
使用flink agent框架实现流式情感分析的示例
参考资料
- https://nightlies.apache.org/flink/flink-agents-docs-latest/docs/get-started/overview/
- https://developer.aliyun.com/article/1681147
- https://chuna2.787528.xyz/rossiXYZ/p/19369697
本文参考官方的快速入门(docs\content\docs\get-started\quickstart\workflow_agent.md)实践了基于 Apache Flink Agents 的 Workflow Agent 情感分析示例,使用本地 LLM API 进行实时流处理。演示如何使用 Apache Flink Agents 框架构建 Workflow Agent,对文本流进行实时情感分析。本次测试的Flink Agents 版本为 0.1.1。实现实时流式情感分析(positive/negative/neutral)功能,在返回值中还存在置信度和关键词等信息。如果要提交到remote flink集群,要求版本大于1.20.3。
Flink Agents概念
在大数据与 AI 融合的趋势下,传统的“批处理”或“简单请求-响应”模式难以处理海量实时数据流。Flink Agents 的核心价值在于将 LLM 的推理能力 嵌入到 Flink 的分布式流处理管道 中。Flink Agents仍旧是一个Agents框架但是适用于事件驱动场景,事件驱动(Event-Driven)的智能体指由系统自动产生的实时事件或数据更新来触发AI的处理过程。例如,在自动化运维场景中,通过集中收集系统指标日志和trace并通过数据管道集中发往大模型,将诊断过程交给AI处理。
| 特性 | 传统 Python 脚本 + LLM | Flink Agents 框架 |
|---|---|---|
| 扩展性 | 单机运行,难以横向扩展 | 借助 Flink 算子,支持万级并行度 |
| 容错性 | 程序崩溃导致状态丢失 | 依赖 Checkpoint 机制,实现 Exactly-once |
| 背压处理 | LLM 响应慢会撑爆内存 | 自动触发 Flink 背压,保护上游系统 |
| 状态管理 | 需自行维护 Context/Memory | 内置 short_term_memory 与 Flink 状态后端绑定 |
flink具备了毫秒级实时性、大规模分布式处理、状态管理和容错能力、丰富的数据处理功能,以及对主流存储系统的广泛支持特点,和AI集成能够赋予智能化应用容错和恢复能力。架构图(https://developer.aliyun.com/article/1681147)如下
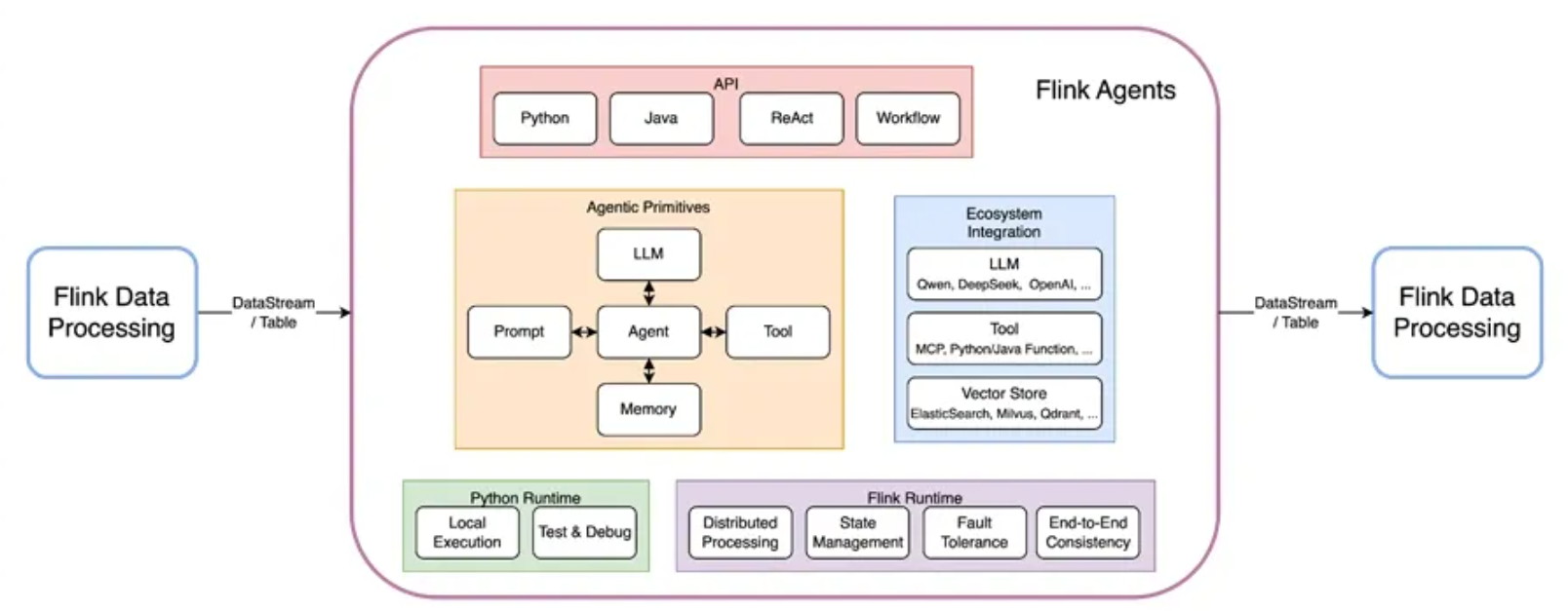
此前对于大数据场景下和AI结合的问题可能是如何实现海量数据接入LLM模型,并保证吞吐量和稳定性等因素,如果需要自行实现流式数据的实时推理又无法解决复杂的分布式通信,动态扩展,故障恢复等能力。参考Flink Agents 源码解读中Flink Agent解决了如下问题。
- 单机无法横向扩展并发量受限,缺乏分布式容错机制
- agent多阶段处理容易出现状态混乱。
- Agent 与流处理场景不适配
- 分布式场景下状态易丢失
- 生态和多框架兼容性问题
当然我们也可以通过 MapFunction 或 FlatMapFunction 自行实现推理算子,但是可能存在如下问题
- 推理(无论是调用远程 API 还是本地模型)通常极其缓慢,如果在
map函数中同步调用 LLM,整个 TaskManager 的处理线程会被阻塞,导致吞吐量骤降。如果通过异步IO来避免阻塞,则需要手动处理 Flink 的AsyncDataStream,并且要小心管理 Python 的异步协程(asyncio) - 在分布式环境下,同一条数据的可能跨越不同的处理阶段。如果需要复用模型推理的中间状态(如对话历史、任务 ID),需要手动操作 Flink 的
ValueState或ListState。同时还必须确保状态在 Checkpoint 时被正确序列化,且在扩缩容(Rescaling)时能够正确重新分发。 - 如果上游数据输入过快,而 LLM 响应变慢,任务会迅速产生Backpressure。需要自行设计手动设计缓冲队列和限流策略。
