🚀《拒绝调包侠!从零手写 Python 目录扫描器:v0
摘要:在网络安全学习中,我们习惯了使用 Dirsearch、Gobuster 等成熟工具。但你是否想过,如果让你从零开始写一个目录扫描器,你会遇到哪些坑?本文不直接甩代码,而是复盘我开发 DirScanner-Lab 的全过程。从 v0.1 的单线程龟速,到 v0.4 的多线程专业版,每一个 .1 的版本号背后,都是一个真实的报错和一个具体的解决方案。
🌟 项目源码已开源:https://github.com/LanSang11/DirScanner-Lab
📖 前言:为什么要重复造轮子?
刚开始学渗透测试时,我也觉得“调包”很香:import requests,几行代码就能扫目录。直到有一次,我想修改字典的编码规则,却发现看不懂别人几千行的源码;想增加多线程,结果程序直接死锁卡住。
那一刻我决定:扔掉现成工具,自己从头写一个!
这个项目被我命名为 **DirScanner-Lab**,寓意是一个不断试错、不断进化的实验室。它不是最完美的工具,但它记录了一个新手如何一步步解决真实问题的全过程。
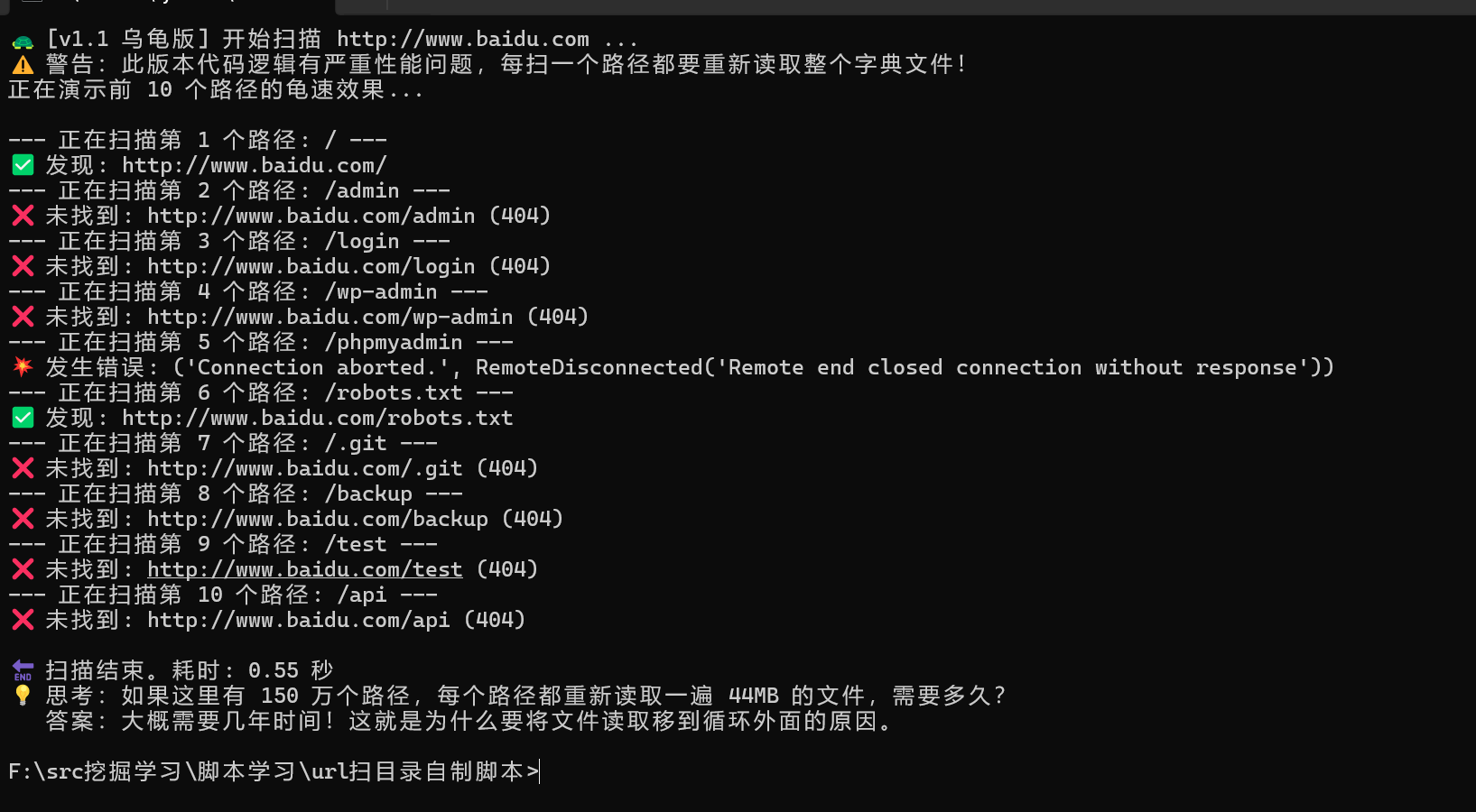
🐢 阶段一:v0.1 单线程原型 —— “慢得让人怀疑人生”
初衷:用最简单的逻辑实现功能,验证思路。
代码逻辑:读取字典 -> requests.get -> 打印结果。
# v0.1 核心逻辑伪代码
for path in open('dict.txt'):
resp = requests.get(url + path)
if resp.status_code == 200:
print(f"[+] Found: {path}")
❌ 遇到的真实痛点
- 效率极低:目标服务器响应慢或网络波动时,程序会傻等几十秒。扫描 1000 个路径需要半小时,简直是在“数羊”。
