


0.论文信息总览
1.论文核心问题
(1)引入:
近年来,生成式人工智能(Artificial Intelligence for Generative Content, AIGC)的融入,已成为生成合成脑电图(EEG)数据的一种复杂且高效的方法。AIGC 技术能够借助先进的生成模型(如生成对抗网络(Generative Adversarial Networks, GANs)、变分自编码器(Variational Autoencoders, VAEs)以及生成式预训练Transformer(Generative Pre-trained Transformers, GPTs)),捕捉脑电图信号中固有的细微特征,并生成与真实数据高度相似的合成脑电图样本。
然而,需要重点指出的是,部分利用 AIGC 进行脑电图数据增强的研究,对确保增强后数据的平稳性和被试不变性关注较少(motivation)。这一疏漏至关重要,因为脑电图的非平稳特性,加之被试特异性差异,对提升脑电图分析方法的性能构成了重大挑战。
为应对这一挑战,更具意义的方法是采用定制化的 AIGC 技术,从非平稳的脑电图信号中生成时间不变(在不同时间片段中保持一致性)和被试不变(生成的 EEG 数据中,情感相关核心特征具有跨被试的通用性,不受不同被试个体差异的影响)的数据。通过这种方式,有可能减轻被试特异性差异和时间波动带来的影响,进而助力开发出泛化能力优良的深度学习模型,该模型能够有效捕捉脑电图信号的关键特征。
2.论文主要贡献(工作内容+创新点)
-
本研究提出了一种全新的生成式预训练 Transformer 模型——EEGPT,专门用于处理 EEG(脑电)数据。通过引入多任务学习方法,EEGPT 能够从原始 EEG 信号中同时生成时间不变特征与时间特异特征,从而增强 EEG 数据的表示能力。
-
我们在 EEGPT 的训练过程中采用了 CLTISI 预训练策略。该策略使不同受试者的 EEG 数据在同一个高维空间中对齐,从而最大化受试者之间的相似性。
-
为了验证所提出方法的有效性,我们选用了情绪识别研究中广泛使用的三个开源 EEG 数据集:DEAP、SEED 和 SEED-IV。
3.方法细节
TISIG整体框架预览
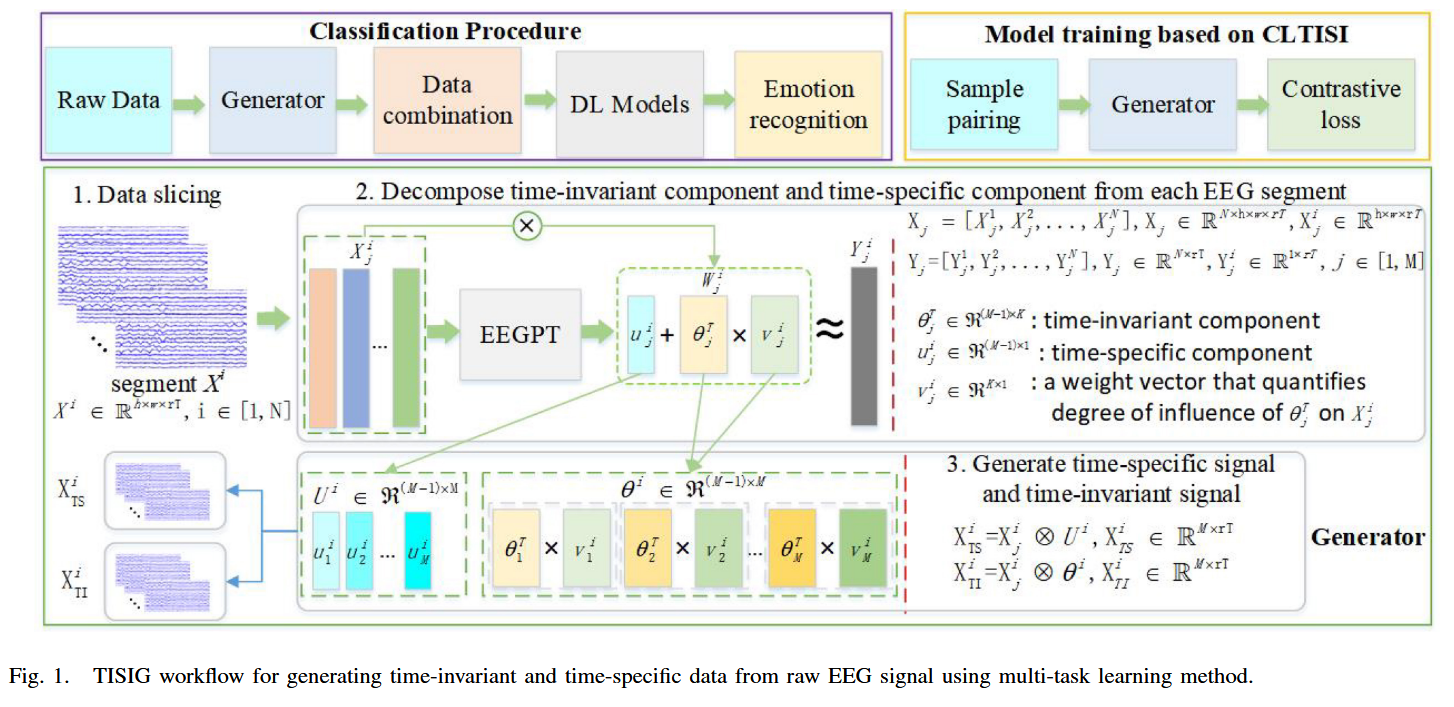
图 1 展示了 TISIG 的整体工作流程
(训练流程)
┌────────────────────────┐
│ Model training based on CLTISI │
│ - 3D Data Organization │
