

1、实验目的
深入理解支持向量机(SVM)的算法原理,能够使用Python语言实现支持向量机的训
练与测试,并且使用五折交叉验证算法进行模型训练与评估。
2、实验内容
(1)从scikit-learn 库中加载 iris 数据集或本地读取,进行数据分析;
(2)采用五折交叉验证划分训练集和测试集,使用训练集对SMO支持向量机分类算
法进行训练;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和F1值)进行测试;
(4)通过对测试结果进行比较分析,评估模型性能;
实验代码:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
import warnings
import sys
import io
# 设置输出编码为UTF-8,解决Windows PowerShell中文乱码问题
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
warnings.filterwarnings('ignore')
# ============================================================================
# 步骤1:从scikit-learn库中加载iris数据集,进行数据分析
# ============================================================================
print("=" * 80)
print("步骤1:从scikit-learn库中加载iris数据集,进行数据分析")
print("=" * 80)
print()
"""
函数说明:load_iris()
作用:从scikit-learn库中加载经典的鸢尾花(Iris)数据集
返回值:返回一个Bunch对象,包含以下属性:
- data: 特征数据矩阵 (150, 4)
- target: 目标标签数组 (150,)
- feature_names: 特征名称列表
- target_names: 类别名称列表
- DESCR: 数据集描述信息
参数:无参数
"""
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print(f"数据集形状: {X.shape}")
print(f"特征数量: {X.shape[1]}")
print(f"样本数量: {X.shape[0]}")
print(f"类别数量: {len(np.unique(y))}")
print()
print(f"特征名称: {feature_names}")
print(f"类别名称: {target_names}")
print()
print("数据统计信息:")
iris_df = pd.DataFrame(X, columns=feature_names)
iris_df['species'] = [target_names[i] for i in y]
print(iris_df.describe())
print()
print("类别分布:")
for i, name in enumerate(target_names):
count = np.sum(y == i)
print(f" {name}: {count} 个样本 ({count/len(y)*100:.1f}%)")
print()
print("缺失值检查:")
print(f" 缺失值数量: {iris_df.isnull().sum().sum()}")
print()
print("特征相关性分析:")
correlation = iris_df[feature_names].corr()
print(correlation)
print()
# ============================================================================
# 步骤2:采用五折交叉验证划分训练集和测试集,使用训练集对SMO支持向量机分类算法进行训练
# ============================================================================
print("=" * 80)
print("步骤2:采用五折交叉验证划分训练集和测试集,使用训练集对SMO支持向量机分类算法进行训练")
print("=" * 80)
print()
"""StandardScaler(): 特征标准化,SVM 对特征尺度敏感需先缩放。"""
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("数据标准化完成")
print(f" 标准化前 - 均值: {X.mean(axis=0).round(2)}, 标准差: {X.std(axis=0).round(2)}")
print(f" 标准化后 - 均值: {X_scaled.mean(axis=0).round(2)}, 标准差: {X_scaled.std(axis=0).round(2)}")
print()
"""KFold: 五折交叉验证划分训练/测试索引,shuffle=True 保证随机性。"""
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
"""SVC: SVM 分类器(内部使用 SMO 优化),此处采用 RBF 核。"""
print("创建SVM模型(使用SMO算法进行优化)...")
print()
# 存储每折的评估指标
fold_results = {
'fold': [],
'accuracy': [],
'precision': [],
'recall': [],
'f1': []
}
all_y_true = []
all_y_pred = []
print("开始五折交叉验证...")
