

设计代码检索系统目录中重名文件
一、目的
随着系统长期使用,不同盘符中往往会出现文件名相同但存储位置不同的文件,这类文件可能来自重复下载、拷贝或软件缓存,容易造成磁盘空间浪费。
本文所述程序旨在:
跨多个盘符扫描系统文件
快速定位重名文件(不区分大小写)
为用户后续的人工比对、清理重复文件提供依据
在保证扫描完整性的同时,尽可能提升扫描效率
二、实现原理
该程序通过 多线程并发扫描 + 文件名索引 的方式,实现对 Windows 系统中重名文件的高效检索。其核心设计思想如下:
- 数据结构设计
self.file_map = defaultdict(list)
使用 defaultdict(list) 作为核心索引结构;
键(key):文件名(统一转换为小写,适配 Windows 不区分大小写的特性);
值(value):包含该文件所有出现位置的列表,每一项为:
(完整路径, 文件大小, 修改时间)
这种结构能够在一次遍历过程中,快速聚合同名文件的全部信息。
- 多线程并发扫描机制
(1)按盘符划分扫描任务
每一个盘符(如 C:、D:、E:)由一个独立线程负责;
通过 threading.Thread 同时启动多个扫描任务;
充分利用多核 CPU 与磁盘 IO 并发能力,加速整体扫描过程。
(2)线程安全控制
self.lock = threading.Lock()
多线程会同时向 file_map 写入数据;
使用互斥锁 Lock 确保同一时刻只有一个线程修改共享数据;
避免数据竞争与结果错乱。
- 扫描与过滤策略优化
(1)目录级过滤
在遍历目录时,主动跳过以下系统相关目录:
$*
System*
Recovery*
Windows
dirs[:] = [d for d in dirs if not d.startswith(('$', 'System', 'Recovery', 'Windows'))]
这样可以:
显著减少无意义扫描;
避免权限问题频繁触发异常;
提升整体扫描速度。
(2)异常容错处理
在访问文件元数据时,可能遇到以下问题:
权限不足(PermissionError)
文件瞬时不可用(OSError)
程序对这些异常进行捕获并直接跳过,保证扫描过程不中断。
- 文件信息一次性获取
stat = os.stat(full_path)
在扫描过程中:
一次性获取文件大小(st_size)与修改时间(st_mtime);
避免重复 IO 操作;
为后续排序与展示提供完整信息基础。
5. 重名文件判定逻辑
扫描完成后,对索引结果进行过滤:
duplicates = {
name: paths
for name, paths in self.file_map.items()
if len(paths) > 1
}
同一文件名对应路径数量 > 1
即认定为一组重名文件
⚠️ 注意:
此处判定基于文件名,而非内容哈希,因此适用于:
初步筛查
空间整理
人工复核场景
- 结果排序与格式化输出
(1)按修改时间排序
file_info_list.sort(key=lambda x: x[2], reverse=True)
每组重名文件内部,按最近修改时间降序排列;
便于判断哪个文件是最新版本。
(2)人性化展示
文件大小自动转换为 KB / MB / GB;
修改时间格式化为标准时间字符串;
清晰展示每个文件的完整路径。
核心思想总结
以空间换时间,以结构换效率
通过一次全盘遍历建立文件名索引;
利用哈希表快速定位重名项;
结合多线程加速 IO 密集型扫描任务;
在保证健壮性的前提下,兼顾性能与可读性。
三、核心代码
class DuplicateFileFinder:
def __init__(self):
# 存储文件名: [(完整路径, 大小, 修改日期), ...]
self.file_map = defaultdict(list)
self.lock = threading.Lock()
def format_size(self, size_bytes):
"""将字节数转换为易读的格式"""
for unit in ['B', 'KB', 'MB', 'GB', 'TB']:
if size_bytes < 1024.0:
return f"{size_bytes:.1f} {unit}"
size_bytes /= 1024.0
return f"{size_bytes:.1f} PB"
def scan_drive(self, drive_letter):
"""扫描单个盘符"""
drive = f"{drive_letter}:\\"
if not os.path.exists(drive):
print(f"盘符 {drive} 不存在,跳过")
return
print(f"正在扫描 {drive}...")