- Flink 算子的数据流是单向的,agent的的react模式则是思考 -> 动作 -> 观察 -> 思考的循环过程, 需要在单个算子中封装这套逻辑。
- 需要自行处理 Prompt 模板管理、多模型适配、JSON 解析错误重试等工作。
可见Flink Agent的核心目标是让Agent具备分布式、高并发、流处理能力,同时解决 Agent 特有的任务管理、状态一致性、多语言执行问题。具体的方式是将agent的逻辑,动作,数据流入流出,状态管理等要素封装为flink生态的datastream,action算子,数据流schema,flink状态等等。
此外,对于后端模型的要求通常有
-
模型必须能够稳定输出 JSON 格式。在 Workflow Agent 中,
process_chat_response算子通常需要解析 JSON 来填充SentimentAnalysisResult这样的 Pydantic 模型。如果模型经常返回“碎碎念”或者格式错误的 JSON,会导致流任务抛出异常或触发容错重启。 -
如果使用的是 ReAct Agent 而不是简单的 Workflow Agent,则模型必须具备基本的逻辑推理和工具调用 (Tool Calling) 能力,否则无法自主决定执行哪些 Action。
workflow agent实现
Workflows是由预定义的代码路径来编排 LLM 和工具的系统,为定义明确的任务提供了可预测性和一致性
文件结构如下
flinkagent/
├── custom_types.py # 数据类型和配置
├── sentiment_agent.py # Workflow Agent
├── workflow_agent_example.py # Flink 流处理
├── resources/ # 输入数据
resources中的input.txt文件内容如下
{"id": "1", "text": "I love this product! It exceeded my expectations."}
{"id": "2", "text": "Terrible experience, the product broke after one day."}
{"id": "3", "text": "It's okay, nothing special but does the job."}
{"id": "4", "text": "Absolutely amazing! Best purchase I've made this year."}
{"id": "5", "text": "Disappointed with the quality, would not recommend."}
{"id": "7", "text": "我今天真的很开心"}
{"id": "8", "text": "今天丢了10块钱哎"}
custom_types.py定义数据模型、Prompt 和 LLM 连接配置(llm模型选择本地自建的litellm)
from typing import List
from pydantic import BaseModel
from flink_agents.api.chat_message import ChatMessage, MessageRole
from flink_agents.api.prompts.prompt import Prompt
from flink_agents.api.resource import ResourceDescriptor
from flink_agents.integrations.chat_models.openai.openai_chat_model import (
OpenAIChatModelConnection,
)
sentiment_analysis_prompt = Prompt.from_messages(
messages=[
ChatMessage(
role=MessageRole.SYSTEM,
content="""Analyze the sentiment of the given text and classify it as positive, negative, or neutral.
Also provide a confidence score (0-1) and key phrases that support the sentiment.