print("-" * 80)
fold_num = 1
for train_idx, test_idx in kfold.split(X_scaled):
print(f"\n第 {fold_num} 折:")
print(f" 训练集大小: {len(train_idx)} ({len(train_idx)/len(X)*100:.1f}%)")
print(f" 测试集大小: {len(test_idx)} ({len(test_idx)/len(X)*100:.1f}%)")
X_train, X_test = X_scaled[train_idx], X_scaled[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
# 创建SVM模型(使用RBF核,SMO算法自动使用)
# SVC内部使用SMO算法进行优化
svm_model = SVC(
kernel='rbf', # 使用径向基函数(高斯核)
C=1.0, # 正则化参数
gamma='scale', # 核函数系数
probability=False, # 不启用概率估计以加快训练
shrinking=True, # 使用收缩启发式算法
tol=1e-3, # 停止训练的容差
max_iter=-1, # 无最大迭代限制
random_state=42 # 随机种子
)
print(f" 模型参数: kernel={svm_model.kernel}, C={svm_model.C}, gamma={svm_model.gamma}")
# 训练模型(内部使用SMO算法)
svm_model.fit(X_train, y_train)
# 预测
y_pred = svm_model.predict(X_test)
all_y_true.extend(y_test)
all_y_pred.extend(y_pred)
"""accuracy_score: 分类准确度(正确预测占比)。"""
acc = accuracy_score(y_test, y_pred)
"""precision_score: 加权精度(预测为某类的正确率)。"""
prec = precision_score(y_test, y_pred, average='weighted', zero_division=0)
"""recall_score: 加权召回率(实际样本被找回的比例)。"""
rec = recall_score(y_test, y_pred, average='weighted', zero_division=0)
"""f1_score: 加权 F1(精度与召回率的调和平均)。"""
f1 = f1_score(y_test, y_pred, average='weighted', zero_division=0)
fold_results['fold'].append(fold_num)
fold_results['accuracy'].append(acc)
fold_results['precision'].append(prec)
fold_results['recall'].append(rec)
fold_results['f1'].append(f1)
print(f" 准确度 (Accuracy): {acc:.4f}")
print(f" 精度 (Precision): {prec:.4f}")
print(f" 召回率 (Recall): {rec:.4f}")
print(f" F1值 (F1-Score): {f1:.4f}")
fold_num += 1
print("\n" + "=" * 80)
print("五折交叉验证完成!")
print("=" * 80)
print()
# ============================================================================
# 步骤3:使用五折交叉验证对模型性能(准确度、精度、召回率和F1值)进行测试
# ============================================================================
print("=" * 80)
print("步骤3:使用五折交叉验证对模型性能(准确度、精度、召回率和F1值)进行测试")
print("=" * 80)
print()
overall_accuracy = accuracy_score(all_y_true, all_y_pred)
overall_precision = precision_score(all_y_true, all_y_pred, average='weighted', zero_division=0)
overall_recall = recall_score(all_y_true, all_y_pred, average='weighted', zero_division=0)
overall_f1 = f1_score(all_y_true, all_y_pred, average='weighted', zero_division=0)
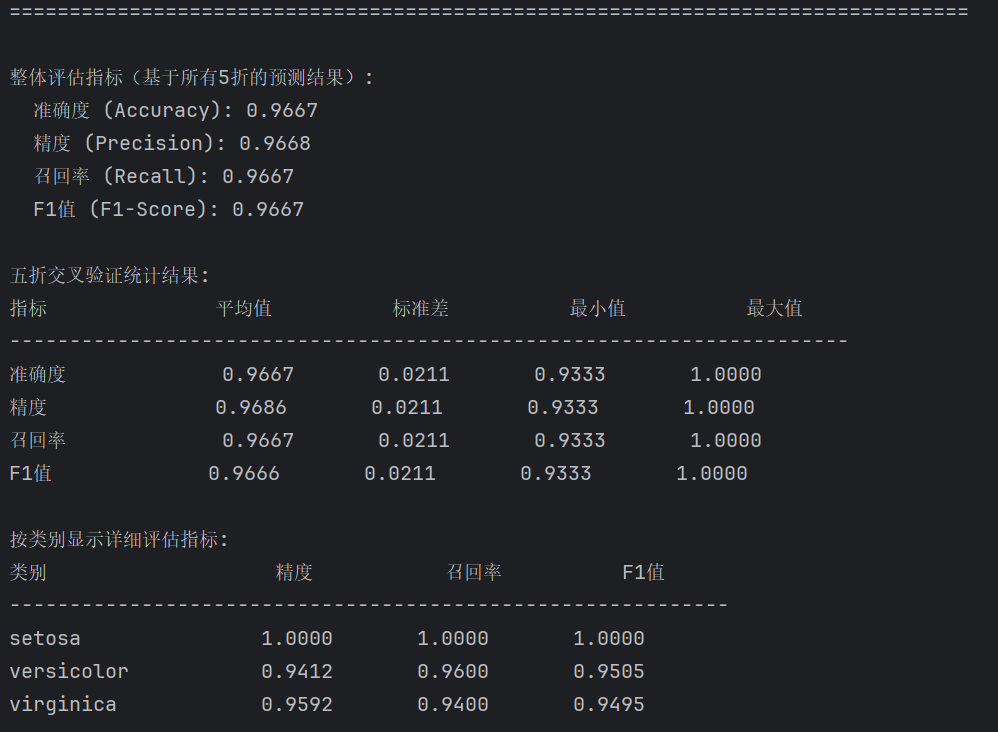
print("整体评估指标(基于所有5折的预测结果):")
print(f" 准确度 (Accuracy): {overall_accuracy:.4f}")
print(f" 精度 (Precision): {overall_precision:.4f}")
print(f" 召回率 (Recall): {overall_recall:.4f}")
print(f" F1值 (F1-Score): {overall_f1:.4f}")
print()
print("五折交叉验证统计结果:")
print(f"{'指标':<15} {'平均值':<12} {'标准差':<12} {'最小值':<12} {'最大值':<12}")
print("-" * 70)
print(f"{'准确度':<15} {np.mean(fold_results['accuracy']):<12.4f} {np.std(fold_results['accuracy']):<12.4f} {np.min(fold_results['accuracy']):<12.4f} {np.max(fold_results['accuracy']):<12.4f}")