try:
for root, dirs, files in os.walk(drive, topdown=True):
# 跳过系统目录以提高速度
dirs[:] = [d for d in dirs if not d.startswith(('$', 'System', 'Recovery', 'Windows'))]
for file in files:
full_path = os.path.join(root, file)
try:
# 一次性获取文件所有信息
stat = os.stat(full_path)
size = stat.st_size
mtime = datetime.fromtimestamp(stat.st_mtime)
# 使用文件名作为键(Windows不区分大小写)
key = file.lower()
with self.lock:
self.file_map[key].append((full_path, size, mtime))
except (PermissionError, OSError):
continue # 跳过无权限访问的文件
except Exception as e:
print(f"扫描 {drive} 时出错: {e}")
def find_duplicates(self, drives=None):
"""
:param drives: 要扫描的盘符列表,如 ['C','D','E'];
为 None 时使用默认盘符
"""
"""扫描多个盘符并找出重复文件"""
if drives is None:
drives = ['C', 'D', 'E', 'F']
threads = []
for drive in drives:
thread = threading.Thread(target=self.scan_drive, args=(drive,))
threads.append(thread)
thread.start()
# 等待所有扫描完成
for thread in threads:
thread.join()
# 筛选出重复的文件(按文件名)
duplicates = {name: paths for name, paths in self.file_map.items()
if len(paths) > 1}
return duplicates
def print_results(self, duplicates):
"""格式化输出结果"""
if not duplicates:
print("\n未发现重名文件!")
return
print(f"\n发现 {len(duplicates)} 组重名文件\n")
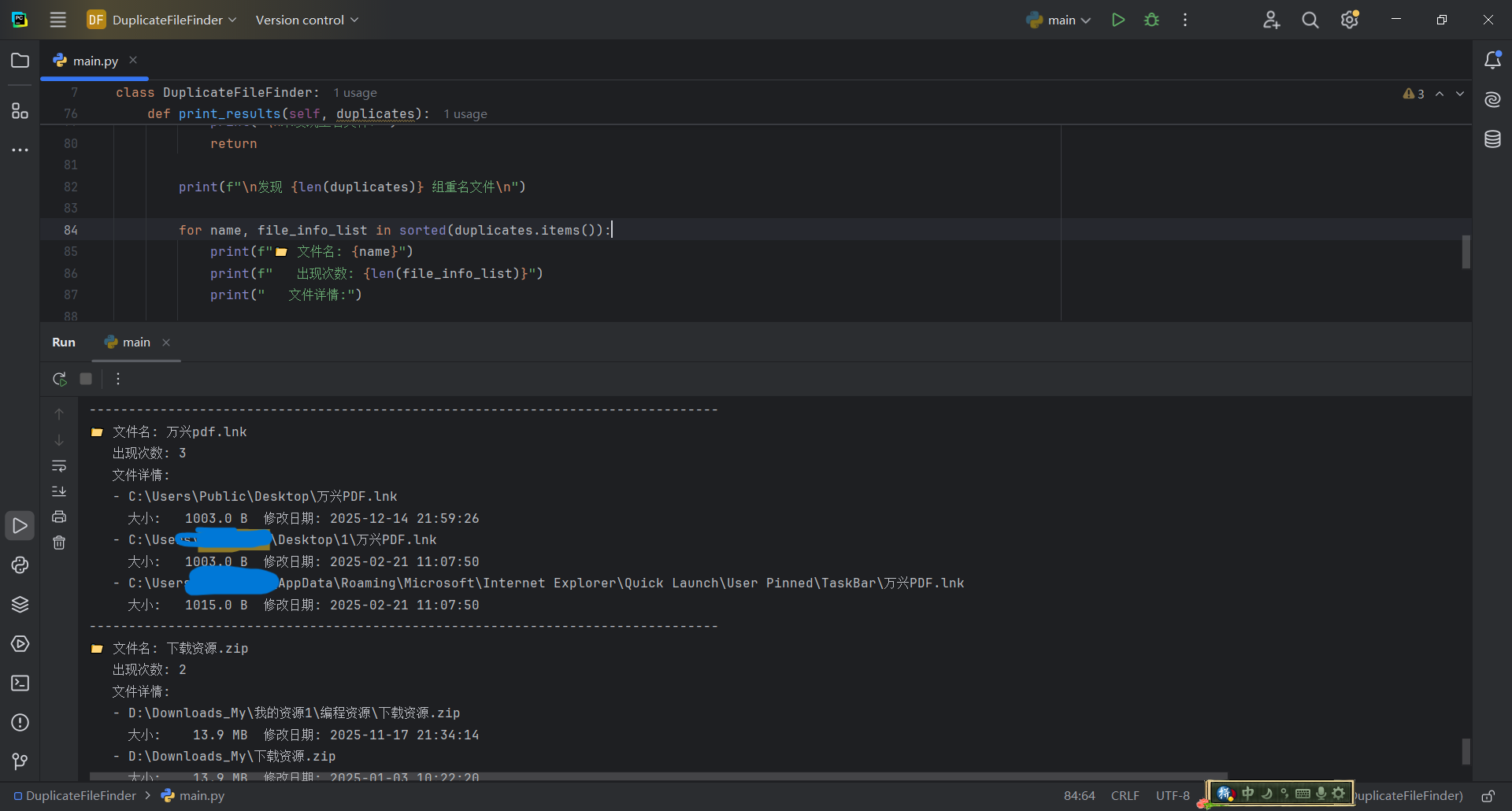
