
Convolution_Pointwise_Depthwise
Convolution_Pointwise_Depthwise
用 矩阵乘法 和 数值例子 来拆解普通卷积。
假设输入是一个单通道(如灰度图)的特征图,使用一个 3 x 3 的卷积核 Kernel
1. 普通卷积数学概念
1.1 数学定义
卷积 Convolution 的本质是 互相关 Cross-correlation。给定输入矩阵 \(I\) 和 卷积核 (kernel) \(K\),输出矩阵 \(O\) 在位置 \((i,j)\) 的值的计算公式为:
- \(k\): 卷积核的大小,如 3
- \(\cdot\): 对应位置的点乘
1.2 实际例子:提取垂直边缘
假设我们有一个 4x4 的建议图像,中间有一条明显的边界(左边亮,右边暗)
输入 \(I(4 \times 4)\)

卷积核 \(K(3 \times 3)\) - 经典的 Prewitt 算子(用于检测垂直边缘):
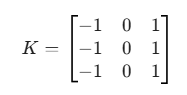
1.3 计算步骤(不考虑 Padding 和 Stride)
卷积核 Kernel 会在输入图像上 “滑动”。因为输入是 4x4,核 是 3x3,所以输出得到 (4 - 3 + 1) x (4-3 + 1) = 2x2
-
第一步:左上角窗口
取 输入 \(I\) 的左上角 3x3 区域:
![image-20260310212242462]()
得到 -30
-
第二步:向右滑动一格
取输入 \(I\) 的右上角 3x3 区域:
![image-20260310212358010]()
得到 -30
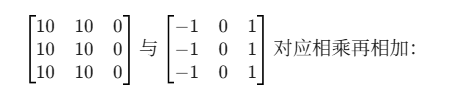
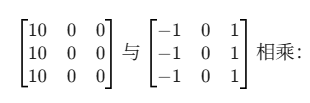
依次类推,计算完所有 4 个位置
最终输出
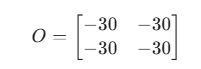
结果分析:输出矩阵中出现了明显的数值(-30),说明卷积核成功捕捉到了图像中的垂直亮度变化(边缘)。
1.4 矩阵视角:把卷积变成“大矩阵乘法”
在深度学习框架(如 PyTorch / TensorFlow)底层,为了加速,通常会使用 im2col 技术将卷积转换为一个巨大的矩阵乘法:\(Y = W \cdot X\)
-
展开输入:
将每个 3 x 3 的滑动窗口拉直成一个行向量(长度 为 9)
-
展开权重
将 3x3 的卷积核拉直成一个列向量(长度为 9)
-
相乘
![image-20260310213102159]()

1.5 总结
summation: 总和
- 普通卷积: 是基于 邻域 的加权和
- 数学意义: 它在寻找输入数据中与卷积核 kernel “长得像” 的模式(模式匹配)
2. 普通卷积的更简单解释
Standard Convolution ,通常是 3x3 或 5x5,就像是一个 “社区观察员”
2.1 核心逻辑:空间感知(Spatial Awareness)
普通卷积最大的特点就是有 视野 Receptive Field
- 同时在 垂直(通道) 和 水平(空间) 两个维度上进行加权求和
2.2 如何工作
解释上面的 H x W x C (Height, Width, Channel 通道)
假设有一个 3x3 的卷积核 Kernel,input 是一个 HxWxC 的特征图:
-
滑动窗口:卷积核像一个 “小滤镜”,在图像的宽度和高度上移动。
-
邻里互动:当它停在某个位置上时,它会覆盖一个 3x3 的区域。他会把这 9 个点里的像素值,与卷积核里的 9 个权重一一对应相乘。
-
跨通道汇总:
关键点!如果输入有 C 个通道,这个 kernel 实际上是一个 厚度为 C 的方块(即 3x3xC)。它会把这 C 个通道里所有对应的 9 x C 个乘积全部加在一起,最后只吐出一个值。
结果:这个值就代表了这块 “小社区” 提取出的某个特定特征(比如一条边缘、一个圆角)。
2.3 代价
| 特性 | 普通卷积 \(K \times K\) |
|---|---|
| 观察范围 | 当前像素 + 周围像素 |
| 主要任务 | 提取空间特征(形状、纹理) |
| 计算量 | 很高(\(H \times W \times C \times N \times K^2\)) |
注:其中 \(K\) 是卷积核大小 (如 3),\(N\) 是输出通道数。你可以看到普通卷积的计算有 \(K^2\) 倍(对于 3x3 来说就是 9 倍)。
3. 普通卷积的多通道解释
当 convolution 面对多个通道 Channel 时,要求每个通道贡献自己的空间特征,还要把这些 feature 强行求和,融为一体。
3.1 单个卷积核的数学公式(多进一出)
假设 input feature map \(\bold X\) 的尺寸是 \(H \times W \times C_{in}\),kernel \(\bold K\) 的尺寸也是 \(k \times k \times C_{in}\)。
注意:普通卷积核的 "厚度" 必须等于输入的通道数
output feature map \(\bold Y\) 在坐标 \((i,j)\) 处的值为:
-
内层两个 \(\sum(m,n)\):
负责在 空间维度 (长宽)上做加权求和,也就是提取每一层的形状特征。
-
最外层的 \(\sum(c)\):
