

NVIDIA GPU并行计算通信相关问题
今天客户问了两个 GPU计算通信的相关问题。
其实也不难,但是在解答的过程中自己也搜索学习了挺多。
就记录下来,分享下。如有问题、错误欢迎交流。
=======================================================
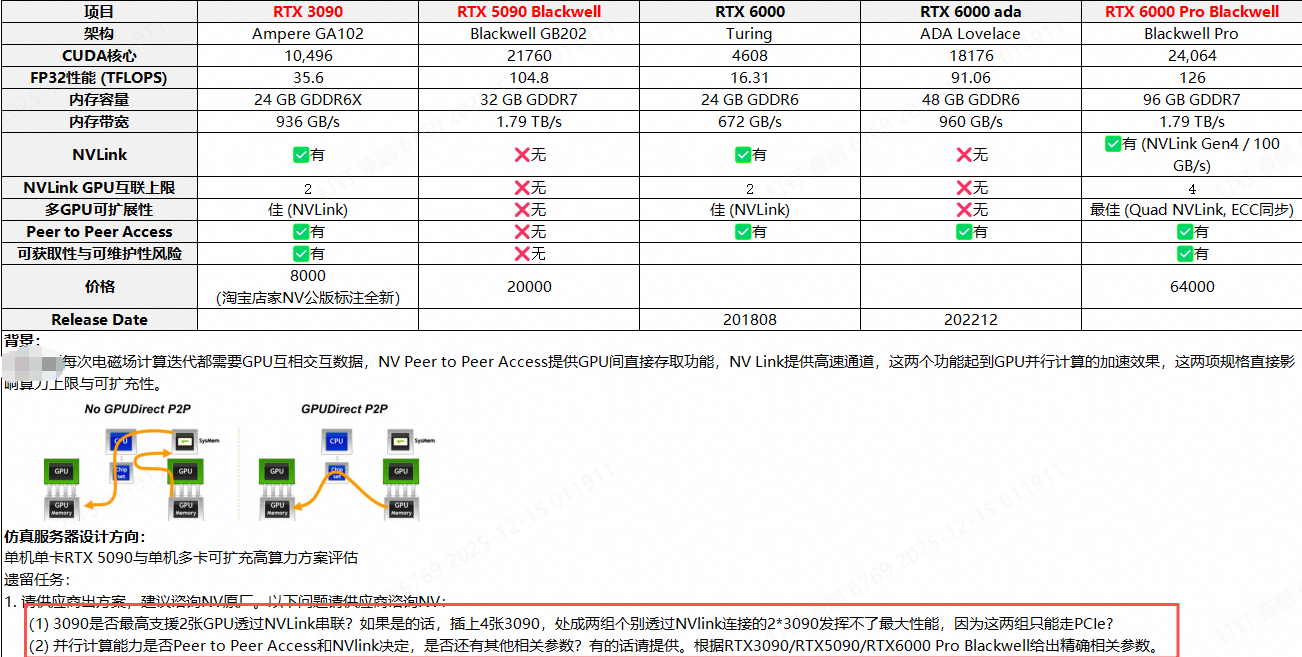
(图是客户自己总结的,有点错误。图中错误: RTX PRO 6000不支持NVLINK协议)
问题一:
3090是否最高支持2张GPU透过NVLink串联?如果是的话,插上4张3090,处成两组个别透过NVlink连接的2*3090发挥不了最大性能,因为这两组只能走PCIe?
答: RTX 3090的NVLINK仅支持双GPU之间的112GB/s的NVLINK互联,4张RTX 3090仅能组2组NVLINK,跨组之间的通信还是得经过PCIE 4.0 x16。所以4卡RTX 3090的跨组通信的并行计算性能会受限。
问题二:
并行计算能力是否PeertoPeer Access和NVinK决定,是否还有其他相关参数?有的话请提供,根据RTX3090/RTX5090/RTX600 Pro Blackwel给出精确相关参数。
答:多卡并行计算能力的强弱,除了本卡GPU核心CUDA和Tensor核心的差异外,还有并行计算的通信问题。通信问题更多是要考虑带宽、时延。NVlink和PeertoPeer Access是通信的硬件层间一部分因素,但是还有其他因素,还有软件层面因素——NCCL协议。
硬件层面的解答:
硬件层面还需要考虑显存带宽、显存颗粒类型、多机多卡的话还要考虑RDMA网络。
单机多卡:
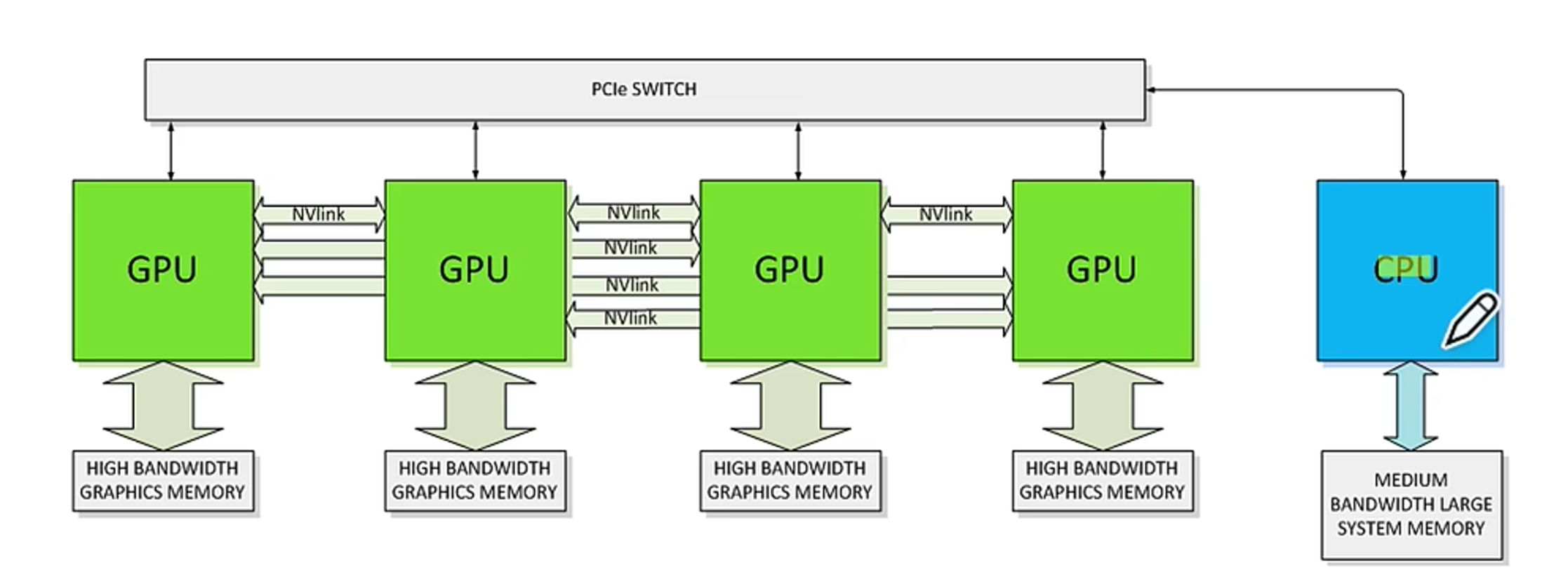
图中展示的是1 CPU带4 NVLINK互联的GPU拓补图。
CPU通过PCIE总线对4 GPU发起一个任务,GPU通过NVLINK互联这样两者形成一个环,方便做集合通信。
在做并行计算时,GPU需要反复多次调用显存的数据,这里就关系到GPU的显存速率和颗粒类型。显存的速率越大,越有利于GPU调取数据计算,也有利于多个GPU之间的并行计算。显存的带宽也由显存颗粒决定,HBM>GDDR7>GDDR6X>GDDR6。
