

🌟 ChatGPT训练原理
一句话总结:
ChatGPT = AI通过"读书-培训-排序-优化"四步成长,
人类用"排序"教它"什么回答更好",不是"打分"! 📚
🧠 一、训练真相:四步走
✅ 第一步:预训练(吃遍全网书)
- 真实过程:
用3000亿个token(相当于300万本书)训练语言模型,学习语言规律。 - 关键数据:
- GPT-3.5训练数据量:45TB(互联网公开文本)
- 模型参数:1750亿(比GPT-3的1750亿略多)
- 为什么不是"背书":
AI只记住语言模式(如"天气"后常跟"晴"),不存储具体文本。
✅ 第二步:监督微调(SFT - 人类教说人话)
- 真实过程:
人类提供20万条高质量问答对(如"今天天气?"→"晴,15°C"),让AI学会结构化回答。 - 金融案例:
金融分析师给AI输入:
{"question": "今日还款人数?", "answer": "5人"}
{"question": "今日还款总金额?", "answer": "2901.25元"}
→ AI学会"金融问题的标准回答格式"。
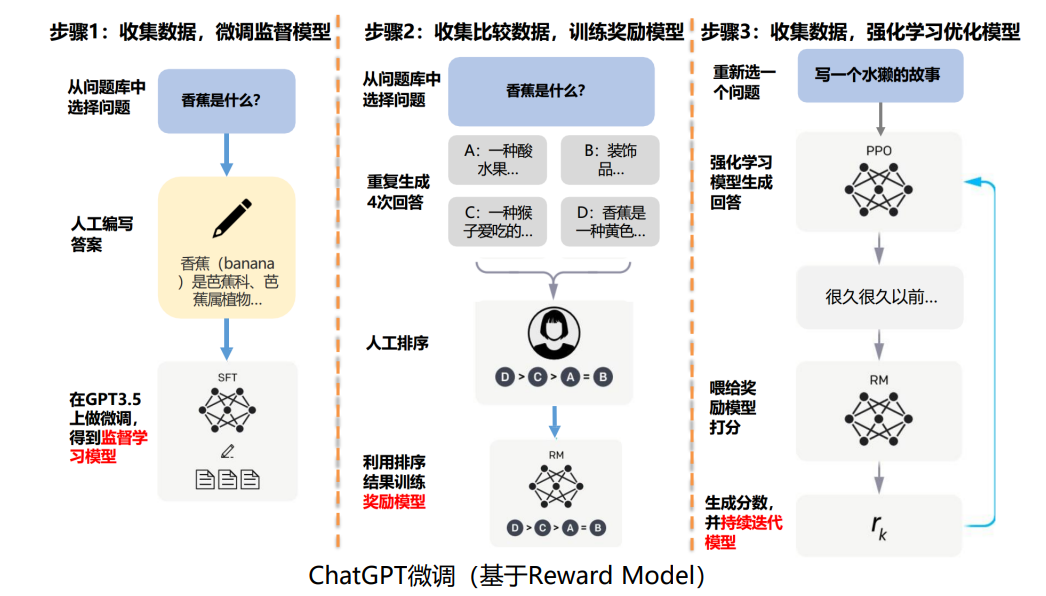
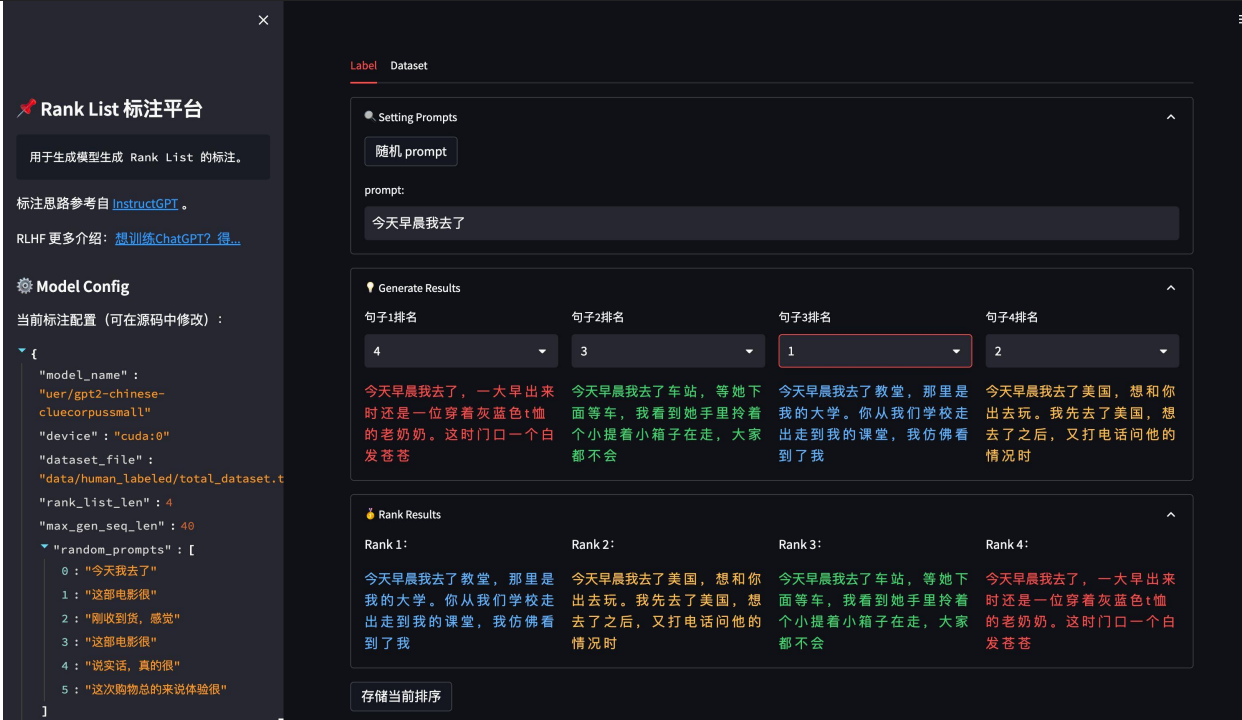
✅ **第三步:奖励建模(人类排序,不是打分!)
