

sql-总结-用postgre实验
背景:下面是学校 、 班级 、学生表
|
学校 5个校 |
班级 3所校,各有3个班级 |
学生 3个校的第1个班级,才有学生 |
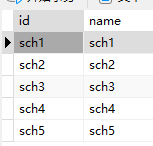 |
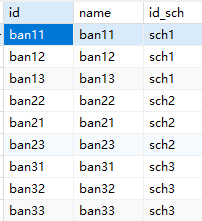 |
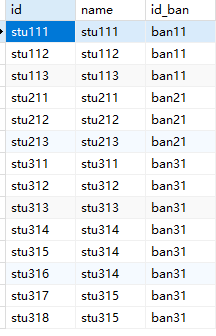 |
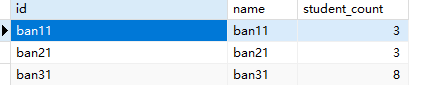
1、查询所有班的学生数
|
SELECT b.id, b.name, COUNT(s.id) as student_count |
SELECT b.id, b.name, COUNT(s.id) as student_count |
|
|
|
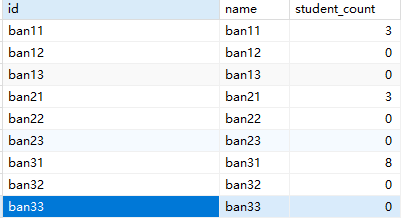
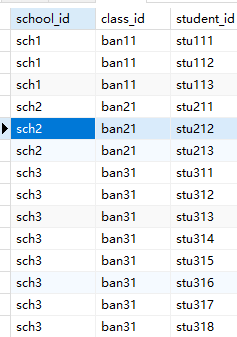
2.查询
| 查询某校学生 | 查询所有学校及其班级、学生信息 | |
SELECT s.*
FROM t_stu s
JOIN t_ban b ON s.id_ban = b.id
WHERE b.id_sch = 'sch1';
|
SELECT sch.id as school_id, b.id as class_id, s.id as student_id |
|
|
|
|

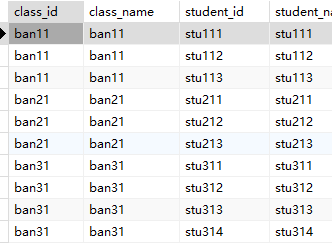
3.inner, left
INNER JOIN两个表中匹配的行-- 查询所有班级及其学生(只返回有学生的班级) |
LEFT JOIN 返回左表的所有行,即使右表中没有匹配-- 查询所有班级,包括没有学生的班级 |
left -- 查找没有学生的班级
|
|
SELECT b.id AS class_id, b.name AS class_name, |
SELECT b.id AS class_id, b.name AS class_name, |
SELECT b.id AS class_id, b.name AS |
|
|
|
|
|
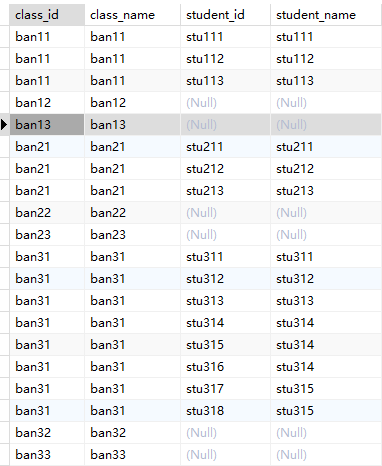
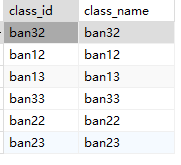
4.exists
|
EXISTS 用于检查子查询是否返回任何行 -- 查询有学生的班级
|
-- 查询有至少3个学生的班级
|
-- 查询没有学生的班级
|
-- 查询学校sch2中没有学生的班级
|
SELECT b.id, b.name
FROM t_ban b
WHERE EXISTS (
SELECT 1
FROM t_stu s
WHERE s.id_ban = b.id
);
|
SELECT b.id, b.name
FROM t_ban b
WHERE EXISTS (
SELECT 1
FROM t_stu s
WHERE s.id_ban = b.id
HAVING COUNT(*) >= 4
);
|
SELECT b.id, b.name
FROM t_ban b
WHERE NOT EXISTS (
SELECT 1
FROM t_stu s
WHERE s.id_ban = b.id
);
|
SELECT b.id, b.name
FROM t_ban b
WHERE b.id_sch = 'sch2'
AND NOT EXISTS (
SELECT 1
FROM t_stu s
WHERE s.id_ban = b.id
);
|
|
|
|
|
|




5.请查询姓名重复的学生
查处重复
|
删除重复,保留最小的id |
删除重复,保留最小的id --查询删除对象 |
SELECT
name,
COUNT(*) AS duplicate_count,
STRING_AGG(id, ', ') AS student_ids
FROM
t_stu
GROUP BY
name
HAVING
COUNT(*) > 1
ORDER BY
duplicate_count DESC;
|
-- 先找出要保留的记录(每个name的最小id)
WITH keep_ids AS (
SELECT MIN(id) AS id
FROM t_stu
GROUP BY name
)
-- 删除不在保留列表中的记录
DELETE FROM t_stu
WHERE id NOT IN (SELECT id FROM keep_ids);
|
-- 先找出要保留的记录(每个name的最小id)
WITH keep_ids AS (
SELECT MIN(id) AS id
FROM t_stu
GROUP BY name
)
-- 删除不在保留列表中的记录
select * FROM t_stu
WHERE id NOT IN (SELECT id FROM keep_ids);
|
|
|
不敢尝试 |
|
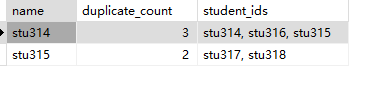
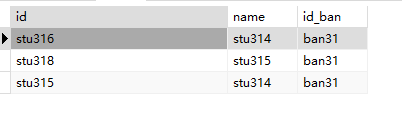
1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号