
udemy课程之terraform常见概念和使用方法
本文来自与udemy课程Complete Terraform Course - Beginner to Advanced内容整理
terraform基本概念
Terraform 是一种开源的基础架构即代码 (Infrastructure as Code, IaC) 工具。它允许你通过代码来自动化、管理和配置基础设施及其运行的服务。很多人会将Terraform和Ansible这两者混淆,因为它们的功能有重叠,但侧重点完全不同:
| 特性 | Terraform | Ansible |
|---|---|---|
| 主要定位 | 基础架构配置工具 (Provisioning) | 配置管理工具 (Configuration Management) |
| 擅长领域 | 创建服务器、VPC、负载均衡器等基础资源。 | 在已有服务器上安装软件、更新配置、部署应用。 |
| 状态管理 | 强项,擅长编排 (Orchestration)。 | 侧重于任务执行的成熟度。 |
| 最佳实践 | 配合使用: 用 Terraform 搭建环境,用 Ansible 部署应用。 |
Terraform 的配置语言是声明式语法带来的优势
- 声明式语法:在配置文件中仅定义最终想要的资源状态,而非告诉 Terraform 具体的执行步骤
- 执行逻辑:执行
terraform apply时,Terraform 会先检查账户的当前实际状态,再与配置文件中的期望状态对比:若资源已存在且配置一致,不执行任何操作;若资源不存在或配置不一致,自动执行创建 / 修改操作,以匹配期望状态; - 幂等性:多次执行同一配置的 terraform apply 命令,最终都会得到完全相同的结果。一方面能避免重复操作导致的资源冗余或意外破坏,另一方面无需用户记忆 / 关注资源的当前实际状态,只需维护好配置文件中的期望状态即可,大幅降低操作成本。
声明式 (Declarative) vs. 命令式 (Imperative)的区别
- 声明式(Terraform 采用): 只需定义最终目标(例如:“我想要 5 台服务器和一个数据库”),Terraform 会自动计算达成该目标所需的步骤。
- 命令式: 你必须详细定义每一个执行步骤(例如:“第一步创建 VPC,第二步启动实例...”)。
Terraform 能够连接各种平台(如 AWS、Azure、Kubernetes)主要依靠以下两个组件:
Terraform Core
核心引擎负责处理两个输入源:
-
配置文件: 用户定义的“期望状态”。
-
状态文件 (State): 记录当前基础设施的“实际状态”。
核心引擎会对比两者,制定出执行计划 (Plan),确定需要创建、更新或删除哪些资源。
Providers
Terraform 拥有超过 100 家供应商(如 AWS, Google Cloud, Kubernetes, Jenkins 等)。它们通过 API 连接不同的平台,使你无需学习每个平台的原始 API 就能进行资源管理。Terraform 不仅仅用于初始创建,其真正的威力在于全生命周期管理:
- 调整与修改: 当你需要增加 5 台服务器或更改安全权限时,只需修改配置文件,Terraform 会自动处理增量更新。
- 环境复制: 你可以使用同一套代码快速克隆出一个与测试环境完全一致的生产环境或预发布环境 (Staging),确保环境的一致性。
terraform命令
操作 Terraform 的流程通常非常简洁,主要包含以下命令:
terraform refresh:查询提供商,获取当前基础设施的最新真实状态。terraform plan:预览即将发生的更改。它会对比当前状态与你的代码,告诉你将创建、修改或销毁什么。terraform apply:正式执行计划,将配置应用到实际环境。terraform destroy:销毁整个环境,按正确顺序清理所有已创建的资源。
terraform plan
当多人协作同一个 Terraform 项目时,你无法知晓基础设施的当前实际状态,又想查看当前实际状态和配置文件定义的期望状态之间的差异,且不想实际执行任何变更操作时,可使用terraform plan命令。
- 该命令的核心作用是预览变更,执行后会列出 Terraform 为了达到期望状态,需要执行的所有操作(如创建、修改、删除资源),输出内容和
terraform apply的预览完全一致,但不会实际应用任何变更; - 若之前通过
terraform destroy -target删除了资源,但配置文件中仍保留该资源的代码,执行terraform plan后,会明确提示执行 apply 将添加该新资源,清晰展示状态差异。
terraform apply -auto-approve
使用常规的terraform apply命令时,Terraform 会先计算变更、展示预览,再等待人工确认后才执行操作。若想跳过确认步骤、让变更自动立即执行,可使用-auto-approve参数。
- 命令格式为
terraform apply -auto-approve,添加该参数后,Terraform 不会展示变更预览,也不会要求人工确认,直接根据配置文件执行所有变更
terraform destroy
若想一键清理通过当前配置文件创建的所有资源,彻底销毁相关基础设施,可使用terraform destroy命令
- 执行该命令且不指定
-target参数时,Terraform 会遍历当前配置文件中的所有资源,自动识别资源间的依赖关系,按正确的销毁顺序逐一删除所有资源,无需手动考虑销毁先后; - 执行前会给出完整的销毁预览,明确列出所有即将被删除的资源
- 该命令与
terraform destroy -target(精准删除单个资源)不同,前者针对整个配置文件的基础设施,后者仅删除指定资源,且前者无需关注资源依赖,Terraform 会自动处理。
terrafrom配置文件
Terraform 本质上是一个用 Go 语言编写的单二进制文件/usr/bin/terraform,但Terraform 并不只靠一个二进制文件工作,当开始使用它时会在不同层级产生相关文件
config与provider文件
-
用户级全局配置 (
~/.terraformrc)。用于配置全局行为,例如配置 CLI 镜像源(Provider Mirror)、设置 API 令牌(如 Terraform Cloud 的 Token)或自定义插件搜索路径。 -
插件缓存目录 (
~/.terraform.d/)。默认情况下,Terraform 会将下载的 Provider(插件)放在这里(如果配置了插件缓存)。这可以避免每个项目都重复下载几百 MB 的插件。由于 Terraform 的 Provider 插件体积通常较大,建议在~/.terraformrc中配置plugin_cache_dir,这样所有项目可以共享同一份插件,能省下不少磁盘空间。
设置缓存
mkdir -p ~/.terraform.d/plugin-cache
cat ~/.terraformrc
# 开启插件缓存目录
plugin_cache_dir = "$HOME/.terraform.d/plugin-cache"
验证缓存
$ find .terraform/providers -type l -ls
219925262 0 lrwxrwxrwx 1 ec2-user ec2-user 96 Feb 2 13:13 .terraform/providers/registry.terraform.io/hashicorp/local/2.6.2/linux_amd64 -> /home/ec2-user/.terraform.d/plugin-cache/registry.terraform.io/hashicorp/local/2.6.2/linux_amd64
project级配置
当进入一个包含 .tf 文件的目录并执行 terraform init 时,会生成项目级文件 (执行 terraform init 后)
.terraform/目录:存放当前项目所需的 Provider 驱动(如 AWS、Azure、阿里云的插件)和 Backend 配置。这个目录通常很大,绝对不要提交到 Git 仓库。.terraform.lock.hcl:依赖锁文件。记录了当前项目使用的 Provider 的精确版本和哈希值,确保团队成员在不同机器上安装的是完全一致的插件。terraform.tfstate:状态文件,记录了现实世界中资源的实际映射关系,不要手动修改这个文件
project环境隔离
在 Terraform 中,当的项目规模变大(比如同时拥有“开发环境”、“测试环境”和“生产环境”),如果隔离做得不好,在开发环境执行一个 destroy 可能会不小心删掉生产环境的数据库。那么如何实现环境隔离?
