常数
// u/v: 切分比例, t: 输出间隔
scanf("%d%d%d%d%d%d", &n, &m, &q, &u, &v, &t);
// 定义三个队列,利用题目性质(单调性)避免使用优先队列 O(log n)
// q1: 存放初始蚯蚓(已排序)
// q2: 存放切分后长度为 floor(p*x) 的部分
// q3: 存放切分后长度为 x - floor(p*x) 的部分
queue<int> q1, q2, q3;
for (int i = 0; i < n; i++) scanf("%d", &a[i]);
// 初始从大到小排序,确保 q1 单调递减
sort(a, a + n, greater<int>());
for (int i = 0; i < n; i++) q1.push(a[i]);
// 模拟 m 秒的操作
for (int i = 1; i <= m; i++) {
// 为了处理"除了被切的蚯蚓外,其余都增加q",采用相对值法:
// 队列中存储的值 = 真实长度 - 当前累积增长量
// 即:真实长度 = 队列值 + (i-1)*q
// 寻找三队之首的最大值
// 注意:由于存储的值可能因为减去 i*q 变得很小(负数),初始化为极小值
int v1 = -INF, v2 = -INF, v3 = -INF;
if (!q1.empty()) v1 = q1.front();
if (!q2.empty()) v2 = q2.front();
if (!q3.empty()) v3 = q3.front();
int maxv = max(v1, max(v2, v3));
// 从对应的队列弹出最大值
if (maxv == v1) q1.pop();
else if (maxv == v2) q2.pop();
else q3.pop();
// 计算当前被切蚯蚓的真实长度
int cur = maxv + (i - 1) * q;
// 题目要求输出每隔 t 秒被切断蚯蚓的长度
if (i % t == 0) {
printf("%d%c", cur, i + t > m ? '\n' : ' ');
}
// 计算切分后的两段长度
// 使用 1ll (long long) 防止乘法溢出
int p1 = 1ll * cur * u / v;
int p2 = cur - p1;
// 将新产生的蚯蚓加入队列
// 下一秒(i+1)时,全局增长量为 i*q。
// 为了让取出的值 + i*q == p1 (新蚯蚓不享受本秒的增长),存入值应为 p1 - i*q
q2.push(p1 - i * q);
q3.push(p2 - i * q);
}
// 如果最后一行没有输出换行(例如 m < t),补一个换行
if (m < t) printf("\n");
// 输出 m 秒后所有蚯蚓的长度(第 t, 2t, ... 名)
int offset = m * q; // m 秒后的总增长量
int total = n + m; // 总蚯蚓数
bool first = true;
// 依次取出所有蚯蚓
for (int i = 1; i <= total; i++) {
int v1 = -INF, v2 = -INF, v3 = -INF;
if (!q1.empty()) v1 = q1.front();
if (!q2.empty()) v2 = q2.front();
if (!q3.empty()) v3 = q3.front();
int maxv = max(v1, max(v2, v3));
if (maxv == v1) q1.pop();
else if (maxv == v2) q2.pop();
else q3.pop();
if (i % t == 0) {
if (!first) printf(" ");
printf("%d", maxv + offset); // 加上最终的总增长量
first = false;
}
}
return 0;
}
例题:P2168 [NOI2015] 荷马史诗
一部《荷马史诗》中有 \(n(n \le 10^6)\) 种不同的单词,从 \(1\) 到 \(n\) 进行编号。其中第 \(i\) 种单词出现的总次数为 \(w_i(w_i \le 10^11)\)。现在要用 \(k\) 进制串 \(s_i\) 来替换第 \(i\) 种单词,使得其满足对于任意的 \(1 \le i,j \le n, i \ne j\),都有 \(s_i\) 不是 \(s_j\) 的前缀。请问如何选择 \(s_i\),才能使替换以后得到的新的《荷马史诗》长度最小。在确保总长度最小的情况下,还想知道最长的 \(s_i\) 的最短长度是多少?