- 真实过程:
- 让SFT后的模型对同一问题生成3-5个回答
- 人类标注员对回答排序(如"回答A > 回答B > 回答C")
- 用排序数据训练奖励模型(Reward Model)
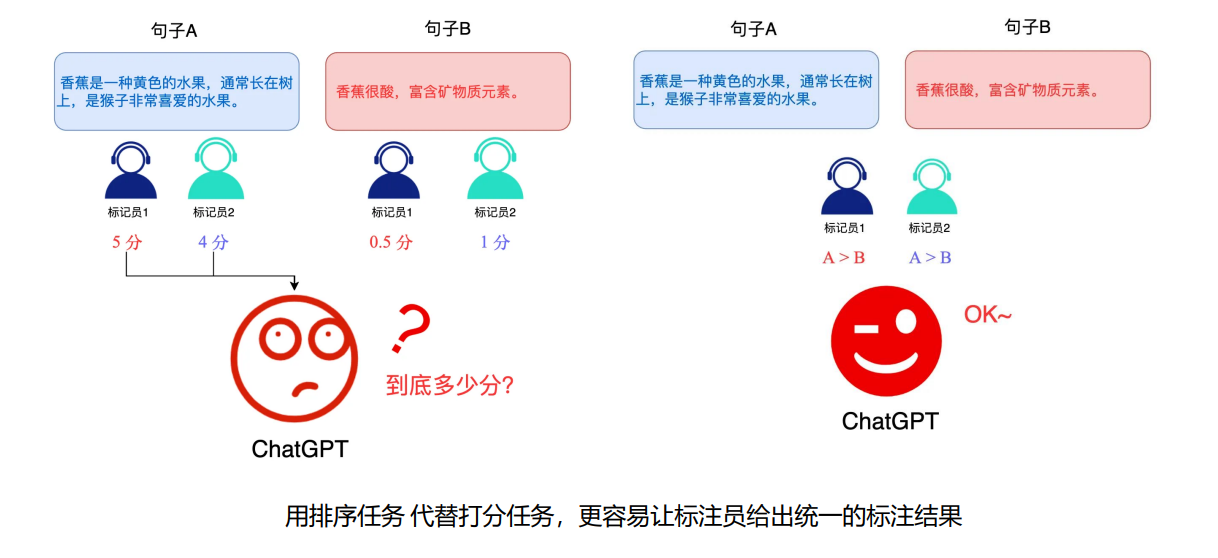
- 为什么用排序?
人类更容易判断"哪个回答更好"("A比B好"),
比"给A打8分,B打7分"更可靠(减少主观误差)。 - 金融场景案例:
问题:"生成今日还款报告"
AI生成3个回答:- A: "今日还款5人,总金额2901.25元"
- B: "5人还款,金额2901.25元"
- C: "今日还款5人,总金额2901.25元,平均580.25元"
人类排序:C > A > B(因为C最完整)
奖励模型学习:C > A > B→ 未来优先生成C类回答。
✅ 第四步:强化学习(PPO优化)
- 真实过程:
- 奖励模型给AI生成的回答打分(基于排序学习的偏好)
- 用PPO算法(Proximal Policy Optimization)优化模型
- 循环5000轮,让AI持续生成更符合人类偏好的回答
- 金融价值:
通过5000轮优化,AI学会:
"金融报告必须包含'用户数/总金额/平均',且数据精确"
→ 生成报告时自动补全关键字段,减少人工修改。
📊 二、关键数据对比
| 阶段 | 人类参与方式 | 数据量 | 为什么重要 |
|---|---|---|---|
| 预训练 | 无(自动学习) | 3000亿token | 学习语言基础 |
| SFT | 提供问答对 | 20万条 | 学会结构化回答 |
| 奖励建模 | 对回答排序 | 10万条排序 | 让AI理解"什么更好" |
| 强化学习 | 无(自动优化) | 5000轮迭代 | 持续提升回答质量 |
💡 关键真相:
奖励建模 = 人类排序 → 奖励模型学习相对偏好 → AI生成更好回答
不是人类给每个回答打分(如"8分")!
📊 三、具体图片说明
![image.png]() -
-
 -
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号