例如:NVIDIA的桌面级AI算力小盒子GB10,单机FP4算力可达1 PFLOPS,128GB 显存,支持NVLINK C2C带宽,带200GE IB接口,但是显存带宽只有273GB/s,导致在多机互联的集群场景下通信效率低,训练推理的效果并不好。现在效果最好的是2台GB10互联,再多就没有用了。
多机多卡互联:
若是多级多卡互联,一般会选择RDMA网络,远程直接访问内存网络。大大降低时延,提高带宽。一般会有IB网络、Roce网络两种路线选择。
IB网络:NVIDIA的专利,时延低,专门为RDMA网络设计,但是成本贵。
Roce网络:基于以太网协议实现的RDMA网络,时延会比IB稍高,但是胜在成本低,可以很好接入现有的IP网络。
软件层面:
通信层面的软件优化还有NCCL协议。
NCCL:通过感知GPU的高级拓补(PCIE、NVLINK、IB网络等),优化GPU通信路径。 NCCL API从CPU 启动,GPU执行,在 GPU 内存之间移动或交换数据。最后利用 NVLink 聚合多个高速 NIC 的带宽。
例如:
RTX 5090虽然没有PeertoPeer Access,但是PCIE 5.0 X16 + NCCL的情况下:
4卡场景:
RTX 5090的NCCL带宽峰值达28.98 GB/s,较RTX 4090(19-21 GB/s)提升约50%,体现单机4卡场景下的显著优势。
8卡场景:
8卡RTX 5090的NCCL性能与RTX 4090基本持平,推测因跨CPU数据传输延迟增加,且PCIe通道资源竞争加剧,成为多卡扩展的潜在瓶颈。所以在8卡的情况下,PRO 6000支持P2P且有NCCL,整体性能好于8卡 RTX 5090。
当然英伟达GPU基本支持NCCL,在多卡通信中,PeertoPeer Access是基础能力,NCCL上层优化的性能放大器。NCCL中,有P2P会优先选择P2P,如果没有则会选择其他路径。(有NVLINK,就会有P2P;但是有P2P,不一定有NVLINK——例如PRO 6000,P2P是经过PCIE 5.0)。
NCCL的存在让小规模的单机多卡算力并不一定需要NVLINK,PCIE 5.0 x16 + NCCL(P2P)可以有效提升单机多卡的算力,同时降低硬件的成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号