负责在 通道维度 上做加权求和。他把所有通道提取到的结果全部加在一起。
3.2 完整版:多个卷积核(多进多出)
如果你希望输出有 \(C_{out}\) 个通道,你就需要 \(C_{out}\) 个上述那样的 “厚核”。
此时,输出 \(\bold Y\) 的第 \(l\) 个 channel 在 (i, j) 处的值为:
3.3 实际数值例子:2通道合并为 1通道
还是用 R、G 两个通道的例子,看看 standard convolution 是怎么把它们 “揉” 在一起的。
-
Input \(\bold X\) (2 channels)
- Channel 1 (R) : \(\begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}\)
- Channel 2 (G): \(\begin{bmatrix} 2 & 2 \\ 2 & 2 \end{bmatrix}\)
-
Kernel \(\bold K\) (2 x 2 x 2)
- 核的第一层(对 R):\(\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\)
- 核的第一层(对 R):\(\begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix}\)
-
计算过程
- 先计算 R Channel 的卷积:1 + 0 + 0 + 1 = 2
- 先计算 G Channel 的卷积:0 + 2 + 2 + 0 = 4
- 最后全部加起来: 2 + 4 = 6
-
Output
- 单通道值:6
4. Pointwise Convolution 逐点卷积
Pointwise Convolution 可以被看作是 一个通道维度的全连接层.
虽然顶着卷积的名号,但是它在空间 (Width 和 Height) 上完全不发力,它所有的能量都花在了 通道 Channel 的融合和重组 上。
- 核心逻辑:空间维度 (\(H, W\)) 保持不动,只在通道维度 (\(C\)) 做线性组合。
4.1 数学公式定义
假设输入特征图为 \(\bold X\) ,尺寸为 \(H \times W \times C_{in}\)
我们使用 N 个 1x1 的 kernel,每个核的权重为 \(\bold W \in \mathbb R^{1 \times 1 \times C_{in}}\)
对于输出特征图 \(\bold Y\) 在坐标 \((i, j)\) 处的第 k 个通道的值,其公式为:
- 没有空间求和:公式里没有对邻居坐标 (如 i + m, j + n) 的累加
- 通道加权:它仅仅是对当前点 (i, j) 再所有输入通道 c 上的值进行加权求加
- 本质:如果固定坐标 (i, j),这其实就是一个多维向量的点积。
4.2 矩阵视角
如果把每个像素点都看成一个长度为 \(C_{in}\) 的向量,Pointwise Convolution 实际上就是对图上 每一个点 都做了一次完全相同的矩阵乘法:
其中 x 是输入通道向量,W 是权重矩阵(尺寸为 \(N \times C_{in}\))
4.3 实际例子
4.3.1 降维:把颜色变浅
将一个 RGB 图像 (3 通道) 变成 单通道特征图
-
Input
-
\(\bold X\): 在某个像素点 (i, j) 的值:
假设该点为亮紫色,对应通道向量为
\[\bold x = [100, 50, 200] (R = 100, G = 50, B = 200) \]
-
-
Kernel 权重 \(\bold W\): 一个 1x1x3 的 kernel:
- 假设这个核的作用是 提取蓝色分量并稍微融合一点红色:\[\bold W = [0.2, 0, 0.8] \]
- 假设这个核的作用是 提取蓝色分量并稍微融合一点红色:
-
Output:
- \(\bold Y_{i, j}\)\[\begin{aligned} \bold Y_{i, j} & = (100 * 0.2) + (50 * 0) + (200 * 0.8) \\ & = 20 + 0 + 160 \\ & = 180 \end{aligned} \]
- \(\bold Y_{i, j}\)
-
结果分析:
Kernel 在全图上每个点都执行这个操作。最终,得到一张高度和宽度不变,但厚度从 3 变成了 1 的新图。
4.3.2 升维
升维 Expansion 是 Pointwise Convolution 在轻量化网络(如 MobileNetV2 的 Inverted Residual Block)中极具魔力的用法。
-
核心逻辑:
- 通过增加通道数,把低维空间里的特征 “投影” 到高维空间,让特征分布得更开,更容易被获取
-
为什么要 Expansion
- 想象你有一张二维平面上的散点图,有些点重叠在一起,很难用一条直线把它们分开。
- Pointwise Expansion
- 就是给这些点增加了一个 “高度” 维度,把它们拉到了三维空间。原本挤在一起的点,在3D空间里可能离得很远了。
- 数学意义
- 高维空间能容纳更多的非线性特征,避免信息在压缩过程中丢失。
-
实际数值例子:从 2 通道升维到 4 通道
假设有一个 \(1 \times 1\) 的像素点,输入通道为 2(比如只有 R 和 G),要把它 expansion 到 4 channels.