Workspace
Terraform 内置的一种快速切换机制。它允许你在同一个代码目录下,拥有多份独立的 tfstate 状态文件。
- 创建并切换环境:
terraform workspace new dev - 再次创建:
terraform workspace new prod - 切换环境:
terraform workspace select dev
Terraform 会在 terraform.tfstate.d/ 目录下为每个 Workspace 创建独立的文件夹。
你可以在代码中使用 ${terraform.workspace} 变量来区分资源名称。
resource "local_file" "env_file" {
filename = "config-${terraform.workspace}.txt"
content = "This is the ${terraform.workspace} environment."
}
缺点是代码逻辑混合在一起,容易因为误切换 Workspace 导致操作失误;且不方便针对不同环境配置完全不同的 Provider。
目录级隔离
即通过不同的文件夹结构彻底物理隔离。
my-infrastructure/
├── modules/ # 公共组件(如网络、数据库配置)
│ └── web_server/
├── environments/ # 环境配置
│ ├── dev/
│ │ ├── main.tf # 调用 modules 并传入开发版参数
│ │ └── variables.tf
│ └── prod/
│ ├── main.tf # 调用 modules 并传入生产版参数
│ └── variables.tf
状态存储
TerraForm 的核心工作逻辑,是持续跟踪基础设施的当前实际状态,并与配置文件中定义的期望状态做对比,进而计算并执行必要的变更操作。而实现状态跟踪的核心,是 TerraForm 自动生成的状态文件,同时它还提供了terraform state系列命令,方便我们便捷查看和管理状态信息,无需手动翻阅状态文件。
每次执行terraform plan(查差异)、terraform apply(执行变更)、terraform destroy(销毁资源)时,终端输出中都会出现刷新状态的相关提示。执行刷新后,TerraForm 会先同步基础设施的当前实际状态,再对比配置文件的期望状态,最终计算出从当前状态到期望状态需要执行的创建、修改、删除等操作;
状态文件
TerraForm 会在我们的配置文件夹中,自动生成两个核心文件来存储状态信息(这两个文件会在第一次执行terraform apply 时被创建,后续所有变更操作都会触发其内容更新),这也是它能知晓资源当前状态的关键,所有状态相关的刷新与更新,本质都是对这两个文件的操作。
- 核心文件terraform.tfstate
- 该文件为JSON 格式,是 TerraForm 的当前状态存储库,里面记录着与配置文件对应的所有资源列表及完整属性信息;
- 首次执行
apply时会连接 AWS账户,执行配置中定义的资源操作,操作完成后会将基础设施的当前实际状态写入该文件; - 后续每次执行变更并应用后,该文件会被实时更新,若销毁所有资源文件中的资源数组会变为空,代表当前无 TerraForm 管理的资源;
- 备份文件:terraform.tfstate.backup
- 该文件是 TerraForm 的先前状态备份,保存着本次变更操作前的资源状态信息;
- 比如销毁所有资源前,原有的资源属性、列表会被保存至该文件;重新应用配置后,新的状态写入主文件,旧状态仍保留在备份文件中,实现状态的追溯。
状态文件内容
状态文件中会记录 TerraForm 管理的所有组件,不仅包括通过resource创建的资源(如 VPC、子网),还包括通过data查询的现有资源(如默认 VPC),每个组件都会以对象形式存储完整属性;
- 自动补充 AWS 生成的属性:在配置文件中,我们仅定义了资源的部分核心属性(如 CIDR 块、可用区),而 AWS 自动生成的属性(如资源 ID、默认 VPC 的固有属性、子网的额外配置),都会被 TerraForm 同步并写入状态文件;
- 变更同步更新:无论通过配置文件修改、
terraform apply执行创建 / 删除,还是terraform destroy销毁资源,状态文件都会实时同步更新。比如删除两个资源后,状态文件中的组件数量会对应减少,执行terraform state list可直观看到结果。
查询状态
直接查阅状态文件的原始内容,在资源数量较少时尚可实现,但如果创建了数百个资源,手动翻阅 JSON 文件、查找特定属性会非常困难,因此 TerraForm 提供了terraform state命令,让我们能便捷、精准地访问状态文件中的信息。
- 执行
terraform state即可列出所有可用的子命令,覆盖资源列表、属性查询、状态提取等所有操作; - 常用核心子命令
terraform state list:列出状态文件中所有 TerraForm 管理的资源,输出内容包含资源类型、自定义名称,同时能区分是data查询的资源还是resource创建的资源,清晰展示当前管理的资源清单;terraform state show 资源类型.资源名称:显示特定资源的完整属性信息
注意如下事项:
- 禁止手动修改状态文件(terraform.tfstate/backup),也不要直接手动执行状态修改类子命令;状态的更新、变更应该由 TerraForm 根据配置文件的变更自动完成,手动操作会导致状态文件记录的信息与 AWS 实际基础设施状态不一致,引发后续变更计算错误;
- 自动更新验证:无论通过
terraform destroy删除资源,还是从配置文件中移除资源后执行terraform apply -auto-approve,TerraForm 都会自动更新状态文件,执行terraform state list可直观看到资源清单的同步变化,印证状态的自动维护机制。
状态后端
在 Terraform 中,存储状态文件的地方被称为 Backend(后端)。默认情况下,Terraform 使用 local 后端(即存储在当前目录的 terraform.tfstate),但在团队协作或多堆栈场景下,状态文件(tfstate)存储的位置也必须隔离。