- 体验差:屏幕长时间无输出,我经常以为程序死了,结果它还在跑。
💡** 我的思考**:网络 IO 是瓶颈,必须引入并发机制。但这一步,让我踩了后面两个大坑。
(
 )
)
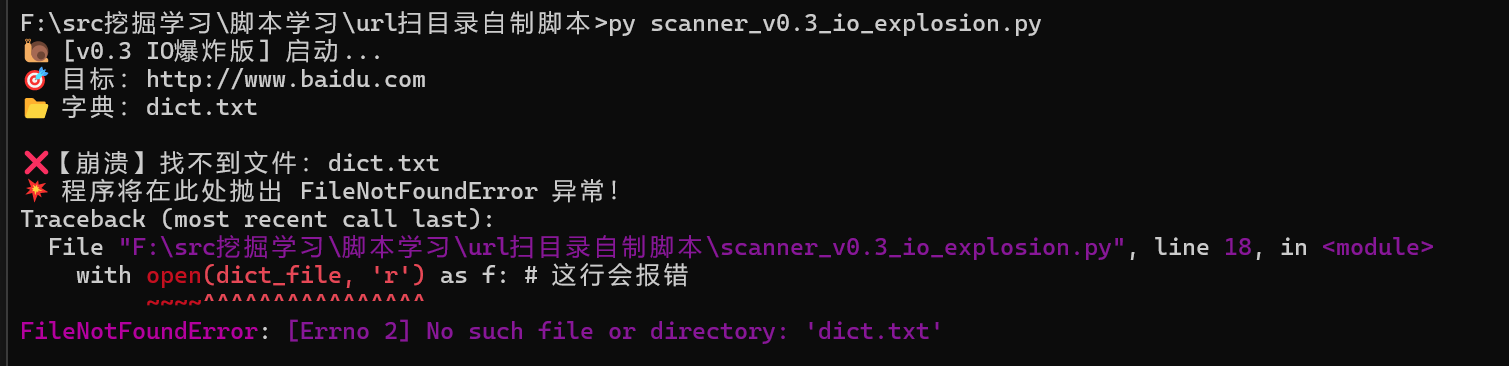
💥 阶段二:v0.2 编码崩溃 —— “为什么读到一半报错了?”
改进:为了扫得更全,我换上了一个 45MB 的大字典(包含中文路径)。
❌** 遇到的报错**:
程序跑到第 3421 行突然崩溃,控制台一片红:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc4 in position 10: invalid continuation byte
🔍 原因分析
网上的字典来源复杂,有的用 UTF-8,有的用 GBK(中文 Windows 常见)。我的代码只写了 encoding='utf-8',一旦遇到 GBK 字符就直接崩溃。
✅ 解决方案 (v0.2)
我引入了一个“尝试多种编码”的机制。不再假设字典是某种编码,而是按顺序尝试 utf-8 -> gbk -> latin-1,直到成功读取。
# v0.2 核心改进代码片段
encodings = ['utf-8', 'gbk', 'latin-1']
for enc in encodings:
try:
with open(file, encoding=enc) as f:
lines = f.readlines()
print(f"✅ 成功使用 {enc} 编码读取字典")
break
except UnicodeDecodeError:
continue
结果:无论字典是什么“奇葩”编码,都能顺利加载。这让我明白:健壮性比功能更重要。
🧵 阶段三:v0.3 多线程死锁 —— “为什么程序跑完了却不退出?”