-
Input 特征图 \(\bold X\) (在点 (i, j) 处):
\[\bold x = [10, 20] \] -
Kernel 权重 \(\bold W\):
我们需要 4 个 kernels,每个核的大小是 1x1x2
- 核1(提取红色分量):\([1, 0]\)
- 核2(提取绿色分量):\([0, 1]\)
- 核3(提取平均特征):\([0.5, 0.5]\)
- 核1(提取差异特征):\([1, -1]\)
-
Output \(\bold y\)
- \(y_1 = (10 \times 1) + (20 \times 0) = 10\)
- \(y_2 = (10 \times 0) + (20 \times 1) = 20\)
- \(y_3 = (10 \times 0.5) + (20 \times 0.5) = 15\)
- \(y_4 = (10 \times 1) + (20 \times -1) = -10\)
-
输出结果:
\[\bold y = [10, 20, 15, -10] \] -
分析:
通过这 4 个 “小方块” 的加权组合,把原本只有 2 个数字的信息,变成了一个拥有 4 个数字的向量。虽然原始信息源没变,但是从 不同的角度(分量、平均、差异) 重新解决了这组数据。
-
4.4 在 MobileNet 中的作用
在 MobileNetV2 的 Inverted Residuals (倒残差结构) 中,Pointwise 卷积扮演了 “吹气球” 的角色:
- Expansion 升维:用 1x1 卷积把通道数扩大 6 倍(例如从 32 升到 192)
- Depthwies 提取:在高维空间进行 3x3 卷积提取形状特征
- Projection 降维:再用 1x1 卷积把通道数压回去(例如从 192 降回 32)
- 为什么要先升维 expansion
- 因为在低维空间(通道少时)使用 ReLU 等激活函数会造成严重的 信息损毁。把特征 “吹” 到高维后再处理,能保护特征的完整性。
5. Pointwise Convolution 更浅显解释
5.1 形象理解
想象你有一张 \(100 \times 100\) 像素的图片,每个像素有红、绿、蓝(RGB) 3 个通道。
- 普通卷积(\(3 \times 3\)):像是一个滤镜,它看一个像素时,还会顺便看看周围的 8 个像素,用来捕捉形状、边缘。
- Pointwise 卷积(\(1 \times 1\)):它像是一个极其严谨的调色师。它坐在图片上方,一次只盯着一个像素点看。它把这个点上的红、绿、蓝三种颜色按比例混合,调配成一种(或多种)新颜色,然后移动到下一个像素点重复同样的操作。
关键点:它不关心邻居是谁,它只关心当前这个点里不同通道之间的“化学反应”。
5.2 数学本质:通道加权求和
假设输入的特征图在某个位置的数值是 \([R, G, B]\),你使用了一个 \(1 \times 1\) 的卷积核,其权重是 \([w_1, w_2, w_3]\)。
那么这个点的输出值就是:
这其实就是一个线性组合。如果你有 \(N\) 个这样的卷积核,你就能在这个点上得到 \(N\) 个不同的组合结果。
5.3 作用
5.3.1 变换通道数(Exansion / Projection)
- 降维 (压缩)
- 如果输入有 512 个通道,但计算压力太大,你可以用 64 个 1x1 kernel,把输入变成 64 通道。信息被 “浓缩” 了,计算量减少。
- 升维 (扩张)
- 在 MobileNet 的反残差结构中,先用 1x1 把通道数从 64 扩张到 384,让网络在更高维的空间提取特征。
5.3.2 信息跨通道融合
普通的 Depthwise Convolution (深度可分离卷积的第一步) 是每个通道独立计算的,通道之间 “老死不相往来”。
Pointwise Convolution 就像是一个外交官,负责把这些独立通道的信息收集起来,进行加权融合。
5.3.3 引入非线性
每个 1x1 convolution 背后通常都会跟着一个激活函数(如 ReLU)。这意味着即使你只是改变了通道数,也给网络增加了一层 非线性映射,让网络能学习更复杂的特征,而增加的计算量很小。
5.4 总结
6. Depthwise Convolution 深度卷积
如果说普通 convolution 是 “既看邻居又调色” 的全能战士,那 Depthwise convolution 就是一个极度偏科的专项员:它只看邻居,不调色
6.1 核心逻辑:一个通道配一个 kernel
在普通卷积中,卷积核会同时跨越所有通道。但在 Depthwise convolution 中:
- 输入通道数 = 卷积核个数 = 输出通道数
- 每个 kernel 只负责处理 一个 对应的通道
- 通道之间是 完全独立 的,没有任何信息的交流
6.2 数学公式
假设 input feature map 输入特征图为 \(\bold X\),尺寸为 H x W x C