Raw EEG →│ - Sample pairing │→ 训练完成 → 获得 EEGPT 生成器
│ - Contrastive loss │
└────────────────────────┘
(分类流程)
调用已经训练好的 EEGPT
↓
┌─────────────────────────────────┐
│ Classification Procedure │
│ 1) Raw Data + Generated Data │
│ 2) STFT + DE 特征提取 │
│ 3) CNN/Conformer/EEGPTclf │
└─────────────────────────────────┘
↓
Emotion Recognition
TISIG=整个大流程(模型训练+数据生成+分类使用)
3.1数据预处理(Model training based on CLTISI部分)
(1)ICA去噪
ICA(Independent Component Analysis)独立成分分析,是一种把“混在一起的观测信号”分解成多个“互相独立的源信号”的方法,并且可以分离伪迹,伪迹是EEG 中那些不是大脑活动、但被电极错误记录进来的干扰信号。而Infomax算法是ICA实现方法之一。
论文:Fieldtrip工具实现Infomax算法去去除EEG信号中的潜在伪迹,由于实验使用的三个EEG数据集均经过规范采集,伪迹较少,所以仅选择性地移除 1–2 个最明显的伪迹独立成分(ICs),以最大化保留原始脑电信息。
(2)滤波(Filtering)
目的:去掉EEG中无意义的低频漂移、工频干扰、高频噪声。
论文:对来自三个开源数据集的EEG信号施加0.05-47Hz的带通滤波器
(3)3D Data Organization(h × w × T 的拓扑结构)
论文:为了处理不同数据集之间 EEG 通道数量不一致的问题,将原始数据重组为统一的3D结构。
- 具体做法:首先将每个EEG trial(一次实验刺激或任务对应的一段EEG记录)切分为长度为 \(T_s\)的不重叠片段,每个片段继承其对应原始试次的标签。原始片段\(X_i' \in \mathbb{R}^{M \times rT}\)会根据国际10-20电极布局映射到一个固定大小的二维网格上,未出现的电极位置用零填充,从而构成尺寸为\(h \times w \times rT\)的3D数组。为增强信号一致性,对每个通道在同一会话(受试者在同一次进入实验、佩戴电极、开始做任务到结束,这整段连续的 EEG 记录过程。)内执行Z-score标准化,使其具有零均值和单位方差。
什么是Z-score标准化?