for name, file_info_list in sorted(duplicates.items()):
print(f"📁 文件名: {name}")
print(f" 出现次数: {len(file_info_list)}")
print(" 文件详情:")
# 按修改时间排序(最新的在前)
file_info_list.sort(key=lambda x: x[2], reverse=True)
for path, size, mtime in file_info_list:
size_str = self.format_size(size)
time_str = mtime.strftime('%Y-%m-%d %H:%M:%S')
print(f" - {path}")
print(f" 大小: {size_str:>10s} 修改日期: {time_str}")
print("-" * 80)
if __name__ == "__main__":
# 创建扫描器实例
finder = DuplicateFileFinder()
# 扫描指定盘符(可修改列表)
drives_to_scan = ['C', 'D', 'E', 'F','H']
# drives_to_scan = ['H','I'] # 单盘测试用
print("开始扫描,这可能需要一些时间...")
duplicates = finder.find_duplicates(drives_to_scan)
# 输出结果
finder.print_results(duplicates)
四、结果展示
🗓️ 文章信息
更新日期:2025年12月15日
当前版本:v1.1
分类: 技术博客
关键词:Python、Power BI、Tableau、Qlik、Snowflake
原创声明
本文由作者原创并于2025.11.24 首发于 CSDN 与 博客园 平台。
欢迎学习与分享,但请尊重原创,转载请保留署名与出处。
未经许可,禁止用于商业用途或二次发布。
更新记录
2025.12-15|版本升级
重构核心扫描逻辑,引入 面向对象设计(DuplicateFileFinder),提升代码可读性与可维护性
扫描阶段由仅记录路径,升级为同时采集 文件大小与修改时间,为后续人工判断与清理提供更多依据
新增 文件大小格式化输出,结果展示更加直观友好
对重复文件组按 修改时间倒序排序,优先展示最新文件,降低误删风险
扩展系统目录过滤规则(如 Windows 目录),进一步提升扫描效率与稳定性
优化异常处理逻辑,确保在权限受限或文件异常场景下扫描过程不中断
本次更新在保持原有“多线程 + 哈希索引”高性能设计的基础上,显著增强了结果信息量与实用性,更适合作为日常系统清理与磁盘整理工具使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号