print(f"{'精度':<15} {np.mean(fold_results['precision']):<12.4f} {np.std(fold_results['precision']):<12.4f} {np.min(fold_results['precision']):<12.4f} {np.max(fold_results['precision']):<12.4f}")
print(f"{'召回率':<15} {np.mean(fold_results['recall']):<12.4f} {np.std(fold_results['recall']):<12.4f} {np.min(fold_results['recall']):<12.4f} {np.max(fold_results['recall']):<12.4f}")
print(f"{'F1值':<15} {np.mean(fold_results['f1']):<12.4f} {np.std(fold_results['f1']):<12.4f} {np.min(fold_results['f1']):<12.4f} {np.max(fold_results['f1']):<12.4f}")
print()
print("按类别显示详细评估指标:")
precision_per_class = precision_score(all_y_true, all_y_pred, average=None, zero_division=0)
recall_per_class = recall_score(all_y_true, all_y_pred, average=None, zero_division=0)
f1_per_class = f1_score(all_y_true, all_y_pred, average=None, zero_division=0)
print(f"{'类别':<20} {'精度':<12} {'召回率':<12} {'F1值':<12}")
print("-" * 60)
for i, class_name in enumerate(target_names):
print(f"{class_name:<20} {precision_per_class[i]:<12.4f} {recall_per_class[i]:<12.4f} {f1_per_class[i]:<12.4f}")
print()
print("混淆矩阵(Confusion Matrix):")
"""confusion_matrix: 生成混淆矩阵(行真列预测)。"""
cm = confusion_matrix(all_y_true, all_y_pred)
print("\n真实类别(行) vs 预测类别(列):")
print(f"{'':<15}", end="")
for name in target_names:
print(f"{name:<15}", end="")
print()
for i, name in enumerate(target_names):
print(f"{name:<15}", end="")
for j in range(len(target_names)):
print(f"{cm[i, j]:<15}", end="")
print()
print()
print("分类报告(Classification Report):")
"""classification_report: 输出各类别 precision/recall/F1 和支持数。"""
report = classification_report(all_y_true, all_y_pred, target_names=target_names)
print("\n" + report)
print()
# ============================================================================
# 步骤4:通过对测试结果进行比较分析,评估模型性能
# ============================================================================
print("=" * 80)
print("步骤4:通过对测试结果进行比较分析,评估模型性能")
print("=" * 80)
print()
print("模型性能分析")
print("=" * 80)
print()
print("1. 准确度分析:")
print(f" 整体准确度为 {overall_accuracy:.4f},说明模型在测试集上的预测正确率为 {overall_accuracy*100:.2f}%")
print(f" 五折交叉验证的平均准确度为 {np.mean(fold_results['accuracy']):.4f},标准差为 {np.std(fold_results['accuracy']):<12.4f}")
if np.std(fold_results['accuracy']) < 0.05:
print(" 标准差较小,说明模型性能稳定")
else:
print(" 标准差较大,说明模型性能在不同折之间存在一定波动")
print()
print("2. 精度分析:")
print(f" 整体精度为 {overall_precision:.4f},说明模型预测为正类的样本中,实际为正类的比例为 {overall_precision*100:.2f}%")
print()
print("3. 召回率分析:")
print(f" 整体召回率为 {overall_recall:.4f},说明实际为正类的样本中,被正确预测的比例为 {overall_recall*100:.2f}%")
print()
print("4. F1值分析:")
print(f" 整体F1值为 {overall_f1:.4f},综合反映了模型的精度和召回率")
print(f" 由于F1值是精度和召回率的调和平均数,当两者都较高时,F1值也会较高")
print()
print("5. 类别分析:")
for i, class_name in enumerate(target_names):
print(f" {class_name}:")
print(f" 精度: {precision_per_class[i]:.4f}, 召回率: {recall_per_class[i]:<12.4f}, F1值: {f1_per_class[i]:<12.4f}")
print()
print("实验完成!")
实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号