存到远程后端不仅仅是为了备份,它解决了三个关键痛点:
- 状态锁 (State Locking)。当在执行
apply时,Terraform 会在远程加一把“锁”。此时如果其他人也尝试执行,他会收到报错。这能有效防止两人同时修改导致资源被弄乱。 - 团队共享。不再需要把
tfstate提交到 Git(因为状态文件里包含明文密码和敏感信息),只需拉取代码,Terraform 会自动从云端同步状态。 - 安全性。云端存储通常支持加密 (Encryption at Rest) 和 版本管理。如果状态文件不小心搞坏了可以通过 OSS/S3 的版本历史轻松找回。
例如,如果使用 S3 或 阿里云 OSS 存储状态,应该为不同堆栈指定不同的 key(路径)
# dev/backend.tf
terraform {
backend "s3" {
bucket = "terraform-state-1010 "
key = "env/dev/terraform.tfstate" # 开发环境路径
region = "cn-north-1"
}
}
# prod/backend.tf
terraform {
backend "s3" {
bucket = "terraform-state-1010 "
key = "env/prod/terraform.tfstate" # 生产环境路径
region = "cn-north-1"
}
}
存储在s3上的状态文件如图

加载机制和执行逻辑
在一个目录下,Terraform 会自动加载并合并所有以 .tf 或 .tf.json 结尾的文件。在 Terraform 看来虽然在物理上把代码分成了 vpc.tf、vm.tf 和 output.tf,但它在处理时会将它们视作同一个巨大的文件。以 _ 开头的文件(如 _main.tf)依然会被加载,它没有特殊的隐藏含义。但是,子文件夹里的 .tf 文件不会被自动加载。如果想运行子文件夹里的代码,必须将其定义为 Module(模块)。
Terraform 是一种声明式(Declarative)语言,它使用的是依赖关系图(Dependency Graph)。
-
Terraform 先扫描所有文件,识别出每一个资源(Resource)以及它们之间的引用关系。
-
它会构建一个“有向无环图”(DAG)。
-
如果资源 A 的参数引用了资源 B 的属性,那么 Terraform 必须先创建 B,再创建 A。
-
如果资源 C 和资源 D 之间没有任何引用关系,Terraform 会并行开始创建它们,以提高效率。
依赖关系
隐式依赖(Implicit Dependency)是最自然的方式。直接在资源 A 中引用资源 B 的输出。Terraform 会自动算出:必须先建好安全组,拿到 ID,才能去建服务器。
resource "aws_instance" "web" {
ami = "ami-xxx"
# 这里引用了 security_group 的 ID,即隐式依赖
vpc_security_group_ids = [aws_security_group.allow_http.id]
}
resource "aws_security_group" "allow_http" { ... }
显式依赖(Explicit Dependency)。有些资源在 API 层面没有直接引用,但逻辑上必须有先后(例如:应用需要等待数据库的权限初始化完成)。
resource "aws_instance" "web" {
ami = "ami-xxx"
# 强制要求必须在数据库创建完之后再创建
depends_on = [aws_db_instance.database]
}
module和resource
Terraform 的语法简洁、直观,且跨provider高度一致:无论使用哪个云服务provider,访问其组件的语法规则都基本相同,降低了跨平台操作的学习成本;provider、资源、数据的编程类比:可将
- provider比作编程语言中导入的库,该库包含一系列代码和函数;
- Resource 组件比作从库中调用的创建类函数,通过传入参数创建新对象;
- Data 组件比作从库中调用的查询类函数,返回已存在的对象;、
在处理像 AWS EKS(弹性 Kubernetes 服务) 这种复杂的云服务时
- Resource(资源):是 Terraform 的最小构建单元。 如果想手动搭建一个 EKS 集群需要定义:aws_eks_cluster(控制平面)、aws_iam_role(权限)、aws_vpc(网络)、aws_eks_node_group(计算节点)等 10 几个甚至几十个 独立的 resource
- Module(模块):是资源的封装包。 一个 EKS module 内部可能包含了 50 多个 resource。它把这些复杂的底层逻辑打包好,只暴露几个简单的参数(如集群名称、节点数量)即可使用
EKS 是云服务中配置最繁琐的一类,如果你只用 Resource需要写几百行代码来定义:
resource "aws_eks_cluster" "this" { ... }resource "aws_iam_role" "cluster" { ... }resource "aws_iam_role_policy_attachment" "cluster_policy" { ... }- ...
如果用 Module只需要几十行代码,模块内部会自动帮你处理好所有的 IAM 和网络关联:
module "my_eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.0"
cluster_name = "my-cluster"
cluster_version = "1.29"
# 自动创建并关联节点组
eks_managed_node_groups = {
general = {
instance_types = ["t3.medium"]
min_size = 1
max_size = 3
}
}
}
如何理解嵌套关系?
-