哈夫曼编码的变形。每次从堆中选出权重最小的 \(k\) 个结点,将其合并建边,然后放回堆中,直到建完哈夫曼树。例如,当各结点权重分别为 1、1、3、3、9、9,需要编码为三进制时,生成的哈夫曼树如下:
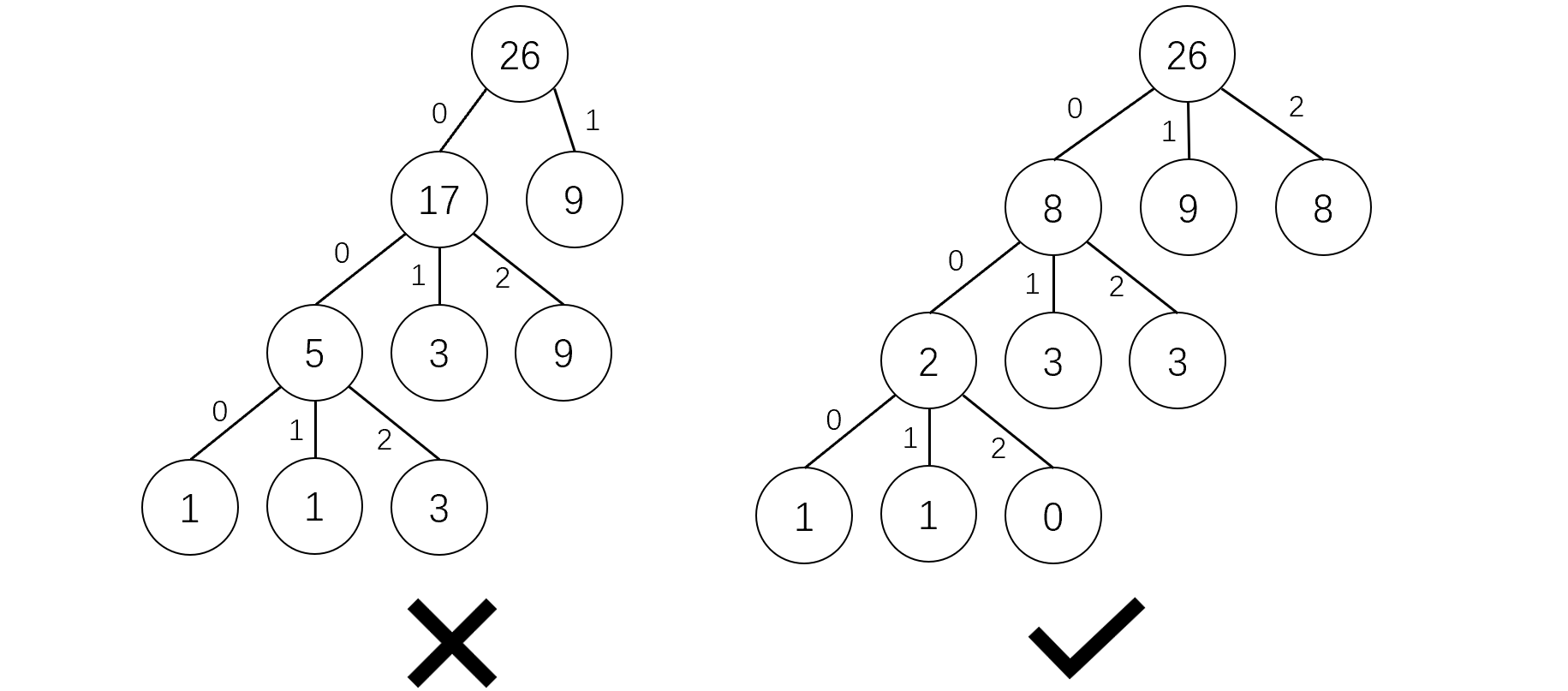
需要注意的是,每次合并都会减少 \(k-1\) 个结点,在合并最后一次的时候,如果可以合并的点的数量不足 \(k\) 个,靠近根结点的位置(短编码)反而没有被利用,所以需要在一开始补上 k-1-(n-1)%(k-1) 个权重为 \(0\) 的结点,把权重大的结点“推”到离根结点更近的位置。根据题目数据范围,答案需要 long long 类型。
参考代码
#include <cstdio>
#include <queue>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 100005;
LL w[N];
struct Node {
LL val;
int depth;
};
struct NodeCompare { // 定义Node比较类
bool operator()(const Node &a, const Node &b) {
// 权重相同时,高度小的优先出队
return a.val != b.val ? a.val > b.val : a.depth > b.depth;
}
};
int main()
{
int n, k;
scanf("%d%d", &n, &k);
priority_queue<Node, vector<Node>, NodeCompare> q;
for (int i = 1; i <= n; i++) {
scanf("%lld", &w[i]);
q.push({w[i], 1}); // 读入结点(叶节点)
}
if ((n - 1) % (k - 1) != 0) { // 有一次合并结点数量不足k个
for (int i = 1; i <= k - 1 - (n - 1) % (k - 1); i++)
q.push({0, 1}); // 需要补若干个权重为0的结点
}
LL ans = 0;
while (q.size() != 1) {
LL sum = 0; int maxh = 0;
for (int i = 1; i <= k; i++) { // 从堆中取k个最小的
Node tmp = q.top(); q.pop();
sum += tmp.val; // 新结点加上子结点权重
maxh = max(maxh, tmp.depth); // 最大深度
}
ans += sum; // 更新总长度
q.push({sum, maxh + 1}); // 合并后的结点放回堆中
}
printf("%lld\n%lld\n", ans, q.top().depth - 1); // 编码长度是哈夫曼树的高度减1
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号