Your response must be valid JSON in this format:
{
"sentiment": "positive|negative|neutral",
"confidence": 0.95,
"key_phrases": ["phrase1", "phrase2"]
}
""",
),
ChatMessage(
role=MessageRole.USER,
content="""Input text: {input}""",
),
],
)
local_llm_descriptor = ResourceDescriptor(
clazz=OpenAIChatModelConnection,
api_base_url="http://localhost:4000/v1",
api_key="sk-bu9Ftty3KVtROc66lTWBEQ",
timeout=300.0,
max_retries=1,
)
class TextInput(BaseModel):
id: str
text: str
class SentimentAnalysisResult(BaseModel):
id: str
sentiment: str
confidence: float
key_phrases: List[str]
sentiment_agent.py为Workflow Agent的核心逻辑。这里多个装饰器的意义如下
@prompt: 注册 LLM 提示词。动态注入上下文,支持{input}变量替换@chat_model_setup: 实现了模型的声明式配置,解耦了业务逻辑与底层基础设施@action(InputEvent): 处理输入事件@action(ChatResponseEvent): 处理 LLM 响应
关键组件和解释如下
- short_term_memory:在
process_input和process_chat_response这两个异步阶段之间共享数据。由 Flink 的ValueState支持。即使 Flink 节点宕机,重启后 ID 依然能找回来,保证了结果的正确归位。 InputEvent->ChatRequestEvent->ChatResponseEvent->OutputEvent。这种解耦设计允许 Flink Agents 在等待 LLM 响应时,不阻塞其他数据的摄入,从而极大提升了吞吐量
import json
import logging
from flink_agents.api.agent import Agent
from flink_agents.api.chat_message import ChatMessage, MessageRole
from flink_agents.api.decorators import action, chat_model_setup, prompt
from flink_agents.api.events.chat_event import ChatRequestEvent, ChatResponseEvent
from flink_agents.api.events.event import InputEvent, OutputEvent
from flink_agents.api.prompts.prompt import Prompt
from flink_agents.api.resource import ResourceDescriptor
from flink_agents.api.runner_context import RunnerContext
from flink_agents.integrations.chat_models.openai.openai_chat_model import (
OpenAIChatModelSetup,
)
from custom_types import SentimentAnalysisResult, sentiment_analysis_prompt
class SentimentAnalysisAgent(Agent):
@prompt
@staticmethod
def sentiment_prompt() -> Prompt:
return sentiment_analysis_prompt
@chat_model_setup
@staticmethod
def sentiment_model() -> ResourceDescriptor:
return ResourceDescriptor(
clazz=OpenAIChatModelSetup,
connection="local_llm",
model="qwen3-vl",
prompt="sentiment_prompt",
extract_reasoning=True,
)
@action(InputEvent)
@staticmethod
def process_input(event: InputEvent, ctx: RunnerContext) -> None:
# 接收输入,发送给 LLM
from custom_types import TextInput
input_data: TextInput = event.input
ctx.short_term_memory.set("id", input_data.id)
msg = ChatMessage(role=MessageRole.USER, extra_args={"input": input_data.text})
ctx.send_event(ChatRequestEvent(model="sentiment_model", messages=[msg]))
@action(ChatResponseEvent)
@staticmethod
def process_chat_response(event: ChatResponseEvent, ctx: RunnerContext) -> None:
# 解析 LLM 响应,输出结果
try:
json_content = json.loads(event.response.content)
ctx.send_event(
OutputEvent(
output=SentimentAnalysisResult(
id=ctx.short_term_memory.get("id"),
sentiment=json_content["sentiment"],
confidence=json_content["confidence"],
key_phrases=json_content["key_phrases"],
)
)
)
except Exception as e:
logging.exception(f"Error processing chat response: {e}")
raise
Flink 流处理主程序如下,通过local模式启动flink环境。流式读取resources文件中的内容并输出结果到console中
from pathlib import Path
from pyflink.common import Duration, WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.file_system import FileSource, StreamFormat
from flink_agents.api.execution_environment import AgentsExecutionEnvironment
from custom_types import TextInput, local_llm_descriptor
from sentiment_agent import SentimentAnalysisAgent
def main():
env = StreamExecutionEnvironment.get_execution_environment()
agents_env = AgentsExecutionEnvironment.get_execution_environment(env)
agents_env.add_resource("local_llm", local_llm_descriptor)
current_dir = Path(__file__).parent
input_stream = env.from_source(
source=FileSource.for_record_stream_format(
StreamFormat.text_line_format(), f"file:///{current_dir}/resources"
)
.monitor_continuously(Duration.of_minutes(1))
.build(),
watermark_strategy=WatermarkStrategy.no_watermarks(),
source_name="sentiment_analysis_source",
).map(lambda x: TextInput.model_validate_json(x))
result_stream = (
agents_env.from_datastream(input_stream, key_selector=lambda x: x.id)
.apply(SentimentAnalysisAgent())
.to_datastream()
)
result_stream.print()
agents_env.execute()
if __name__ == "__main__":
main()
执行效果如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号