底层是 Resource:所有的云端变动最终都是由 resource 触发 API 调用完成的。
-
中间层是 Module:它把相关的 resource 按照逻辑组合在一起。
-
顶层是 Project:通过调用一个或多个 module,快速拼装出完整的架构。
子模块和公共模块
只要一个文件夹里包含 .tf 文件它就是一个 Module。模块的核心特性即参数化与输出访问
- 支持传入自定义参数:定义模块时,可将需要动态调整的值设置为参数,使用模块时只需从外部传入对应参数值即可,灵活适配不同的使用场景;
- 可访问模块的输出属性:模块内创建的资源,其对象和属性可作为模块输出对外暴露,后续在配置中可直接访问这些输出值,用于创建其他关联资源。
部分复杂模块会依赖多个不同的 Terraform 提供商,其底层会使用这些提供商的资源完成配置,这些依赖的提供商会在执行terraform init时一并自动安装。
假设有一个管理 Web 服务器的项目,我们把网络部分拆出去做一个 Module。关键的三个核心逻辑如下
- 隔离性: 子模块不能直接读取主目录里的变量。必须通过
variable显式传进去。 - 封装性: 主目录不能直接读取子模块里的资源属性。必须在子模块里通过
output显式抛出来。 - 路径: 在子模块中使用
${path.module}指代子模块本身所在的目录,而不要用相对路径,否则一旦被调用路径会乱掉。
my-project/
├── main.tf # 主配置文件(Root Module)
└── modules/ # 建议统一放在 modules 文件夹下
└── vpc_network/ # 子模块文件夹
├── main.tf # 子模块的逻辑
├── variables.tf # 子模块接收的参数
└── outputs.tf # 子模块暴露给外部的属性
编写子模块 (modules/vpc_network/),在子模块里定义“输入”和“输出”。
# modules/vpc_network/main.tf
resource "local_file" "network_config" {
filename = "${path.module}/network_info.txt"
content = "Network Name: ${var.network_name}"
}
# modules/vpc_network/variables.tf
variable "network_name" {
description = "由外部传入的网络名称"
type = string
}
# modules/vpc_network/outputs.tf
variable "file_id" {
value = local_file.network_config.id
}
在主目录下调用它 (main.tf)
# main.tf
module "my_custom_network" {
# 1. 指定路径(必须以 ./ 或 ../ 开头)
source = "./modules/vpc_network"
# 2. 传递参数(对应子模块里的 variables.tf)
network_name = "production-vpc"
}
# 引用模块的输出
output "module_output_info" {
value = module.my_custom_network.file_id
}
当新增了一个 module 块或者修改了 source 路径,必须运行以下命令:
terraform init
Terraform 需要在 .terraform/modules/ 目录下创建一个索引,它会记录这个模块在磁盘上的位置(如果是从 GitHub 下载的模块,它会在此步骤进行下载)
变量和输出
output
output允许我们在配置文件中自定义规则,让 Terraform 在执行apply完成后,自动输出指定资源的属性和值,无需再通过状态文件或terraform state命令查询
创建资源时,仅在配置中定义了少量核心属性,其余属性都是由云服务提供者(如 AWS)自动生成的。想要查看这些自动生成的属性值,只能通过翻阅terraform.tfstate状态文件,或执行terraform state show命令查询特定资源。而通过输出值(output) 配置,我们可以在配置文件中提前定义需要获取的资源属性,Terraform 会在应用配置结束后,直接在终端打印这些属性的实际值,无需额外操作,直观又便捷。
输出值通过 Terraform 的 output关键字 定义,核心是为输出值命名,并指定要输出的「资源对象。属性名」,具体操作步骤如下:
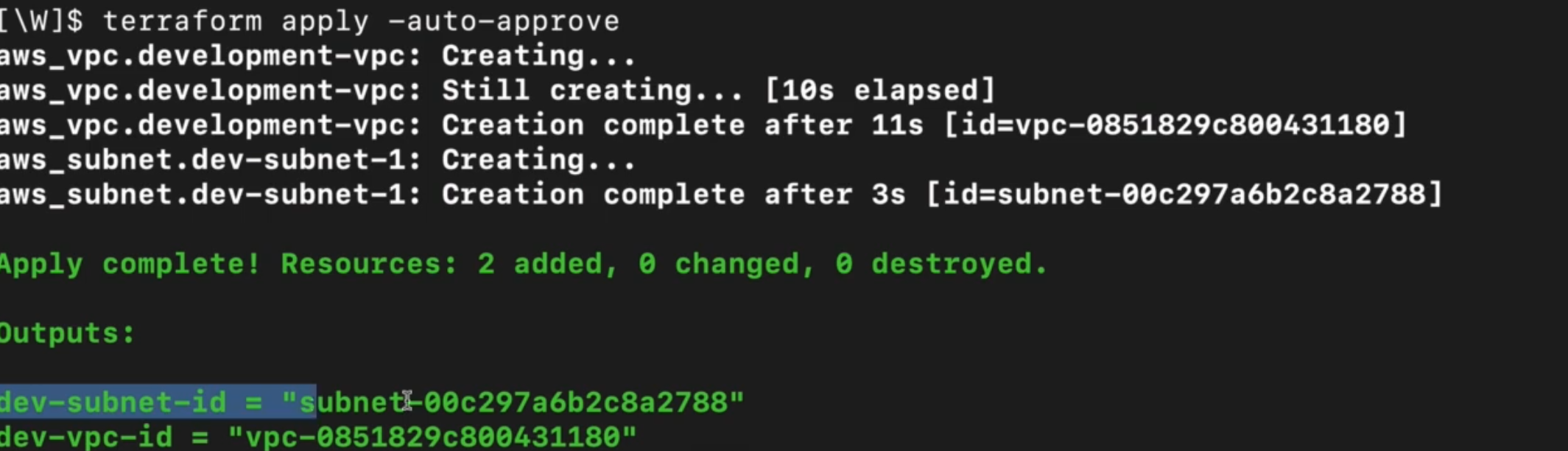
output "dev-vpc-id" {
value = aws_vpc.development-vpc.id
}
output "dev-subnet-id" {
value = aws_vpc.development-vpc.id
}
如果不清楚某个资源有哪些可输出的属性(包括自定义配置的和云服务自动生成的),可以通过 terraform plan命令 查询,Terraform 会输出资源的变更预览,其中包含该资源的所有属性清单。从属性清单中选择需要获取的属性,直接写入output块的value中即可;
每个要输出的属性,都必须单独定义一个output块。注意:即使是同一个资源的多个属性,也不能在一个output块中定义多个值,需为每个属性创建独立的output。若需要同时输出 VPC 的 ID 和子网的 ID,需分别创建output "vpc_id"和output "subnet_id"两个块,各自指定对应的属性;
output功能在实际使用中的场景如下
-
创建多个资源时,一次性输出所有资源的
id,快速掌握所有资源的标识,便于后续资源引用或管理; -
创建 EC2 服务器、弹性 IP 等资源时,直接输出公网 IP 地址,无需通过
terraform state show或云服务控制台查找,直接用于远程连接; -
任何需要获取资源自动生成属性的场景,都可以通过输出值直接打印,替代繁琐的状态查询操作,提升日常操作效率。
variable