Z-score 标准化 = (数据 − 均值) ÷ 标准差,让不同通道 / 不同实验的数据处于同一尺度,减少个体差异,提高模型稳定性。
3.2EEGPT模型结构(基于多任务的数据分解(理论))
EEGPT的基本学习策略:对每一个 EEG 通道进行迭代式数据生成,在生成某个通道时,利用所有其他通道的信息,但排除当前正在生成的目标通道。
定义:设第 i 个片段中第 j 个通道的 EEG 数据为 $$ Y_j^i \in \mathbb{R}^{1 \times rT} $$,而所有其他通道(除要生成的通道外)的集合数据表示为 $$ X_j^i \in \mathbb{R}^{h \times w \times rT} $$。
公式分析:$$ w_j^i = \text{EEGPT}(X_j^i), \tag{1} $$
输入\(X_j^i\),让EEGPT模型去预测/生成第\(j\)通道
定义:\(X_j^{i\prime} \in \mathbb{R}^{(M-1) \times rT}\)是将\(X_j^i\)去掉占位0向量后,展平为矩阵的版本(形状为\((M-1) \times rT\))用于与\(w_i^j\)相乘得到重建的\(Y_j^i\)(第\(j\)通道估计值),因此引出公式:
\(Y_j^i\)是对第\(j\)通道的重建值
为进一步分解\(w_j^i\),将其表示为两个矩阵成分的组合:
其中\(u_j^i\)是time-specific分量,随段\(i\)变化,反映该段独有的即时/短时相关性;\(\theta_j^T v_j^i\)对应脑电中的基础节律,即长期稳定的模式。
因此,EEGPT 模型输出两个不同的成分: 时间不变成分\(\theta_j^T v_j^i \in \mathbb{R}^{(M-1) \times 1}\) .时间特异性成分\(u_j^i \in \mathbb{R}^{(M-1) \times 1}\)。
3.3EEGPT模型结构(Generate time-specific and time-invariant signal)
Architecture of EEGPT model---TISIG内部EEGPT的具体实现
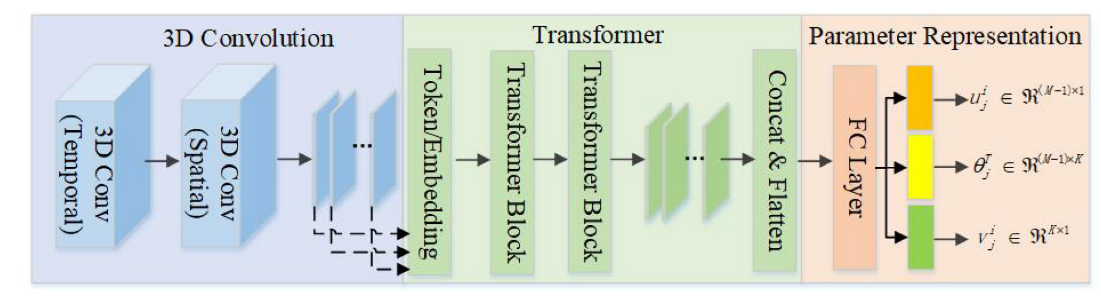
该部分覆盖了论文中的C-E的内容,基于以上图片进行分析:
EEGPT模型结构集成了一个CNN模块、Transformer模块
(1)CNN模块
由于Figure2中展示的3D Convolution并不完整,于是用文字表述CNN模块中的执行过程:
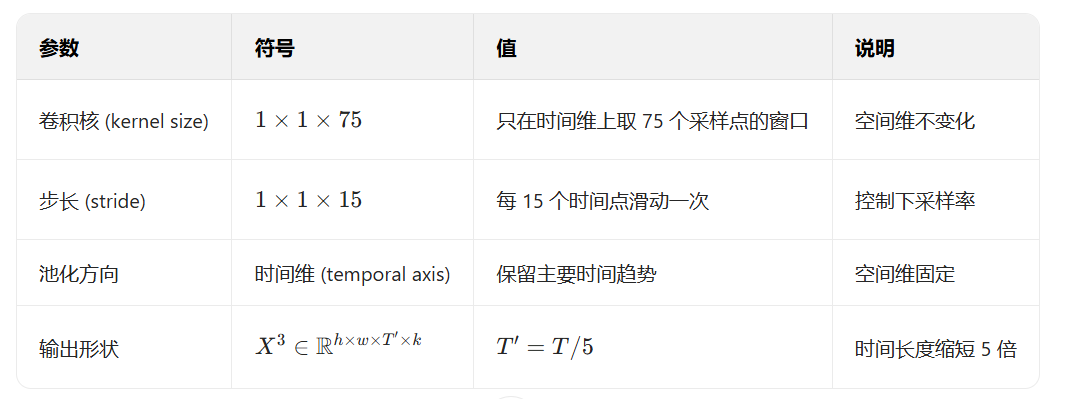
时间卷积(Temporal Conv)\(\Rightarrow\)空间卷积(Spatial Conv)\(\Rightarrow\) 批归一化(Batch Normalization)+激活函数(ELU)\(\Rightarrow\) 3D最大池化(3D Max Pooling)\(\Rightarrow\) Dropout \(\Rightarrow\) CNN输出:生成\(X_i^{\text{CNN}}\)
具体参数设置:
时间卷积是整个EEGPT模型的第一个3D卷积层,作用在经过预处理的EEG信号:

空间卷积是接着时间卷积之后的第二个3D卷积层,只在空间维上滑动,用来提取EEG的空间特征:
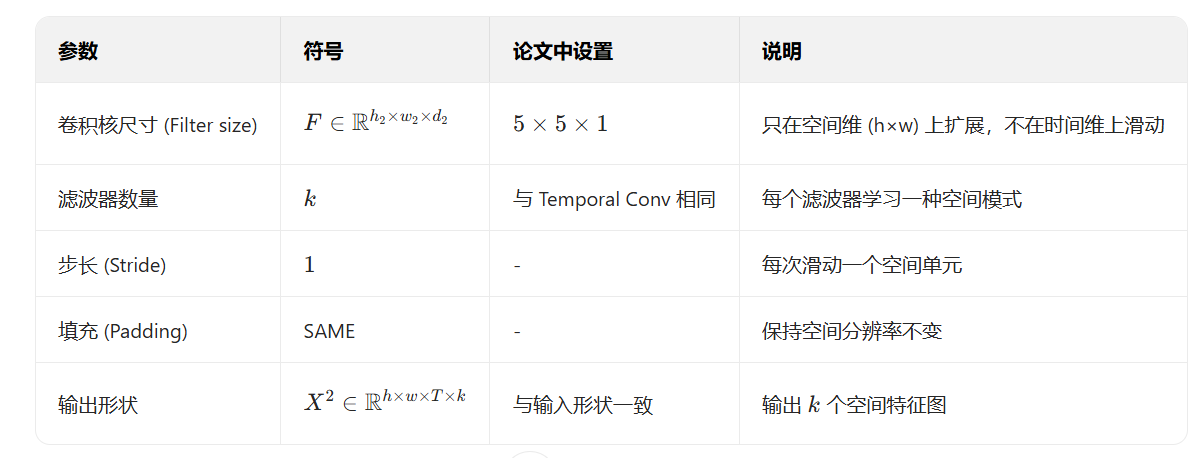