有 \(C\) 个 kernels \(\bold K\),每个大小为 \(k \times k\)
对于第 c 个通道的 output feature map \(\bold Y_c\),其在位置 (i, j) 的计算公式为:
- 注意下标中的 \(c\) : 输出的第 c 层只由 input 的第 c 层核第 c 个 kernel 决定。
- 和普通卷积(多通道)相比,没有对通道维度 (Channel)的求和符号 \(\sum_c\)
6.3 实际例子
假设有一张 RGB 图片(3通道),要用 3x3 的 Depthwise convolution 来处理它。
- 准备核:需要 3 个 3x3 的 convolution kernels (核 R、核 G、核 B)
- R 通道:核 R 在图片上的红色通道上滑动,计算出输出的 红色层
- G 通道:核 G 在图片上的绿色通道上滑动,计算出输出的 绿色层
- B 通道:核 B 在图片上的蓝色通道上滑动,计算出输出的 蓝色层
- 合并:把这 3 个计算结果叠在一起,得到一个 3 通道的输出
结果分析:虽然每个通道内部的形状特征(边缘、纹理)被提取了,但红色和绿色之间没有任何融合。
以下是实际数值例子
2 channels input, 3x3 convolution kernel
1. 设定场景
假设 input feature map \(\bold X\) 有 2 个通道(比如一张极简图片的 R 和 G 通道),尺寸为 3x3
使用 3x3 的 Depthwise convolution,由于是 Depthwise,必须准备 2 个对应的 3x3 kernel
输入 \(\bold X\) (2 channel)
-
channel 1 (R):
\[\begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{bmatrix} \] -
channel 2 (G):
\[\begin{bmatrix} 2 & 2 & 2 \\ 2 & 2 & 2 \\ 2 & 2 & 2 \end{bmatrix} \]
Convolution Kernel (2 个)
-
kernel 1 (负责 channel 1): 这是要给提取水平边缘的核
\[\begin{bmatrix} 1 & 1 & 1 \\ 0 & 0 & 0 \\ -1 & -1 & -1 \end{bmatrix} \] -
kernel 2 (负责 channel 2): 这是一个简单的全 1 核(平滑)
\[\begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{bmatrix} \]
2. 数学计算过程
在 Depthwise 卷积中,通道之间不发生任何关系
1. 处理 Channel 1
将 Channel 1 与 Kernel 1 进行逐元素相乘并求和:得到 0
- 结果:输出特征图的 第 1 通道点为 0
2. 处理 Channel 2
将 Channel 2 与 Kernel 2 进行逐元素相乘并求和:得到 18
- 结果:输出特征图的 第 2 通道点为 18
3. 最终输出 \(\bold Y\)
-
独立性
channel 1 的 output 完全由 kernel 1 决定,channel 2 的输出完全由 kernel 2 决定
-
无融合
在普通卷积中,会变成 0 + 18,但是在 Depthwise 中,仍然是两个独立的通道
6.4 为什么这样能省参数
参数量 (Weights):
- 普通卷积:如果想得到 2 channel 的 output,需要两个 “厚” kernel(每个 kernel 都是 3x3x2)。
- 参数量:3 x 3 x 2 (input channel) x 2 (output kernel) = 36 个参数
- Depthwise convolution: 只需要两个 “薄” 核(每个 kernel 都是 3x3x1)
- 参数量:3 x 3 x 2 (input channel) = 18 个参数
参数量减半了。在实际的深度网络中(比如 512 通道),减幅会达到几百分之一(比如 256)
6.5 为什么不直接用它
Depthwise convolution 虽然极大地节省了计算量,但是有一个致命缺陷:通道间信息不流通。
如果只用 Depthwise 卷积,网络就无法学习到 “ red + green = yellow” 这种跨通道地特征。
这就是为什么 Depthwise convolution 必须和 Pointwise 组合使用
- Depthwise : 提取每个通道内部地空间特征(省钱、高效)
- Pointwise:融合不同通道之间的特征(打通、互联)
这就是大名鼎鼎的 Depthwise Separable Convolution 深度可分离卷积。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号