Terraform 的变量是实现配置解耦、复用的核心概念,能将配置文件中的硬编码值抽离为可动态传递的参数,无需修改配置代码,就能为不同场景、不同环境传递不同值,尤其适配开发 / 生产等多环境共用同一配置模板的场景。
变量的核心作用是将配置中固定的硬编码值(如子网 CIDR 块)抽离,作为外部可传递的参数,支持同一配置模板在不同场景、不同资源中复用,也能为多环境传递差异化参数。示例:为子网 CIDR 块定义变量,添加描述说明变量用途,提升配置可读性;
variable "subnet_cidr_block" {
description ="subnet cidr block"
}
resource "aws_subnet" "dev-subnet-1" {
vpc_id = aws_vpc.development-vpc.id
cidr_block = var.subnet_cidr_block
availability_zone = "eu-west-3a"
tags = {
Name: "subnet-1-dev"
}
}
注意:AWS 不支持直接修改现有子网的 CIDR 块,若通过变量修改子网 CIDR 值,TerraForm 会先删除旧子网,再创建新子网
赋值方式
定义变量并在配置中引用后,需为变量传递实际值,TerraForm 提供三种赋值方式,适配不同使用场景,效率和实用性依次提升:
- 交互式输入(适合测试 / 临时验证)
执行terraform apply时,TerraForm 会自动提示输入未赋值的变量值,输入后即可继续执行变更。该方式无需额外配置,但需要人工手动输入,效率低,仅适合临时测试、验证变量功能的场景。
- 命令行参数赋值(无需人工提示)
执行terraform apply时,通过-var 变量名=值的参数直接为变量赋值,命令执行时不会再弹出输入提示,直接使用指定值。适合单次、快速为变量传值的场景。
terraform apply -var subnet_cidr_block=10.0.30.0/24
- 变量文件赋值
TerraForm 支持专门的变量文件存储键值对形式的变量值,有固定的命名约定,是最规范、最高效的赋值方式,也是日常使用的最佳实践;
- 新建默认变量文件命名为
terraform.tfvars(扩展名固定),TerraForm 会自动识别并加载该文件,无需额外参数; - 直接写
变量名 = 变量值的键值对,可定义多个变量; - 直接运行
terraform apply,TerraForm 会自动从该文件读取变量值,无需手动输入或传命令行参数。
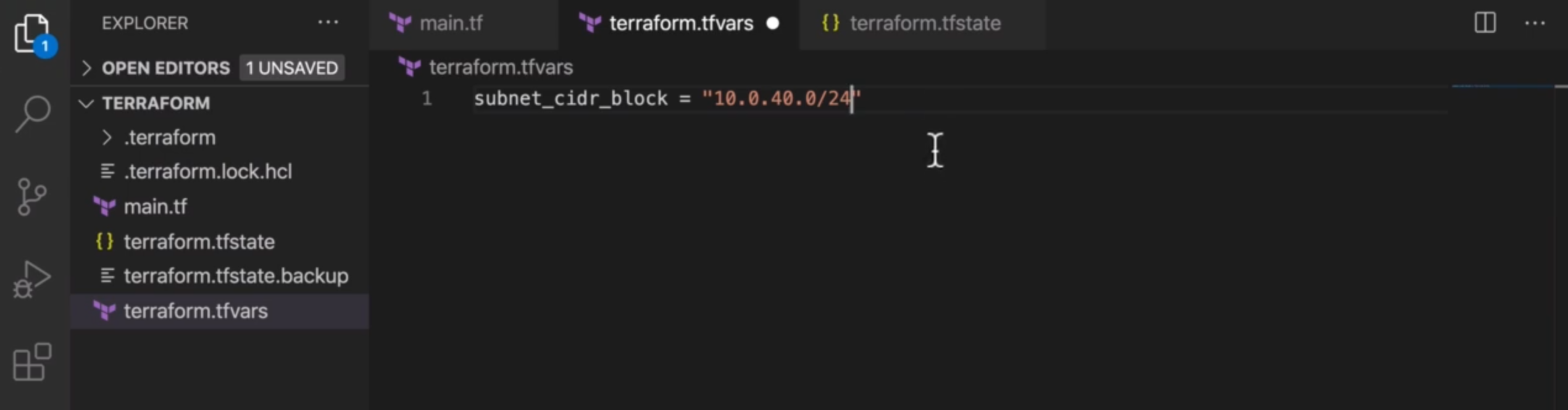
默认变量文件terraform.tfvars适用于单一环境,若要实现开发 / 生产 / 登台多环境共用同一配置模板,只需为不同环境创建独立的自定义变量文件,通过参数指定加载即可,实现参数隔离与配置复用:
- 为不同环境创建自定义变量文件,命名规范建议为
terraform-环境名.tfvars(如terraform-dev.tfvars、terraform-prod.tfvars),文件内按环境需求配置差异化的变量值 - 执行时通过参数指定 TerraForm 加载对应的自定义变量文件,terraform apply -var-file=terraform-dev.tfvars`
- 若不指定变量文件,且变量无默认值,TerraForm 会再次弹出交互式输入提示,确保变量有值后才会执行
默认值与类型约束
TerraForm 为变量提供了默认值和类型约束两个实用特性,既能简化默认配置的使用,又能强制规范变量的输入类型,适配团队协作和自动化流程。
variable "subnet_cidr_block" {
description = "subnet cidr block"
default = "10.0.10.0/24"
type = string
}
在变量块内通过default属性设置默认值,若未通过交互式输入、命令行、变量文件为变量传值,TerraForm 会自动使用默认值,且不会弹出输入提示;
在变量块内通过type属性指定变量的类型,TerraForm 支持字符串(string)、数字(number)、布尔值(bool) 等基础类型,若传入的值与指定类型不符,会直接抛出错误
- 示例:子网 CIDR 块是字符串类型,设置
type = string,若传入数组则会报错,提示「变量值类型无效,需要字符串」。
复杂类型变量
除了基础的字符串、数字类型,TerraForm 还支持列表、对象列表等复杂类型变量,适配多参数、多属性的复杂配置场景,同时可对复杂类型做精细化的类型约束。
- 字符串列表(list (string)):存储多个同类型值
将变量类型设为list(string),可存储多个同类型的字符串值(如 VPC + 多个子网的 CIDR 块列表),通过索引访问列表中的元素(TerraForm 列表索引从 0 开始)。示例:定义cidr_blocks = list(string),赋值为["10.0.0.0/16", "10.0.20.0/24"],VPC 引用第一个元素var.cidr_blocks[0],子网引用第二个元素var.cidr_blocks[1];
# .tfvar
cidr_blocks = ["10.0.0.0/16", "10.0.10.0/24"]
# .tf
variable "cidr_blocks" {
description = "cidr blocks for vpc and subnets"
type = list(string)
}
resource "aws_vpc" "development-vpc" {
cidr_block = var.cidr_blocks[0]
tags = {
Name: "development"
}
}
resource "aws_subnet" "dev-subnet-1" {
vpc_id = aws_vpc.development-vpc.id
cidr_block = var.cidr_blocks[1]
availability_zone = "eu-west-3a"
tags = {
Name: "subnet-1-dev"
}
}
- 对象列表(list (object ({}))):存储多属性的复杂对象