第二个三维卷积层(空间卷积层)的输出接着经过批归一化(Batch Normalization)和ELU 激活函数的组合处理。随后,在时间维上使用三维最大池化层对输出进行下采样。
其中:\(ELU(x) = \begin{cases} x, & x > 0 \\ \alpha(e^x - 1), & x \leq 0 \end{cases}\)
为什么选择ELU而不是ReLU? EEG 数据是以 0 为中心的振荡信号(正负电位均有意义),ReLU 会截断负值;ELU 能保留负域特征。
然后进行3D最大池化以及Dropout
(2)Transformer模块
\(X_i^{\text{CNN}}\)进入transformer之前要进行Flatten和Reshape,并划分为\(M = h \times w\)个token(即每个电极通道对应一个token):
进入Transformer模块之后,要进行时间位置嵌入和空间位置嵌入:
时间位置嵌入(Temporal Position Embedding,TEPE)用于让模型识别时间序列中的顺序关系,这里使用的是Transformer原版使用的正弦-余弦位置编码:
空间位置嵌入(Spatial Position Embedding,SPPE)使用 EEG 电极在 10–20 系统中的三维坐标,通过计算参考电极(Cz)与其他电极的余弦距离,表示其空间关系。
其中:\(P_m\):第 m 个电极的三维坐标,\(P_{Cz}\):参考电极 Cz 的坐标。
接着进行嵌入融合(Embedding Combination),两个位置嵌入加到原始特征上:$$Z(X_i^{\text{CNN}}) = X_i^{\text{CNN}} + X_{te} + X_{sp}$$
其中:\(X_{te}\):时间位置嵌入,\(X_{sp}\):空间位置嵌入;该步骤相当于在 token 的特征向量上叠加时空信息。
到这里完成了模块中的Token/Embedding部分,然后将\(Z(X_i^{\text{CNN}})\)输入Transformer Block(自注意力机制),EEGPT 中共使用两个 Transformer Block,每个 Block 的处理流程如下:
- 输入 ( \(Z(X_i^{\text{CNN}})\) )
↓ - Multi-Head Self-Attention(捕获跨通道全局依赖)
↓ - Add + LayerNorm(稳定训练)
↓ - Feed-Forward Network(两层全连接)
↓ - Add + LayerNorm(再次标准化)
输出为:\(X_i^{T_1}, X_i^{T_2} \in \mathbb{R}^{M \times k}\)
其中,\(X_i^{T_1}\)是第一个Transformer Block学习的输出结果,\(X_i^{T_2}\)是第二个Transformer Block学习的输出结果
经过 Transformer 的两个 Block 后,将所有特征图拼接后展平(Flatten),
其结果\(X^B\)作为模型主干网络(backbone)的输出。
(3)Parameter Representation模块
得到的\(X^B\)首先输入一个全连接层(Fully Connected Layer),然后论文中设计了三个独立的全链接投影头,分来生成不同的参数矩阵:
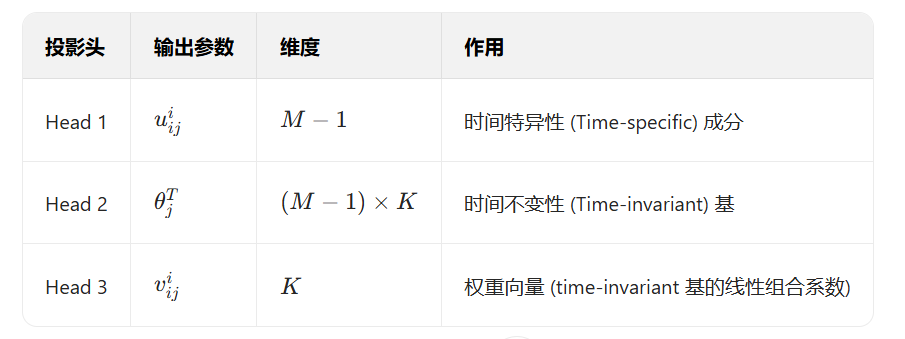