改进:引入 threading 和 queue,开启 20 个线程并行扫描。
⚡** 效果**:速度瞬间提升 20 倍!原本半小时的任务,现在一分钟搞定。
❌ 遇到的诡异现象
这是我最头疼的一个 Bug。
扫描进度明明显示 100%,所有任务都跑完了,但程序卡住不动,光标一直闪烁,必须手动按 Ctrl+C 才能看到统计结果。
🔍 深度调试
通过查阅文档和断点调试,我发现问题出在 queue.join()。
主线程在等待所有任务调用 task_done()。如果在 scan_path 函数中,线程在 get() 之后、task_done() 之前发生了未捕获的异常(比如网络超时),那么 task_done() 就永远不会执行。队列认为还有任务没完成,主线程就永远等待。
✅ 解决方案 (v0.3)
使用 try...finally 结构,强制确保 task_done() 在任何情况下(包括异常)都会被执行。
# v0.3 关键修复代码
while True:
try:
path = q.get(timeout=0.5)
except queue.Empty:
break
try:
# 执行扫描逻辑
requests.get(...)
except Exception as e:
# 记录错误,但不中断
pass
finally:
q.task_done() # 无论成败,必须标记完成!
结果:程序扫描结束后自动优雅退出,不再卡死。这个 Bug 让我对多线程的生命周期有了深刻理解。
(
 )
)
🚀 阶段四:v0.4 专业测试版 —— “像黑客工具一样易用”
到了 v0.4,我不再满足于“能跑”,而是追求“好用”。
❌ 遗留问题
- 参数硬编码:改 URL、线程数都要改代码,太 Low 了。
- 无效扫描:字典里包含
#开头的注释行,导致大量无效请求。 - 无反馈:不知道扫了多少,还剩多少。
✅ 终极方案
- CLI 交互:引入
argparse,支持-u,-t,--limit等参数。 - 智能过滤:自动跳过注释行和特殊字符。
- 实时进度条:利用
\r覆盖当前行,实时显示进度% | 速度 p/s | 发现数。
🎯** 最终运行效果**:
python my_scanner_pro_v0.4.py -u http://target.com -t 20 --limit 2000
📂 正在加载字典... ✅ 有效路径: 2000, 跳过: 150 (编码: utf-8)
⏳ 进度: 1000/2000 (50.00%) | 发现: 3 | 速度: 21.5 p/s
[+] 发现: http://target.com/admin (状态码: 200)
📥 源码获取与扩展
本项目的所有代码(从 v0.1 到 v0.4 的演变过程)都已整理并在 GitHub 开源。
👉 仓库地址: https://github.com/LanSang11/DirScanner-Lab
🛠️ 如何运行?
- 克隆项目:
git clone https://github.com/LanSang11/DirScanner-Lab.git
cd DirScanner-Lab
- 安装依赖:
pip install requests
- 运行测试 (使用内置的小字典):
python my_scanner_pro_v0.4.py -u http://example.com --limit 100
⚠️** 关于字典的说明:
为了保持仓库轻量及合规,GitHub 上仅提供了 **dict_sample.txt** (测试用小字典)**。
如需进行大规模扫描,请自行准备字典文件(如 dirb, rockyou 等),并通过 -d 参数指定。这也是为什么我将项目命名为 Lab —— 希望你在这里加入自己的实验数据。
(👉 此处建议你自己加一段话:例如“大家在运行如果遇到某某问题,欢迎在 GitHub 提 Issue,我们一起讨论”,这样显得更亲切)
📝 总结与展望
从 v0.1 到 v0.4,这个小小的扫描器不仅提升了我的 Python 编程能力,更让我理解了“工具的本质是解决具体问题”。
- v0.1 教会我基础逻辑;
- v0.2 教会我处理异常和编码;
- v0.3 让我攻克了多线程并发难题;
- v0.4 则让我学会了如何设计用户友好的接口。
接下来,我计划在这个项目中加入正则匹配敏感信息和代理池支持的功能。如果你对某个功能感兴趣,或者有更好的优化建议,欢迎去我的 GitHub 仓库 DirScanner-Lab 提 Issue 或 PR!
拒绝做“调包侠”,让我们一起动手,造出更适合自己的轮子!
免责声明:本工具仅供网络安全学习与研究使用,严禁用于未授权的攻击行为。使用者需自行承担法律责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号