将变量类型设为list(object({属性名=类型})),可存储多个包含多属性的对象,并能为对象的每个属性单独设置类型约束,实现更精细化的参数规范;
# 变量值(通常在 tfvars 文件中定义)
cidr_blocks = [
{cidr_block = "10.0.0.0/16", name = "dev-vpc"},
{cidr_block = "10.0.10.0/24", name = "dev-subnet"}
]
variable "cidr_blocks" {
description = "cidr blocks and name tags for vpc and subnets"
type = list(object({
cidr_block = string
name = string
}))
}
resource "aws_vpc" "development-vpc" {
cidr_block = var.cidr_blocks[0].cidr_block
tags = {
Name: var.cidr_blocks[0].name
}
}
resource "aws_subnet" "dev-subnet-1" {
vpc_id = aws_vpc.development-vpc.id
cidr_block = var.cidr_blocks[1].cidr_block
availability_zone = "eu-west-3a"
tags = {
Name = var.cidr_blocks[1].name
}
}
- 定义方式:先指定变量类型为对象列表,再定义对象内的属性及对应类型,示例:
cidr_with_names = list(object({cidr_block=string, name=string})); - 赋值方式:赋值为包含多个对象的列表,示例:
[{"cidr_block":"10.0.0.0/16", "name":"dev-vpc"}, {"cidr_block":"10.0.20.0/24", "name":"dev-subnet"}]; - 引用方式:通过「列表索引 + 对象属性」访问,示例:VPC 的 CIDR 块
var.cidr_with_names[0].cidr_block,VPC 的名称var.cidr_with_names[0].name; - 实用价值:适配单变量传递多资源的多属性场景,同时强制约束每个属性的类型,团队协作时能清晰定义参数的结构和要求,结合 VS Code 的 TerraForm 插件,还能实现属性的自动补全提示。
环境变量
在 Terraform 配置中硬编码云服务凭据是严重的安全隐患,尤其是配置文件需要提交到 Git 仓库时,会导致凭据泄露,因此必须将凭据从配置文件中抽离。
- 绝对不要在
provider "aws"块中硬编码access_key和secret_key,若将包含敏感凭据的配置文件提交到 Git 仓库,会直接导致凭据泄露,造成云资源被盗用、产生不必要的成本等风险; - 抽离凭据时,可保留
region(区域)配置,该信息非敏感,可直接写在配置文件中,仅需删除access_key和secret_key两个敏感参数。
Terraform 支持两种主流的 AWS 凭据配置方式,均无需在配置文件中写敏感信息,且与 AWS CLI 的凭据配置逻辑完全一致,无需额外学习新的配置规则。
设置临时环境变量
通过在终端中设置AWS 官方标准环境变量,Terraform 会自动识别并读取,实现临时的身份验证,适用于单次操作、临时切换凭据的场景。核心环境变量(与 AWS CLI 通用,无引号包裹值):
AWS_SECRET_ACCESS_KEY:对应 AWS 的秘钥AWS_ACCESS_KEY_ID:对应 AWS 的访问密钥 ID
配置全局 AWS 凭据文件
将凭据配置在 AWS 的全局默认凭据目录中,实现所有终端、所有工具(包括 Terraform、AWS CLI)的全局复用,是日常使用的最佳实践。
凭据存储路径:用户主目录下的.aws隐藏目录,核心包含两个文件:
credentials:存储 AWS 的access_key和secret_key等敏感凭据config:存储默认区域(region)、配置文件等非敏感配置
配置方式:通过 AWS CLI 命令aws configure交互式配置,输入AWS Access Key ID、AWS Secret Access Key、Default region name等信息,命令会自动在.aws目录下生成并写入credentials和config文件。配置完成后,所有终端、所有支持 AWS 默认凭据的工具(包括 Terraform)都会自动读取.aws目录中的信息,无需重复设置,跨操作系统(Windows/Mac/Linux)均适用。直接执行terraform apply,Terraform 会自动加载.aws中的凭据和区域配置,正常完成 AWS 身份验证与资源操作。
自定义变量
除了识别云服务提供商的官方环境变量,Terraform 还支持自定义环境变量为配置中的变量传值,核心遵循TF_VAR_前缀规则,适用于为任意自定义变量设置全局 / 临时值。
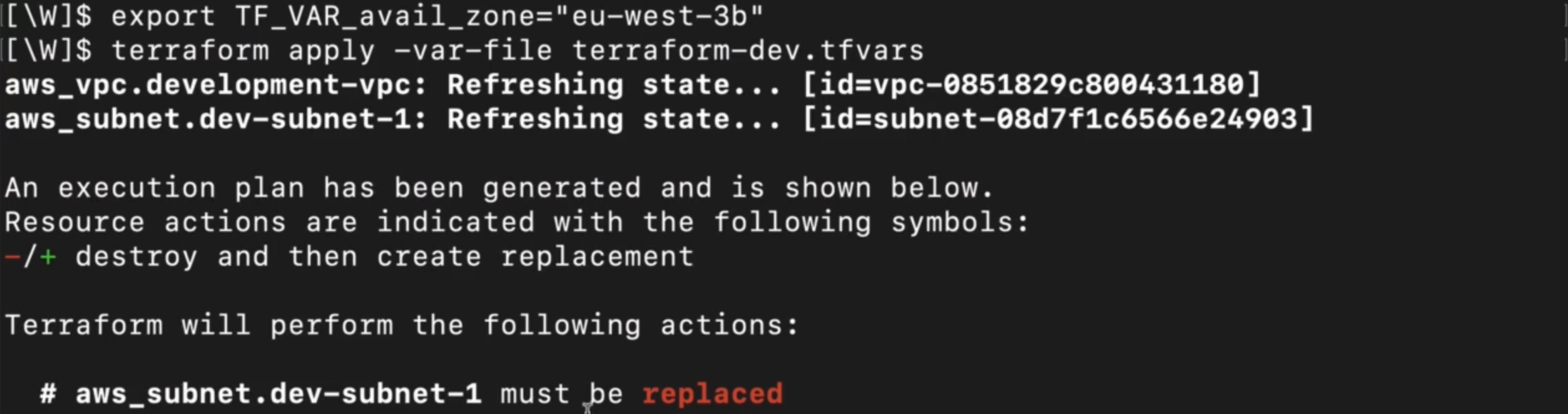
- 自定义环境变量必须以
TF_VAR_为前缀,后面跟配置文件中的变量名,等号前后不能有空格; - 示例:为配置中的
availability_zone变量传值,设置环境变量TF_VAR_availability_zone=eu-west-3b; - 在 Terraform 配置文件中,无需额外配置,直接通过
var.变量名(如var.availability_zone)引用即可,与普通变量的引用语法完全一致。生效规则方面与普通环境变量一致,终端中设置的TF_VAR_变量仅在当前会话生效,若需全局生效,可将其写入系统的环境变量配置文件;
配置修改与资源删除
目前创建的 VPC 和子网都没有设置名称,无法与其他资源区分,因此需要修改配置为资源添加名称。给资源命名的核心是添加tags参数,该参数是 AWS 所有资源都支持的通用属性,以键值对形式配置,可自定义多组键值对,键和值都能按需定义(比如标记资源的用途、所属环境)。