3.4 CLTISI: Contrastive Learning Method for Generating Time-Invariant and Subject-Invariant Components
完成EEGPT之后,设置EEGPT模型训练阶段的策略,前人策略:CLISA方法,该论文的方法,在CLISA的基础上扩展出CLTISI模型训练策略。
这样改动的意义:在于解决跨受试者差异,还重点应对EEG信号在时间维度上的变化性,这种变化会影响深度学习方法在分类任务的性能。CLTISI模型训练流程包含三个关键组成部分:样本配对(sample pairing)、数据生成器(data generator)、对比损失(contrastive loss)
什么是样本配对?
在不同被试之间构建正样本对(positive pairs)和负样本对(negative pairs),每个 mini-batch 包含来自两个被试(subjects)的 EEG 试次(trials)具有相同刺激标签的 EEG 信号组成正样本对,而具有不同标签的组成负样本对。
具体步骤:在每次训练时,模型从两个不同被试中选取 EEG 数据:
其中,A,B:代表两个被试(subjects);S:每个被试的 trial 数;每个\(X_i^A\)对应一个情绪刺激(emotion label)
| 样本类型 | 构建方式 | 含义 |
|---|---|---|
| ✅ 正样本对(positive pair) | (\(X_A^i\), \(X_B^i\)):两位被试对同一个刺激(same label) | 表示相同情绪状态,应该在高维空间中相似 |
| ❌ 负样本对(negative pair) | (\(X_A^i\), \(X_B^j\)), \(i \neq j\) :不同刺激(different labels) | 表示不同情绪状态,应该在特征空间中远离 |
因此,一个mini-batch中正样本对数量为S,而负样本对数量为2(S-1),在每个对比学习epoch中,所有可能的受试者组合都会枚举一遍,保证模型在训练阶段暴露于丰富的跨受试者组合。
什么是数据生成器?
数据生成器是将已经配对的EEG样本对输入EEGPT模型用来提取参数\(u, \theta, v\),最后输出\(X_{TI}\)(时间不变信号)和\(X_{TS}\)(时间特异信号),用来作为对比学习的输入
具体步骤:首先每个EEG trial \(X_i^j\)输入EEGPT模型(这一步骤在figure 1中可以看出):
线性组合的时间不变成分与原EEG信号逐点乘,生成时间不变信号:$$X_{TI}^i = X_j^i \otimes (\theta_j^T v_j^i)$$
原信号与时间特异成分结合,得到动态变化的EEG模式,反映EEG信号在特定情绪、时间段下的瞬时波动:
最终生成输出信号对:
前者用于优化“时间不变特征”的一致性,后者用于优化“时间特异特征”的区分性
什么是对比学习?
用损失函数去优化EEGPT模型的参数,两个关键的损失函数:
(1)时间特异性匹配损失(Time-Specific Contrastive Loss)
该损失约束模型在同一刺激的EEG样本应当在时间特异性空间中更接近,为对比损失(representation loss)
(2)时间不变匹配损失(Time-Invariant Fitting Loss)
拟合损失,使模型学会重建时间不变的特征,即不同时间片段中应保持稳定的通道结构
CLTISI的总损失为:
实验部分的内容留到下一节

 浙公网安备 33010602011771号
浙公网安备 33010602011771号