- 执行
terraform apply后,Terraform 会输出变更计划:其中黄色倾斜标识代表修改现有资源,区别于创建资源的绿色加号;计划中会明确显示仅对资源的tags属性做变更(添加名称及其他标签),资源的其他属性会保持不变,确认输入yes即可执行修改。 - 若想删除资源上已有的标签,只需在 Terraform 配置文件中,删除对应 tags 里的目标键值对即可,无需其他额外操作。

若不再需要某个资源(比如创建的子网),有两种具体的删除方法
删除配置文件中的对应资源块
直接在 Terraform 配置文件中,删除需要移除的资源完整配置块(比如删除整个aws_subnet "dev-subnet-1"块)。
执行terraform apply,Terraform 会对比当前状态(账户中存在该子网)和期望状态(配置中无该子网资源),自动判定需要删除该资源;变更计划中整个资源会被标上红色减号,代表该资源将被完整删除,包括其所有属性和标签。
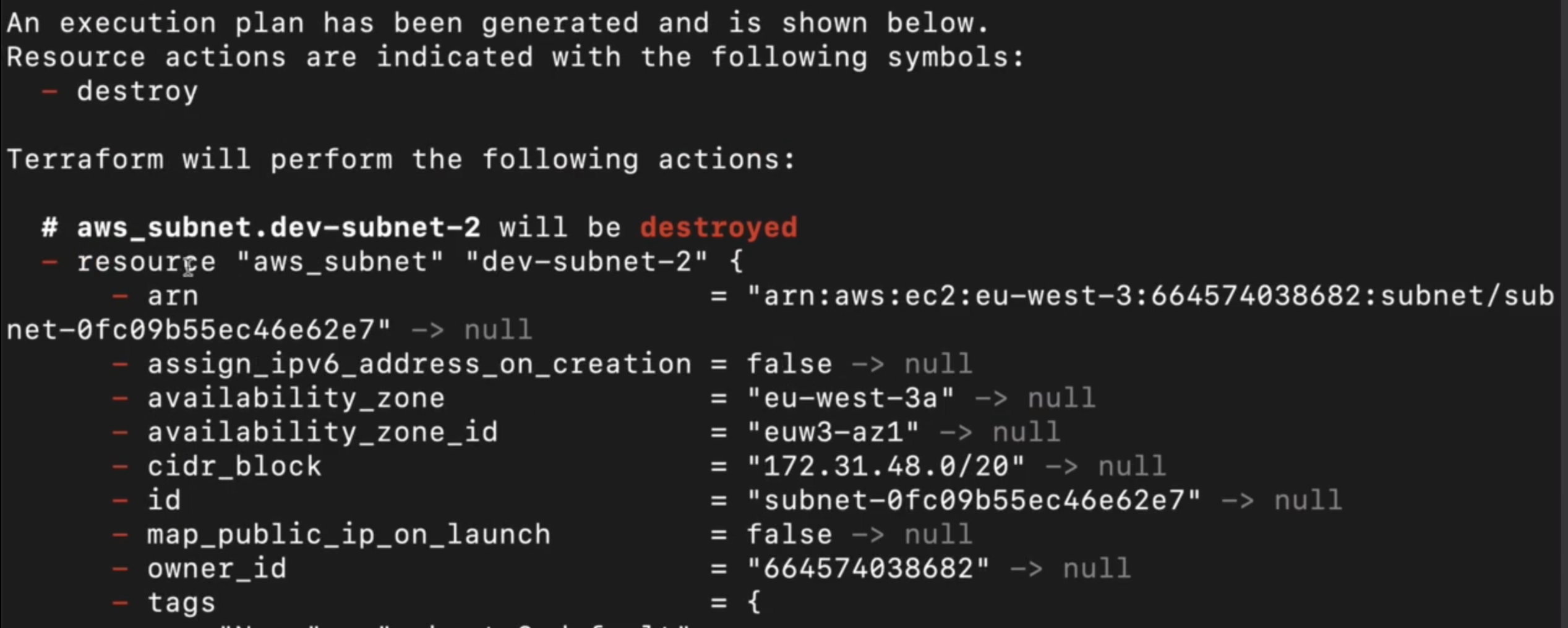
若临时取消删除,只需在确认环节输入yes以外的任意内容,即可终止terraform apply操作,再将删除的资源块恢复即可。
使用terraform destroy -target
无需修改配置文件,直接使用 Terraform 的销毁命令,通过-target参数指定需要删除的单个资源,命令格式为:terraform destroy -target=资源类型.资源自定义名称。
terraform destroy -target aws_subnet.dev-subnet-2
执行该命令后,输出的变更计划与terraform apply一致,会显示目标资源将被完整销毁,确认输入yes即可执行,操作完成后 AWS 控制台中对应的资源会消失。
建议优先使用修改配置文件 + terraform apply的方式删除资源,而非 terraform destroy -target 命令,因为使用destroy -target命令删除资源时,配置文件中依然保留着该资源的配置代码,会导致配置文件定义的期望状态,与 AWS 账户的实际基础设施状态不一致。
关于provider
Terraform 中的Provider是一个与特定技术对话的程序 / 代码,它负责将 Terraform 配置转换为目标技术可识别的 API 请求,从而让用户无需直接编写 API 调用逻辑。若要与 AWS 交互,需使用aws Provider;若要与 Jenkins 交互,需使用jenkins Provider。Terraform 官方提供了丰富的 Provider 支持,涵盖多种技术,可在Terraform Provider 官网查看完整列表。
-
官方 Provider由 HashiCorp(Terraform 开发公司)维护和提供,支持主流技术(如 AWS、Azure、GCP、Kubernetes、Docker 等),如
aws、azurerm、kubernetes等。 -
第三方 Provider由第三方技术合作伙伴开发和维护,支持特定厂商的产品或服务,示例:
github等。 -
社区 Provider由 Terraform 社区成员(开发者团队或个人)创建并发布,可在 Terraform Registry 中共享和使用。示例:
jenkinsProvider(多个开发者维护的版本)。
在 Terraform 项目目录下执行以下命令安装并初始化 Provider:
terraform init
- 该命令会自动下载并安装目标 Provider 的最新版本
- 生成
.terraform隐藏目录(存储已安装的 Provider 代码和版本信息)
执行terraform init后,会生成两个隐藏文件:
.terraform/:存储已安装的 Provider 代码和版本信息;.terraform.lock.hcl:锁定 Provider 的版本,确保团队协作时版本一致。
注意:Terraform 不会预装所有 Provider,需手动指定并安装所需的 Provider;
local provider
绝大多数 Terraform Provider(如 AWS、Azure、阿里云)都是为了通过 API 去操作远程云端的资源,而 local provider 的操作对象是本地电脑。不需要网络,不需要账号密码,是学习 Terraform 逻辑和处理本地文件生成任务的最佳工具。
local provider 主要有两大核心资源(Resources):
-
local_file:在本地创建一个文件,可以把其他资源的输出结果(比如服务器的 IP 地址、数据库密码)写入这个文件。 -
local_sensitive_file:功能和上面一样,但它会确保文件内容在 Terraform 的日志输出中被隐藏(脱敏),适合存放密钥。 -
data "local_file":读取本地已有的文件内容,供 Terraform 脚本后续使用。
你可能会想:“我用 echo "hello" > a.txt 就能搞定的事,为什么要用 Terraform?”
在自动化运维中,主要的使用场景如下
- 生成配置文件:可以用
local_file自动生成一个ansible_inventory.ini文件,把多台服务器的 IP 写进去直接给 Ansible 使用。 - 生成密钥对:在云端创建 SSH 密钥后,把私钥下载并保存到本地
~/.ssh/id_rsa - 生成 Kubernetes 配置:在创建完 K8s 集群后,自动生成
kubeconfig文件。
如下代码模拟了获取一个本地文件内容,并根据这个内容创建一个新文件。
terraform {
required_providers {
local = {
source = "hashicorp/local"
version = "~> 2.0"
}
}
}
# 资源:在当前目录下创建一个名为 "pet_name.txt" 的文件
resource "local_file" "example" {
filename = "${path.module}/pet_name.txt"
content = "My cat's name is Tom."
}
aws provider
vpc和subnet
接下来围绕 Terraform 创建 AWS 的 VPC、subnet等核心资源,讲解具体配置、资源引用、现有资源查询及核心特性的相关操作。注意,配置中使用的用户凭据,其所属的 AWS 账户 / 用户,必须拥有对应资源的创建权限和查询权限,否则无法完成资源创建和 Data 查询。
通过 AWS provider访问的每一种资源,都有其专属的资源名称,创建前必须先知晓这个名称;资源的标准命名格式为provider名称前缀_资源名称,这是provider为我们规定的官方资源名。在 Terraform 配置中,我们还能为创建的资源自定义名称,这个名称类似变量名,可按需命名(比如开发环境的 VPC 可命名为 dev_vpc);所有可创建的资源名称,都能在对应provider的文档中查询到。
定义 VPC 资源时,需以provider前缀_资源名为官方标识,同时自定义资源名称,在资源块内传入所需参数完成配置;subnet是隶属于 VPC 的资源,无法在 VPC 外部创建,因此创建subnet时,核心是解决引用未创建的 VPC 资源的问题,Terraform 支持引用同一配置上下文中尚未创建的资源,方式为自定义资源名称。属性名,通过这种方式可获取待创建资源的完整对象,进而访问其属性(比如 VPC 的 ID);
provider "aws" {
region = "eu-west-3"
access_key = "AKIAZV05TCKNDYYDZPEI"
secret_key = "dJRnI+tGBxT/sHZZT5hxaDj1C6V9Th7Z32qAhHUk"
}
resource "aws_vpc" "development-vpc" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "dev-subnet-1" {
vpc_id = aws_vpc.development-vpc.id
cidr_block = "10.0.10.0/24"
availability_zone = "eu-west-3a"
}
定义好 VPC 和subnet的配置后,通过terraform apply命令执行资源创建,这是 Terraform 将配置落地为实际云资源的核心命令,执行过程和验证要点如下:
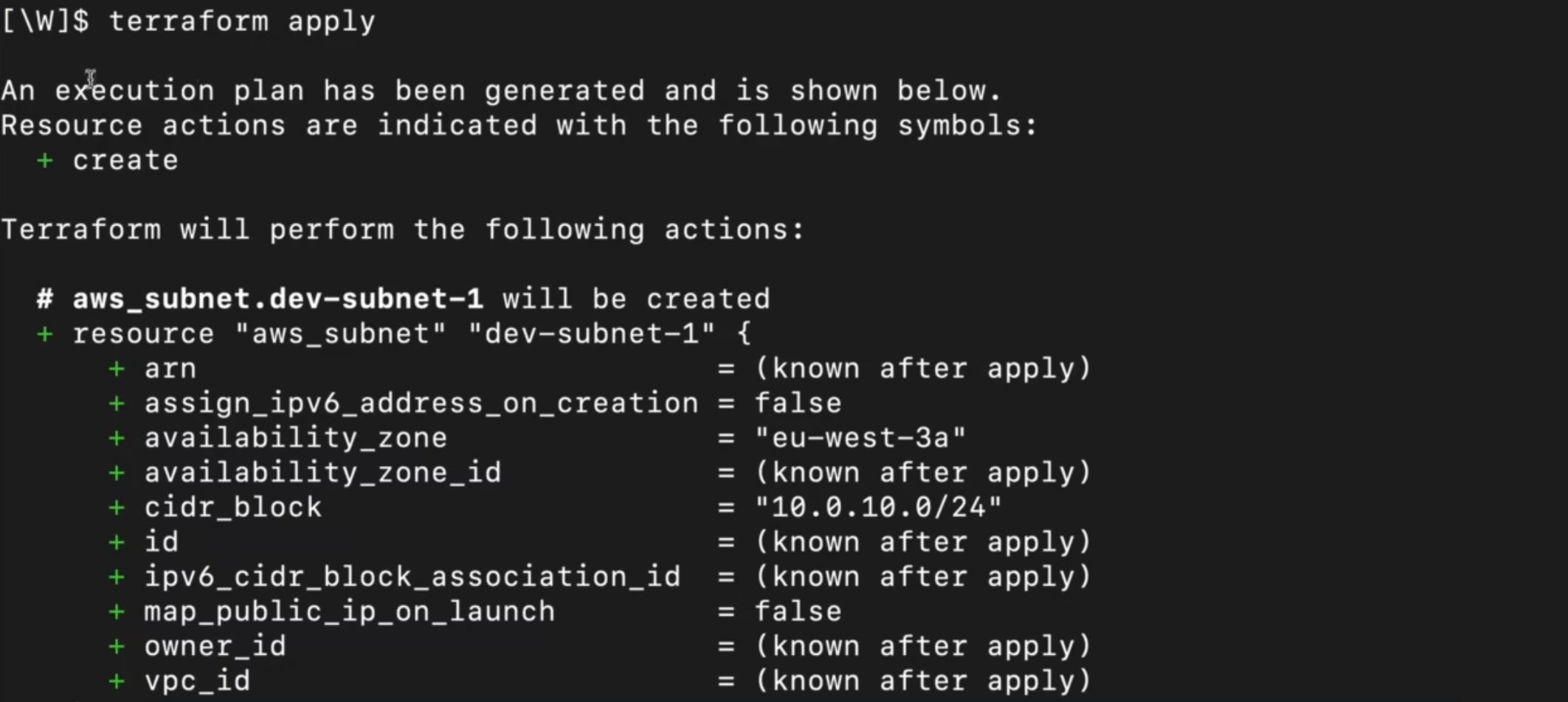
- 执行命令前需进入 Terraform 配置文件所在的文件夹,命令执行后 Terraform 会先计算计划状态,列出需要执行的操作,等待用户确认;
- 计划状态中会以绿色加号标识待创建的资源,同时展示资源的所有属性:自定义配置的参数(如 CIDR 块)、默认参数、未知参数(如资源 ID,这类参数会在资源实际创建后由 AWS 自动生成);
- 确认操作时输入yes即可执行部署,输入其他内容则取消操作;
- 部署完成后,Terraform 会输出资源创建结果,可进入 AWS 控制台刷新验证:能看到新创建的 VPC(及自定义的 CIDR 网段)、VPC 内的subnet(及指定的可用区、subnet段),所有部署前的未知参数,都会由 AWS 自动生成并赋值。
若想在已存在的 VPC(比如 AWS 默认 VPC)中创建subnet,无需重新创建 VPC,而是通过 TerraForm 的Data 组件查询现有资源信息。Data 组件是provider提供的另一类核心组件,与 Resource 组件的区别在于Resource 用于创建新资源,Data 用于查询现有资源 / 组件。
- Data 组件的命名格式与资源一致(provider前缀_资源名),与对应资源的命名高度相似;
- 配置 Data 块时,需传入搜索 / 过滤条件,告诉 Terraform 查询符合要求的资源,比如查询默认 VPC 可设置
default = true,也可按资源 ID、标签等键值对过滤,高级查询可使用 filter 属性定义自定义条件; - Data 查询的结果是资源的完整对象,可通过data. 自定义数据名称。属性名的方式访问所需属性(比如默认 VPC 的 ID),该规则适用于所有provider的 Data 组件。
data "aws_vpc" "existing_vpc" {
default = true
}
resource "aws_subnet" "dev-subnet-1" {
vpc_id = data.aws_vpc.existing_vpc.id
cidr_block = "10.0.10.0/24"
availability_zone = "eu-west-3a"
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号