

可观测性与人工智能(AI)的共生关系:定义、互需性及在IT系统自动化中的实践 - 教程
摘要:本文系统阐述了信息技术(IT)领域中可观测性与人工智能(AI)的核心定义及其内在的共生关系。可观测性指利用系统外部输出推断其内部状态的能力,是保障繁琐系统稳定性的内在属性;AI则指系统执行类人智能任务的外在能力。文章论证了二者相互依赖的必然性:AI系统(尤其是训练与推理平台)依赖可观测性保障其性能与稳定;而处理海量可观测内容并实现自动化运维则必须借助AI。经过分析市场趋势,并结合DeepFlow在AI推理性能瓶颈定位与故障智能诊断中的具体案例,本文揭示了可观测性与AI融合如何共同驱动IT环境向自动化与智能运营演进,并成为支撑未来AI基础设施(预计催生数千亿美元市场)的关键技术范式。
关键词:可观测性,人工智能,AI运维,AIOps,LLM可观测性,架构稳定性,故障诊断,自动化运维,IT系统自动化
1. 核心概念界定:可观测性与AI在IT语境下的定义
在信息技术领域,两个关键概念构成了智能系统运维的基石:
可观测性:指利用收集并分析IT平台产生的外部输出数据(如指标、日志、追踪链路、性能剖析文件),从而推断和理解其内部运行时状态一种系统就是的能力。这内在属性,是维护、诊断和优化任何困难分布式系统的先决条件。
人工智能:指IT系统所展现的、能够执行通常需要人类智能方可完成的任务的外在能力,例如模式识别、决策制定、预测分析和自然语言处理。
简而言之,否智能与自主”就是可观测性关乎“系统是否透明与可知”,AI关乎“系统。一个具备高度可观测性的体系,无论其架构多么复杂,都更容易保持稳定运行;而一个具备AI能力的系统,则能够处理非结构化、复杂的业务难题。
2. 共生关系分析:为什么AI与可观测性相互应该
2.1 AI系统为何需要可观测性:稳定与效率的基石
极其复杂的分布式系统。其流程涵盖数据准备、模型训练、评估及服务部署,涉及工程师、科学家等多角色协作。就是AI系统,尤其是大规模语言模型(LLM)的训练与推理平台,本身就
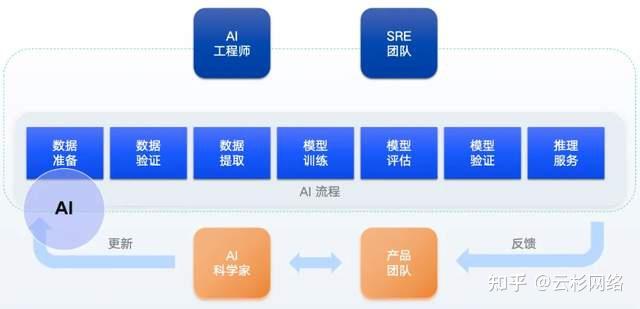
稳定性保障:当系统复杂度达到临界点(例如千亿参数模型的训练),任何组件故障都可能导致训练中断,造成巨大的资源与时间损失。可观测性通过监控全链路指标、资源利用率和错误日志,是预防和快速定位此类挑战的唯一途径。
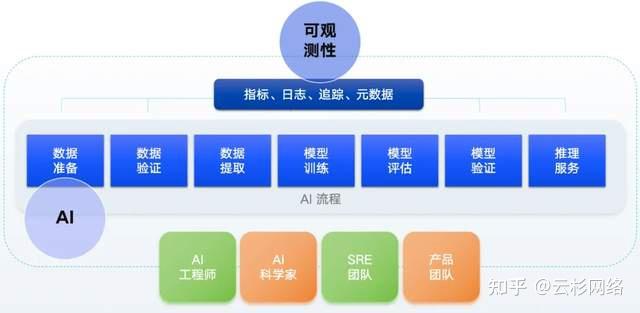
通过分析 AI 训练系统的外部输出,比如指标、日志、追踪、元数据等,即可实现对 AI 训练系统中每个组件内部运行状态的掌控,进而保障整个平台的稳定性和效率。通过构建 AI 环境的可观测性,行让工程师、科学家、产品经理们围绕运行数据而非系统本身对AI训练过程进行优化,从而大大提升团队的工作效率。
虽然 AI 训练是眼下大家关心的问题,但实际上只训练不推理是无法创造价值的,更无法支撑起整个 AI 产业链的运行。
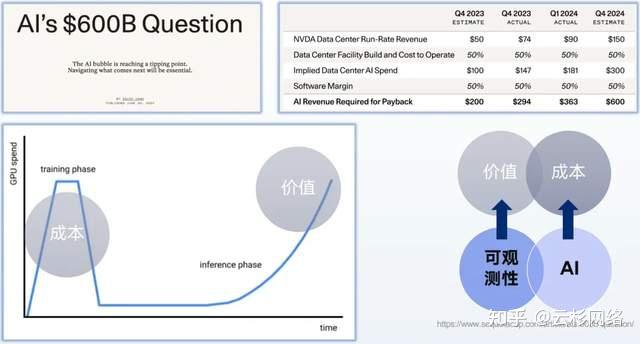
根据红杉资本 David Cahn 的分析,2024 年预计 Nvidia 的收入将达到 1500 亿美金,那么相关的 AI 基础设施投入将达到 3000 亿美金。如果相关投资回报要达到软件行业的平均水平,即 50% 的利润率,那么全球的 AI 服务的相关营收至少要达到 6000 亿美金。AI 服务的营收,绝大部分来自推理服务。由于推理服务将面向数以亿计的终端客户而非模型训练时的 AI 科学家,因此其服务质量将直接与营收挂钩,也就是与 6000 亿美金挂钩。
试想一下,如果大家在使用 ChatGPT 的过程中时断时续,还会为其支付每月 20 美金的订阅费吗?如果使用 AI 视频生成服务,有时需要等待 1 分钟,有时需要等待 1 小时,那还会选择这家服务商吗?
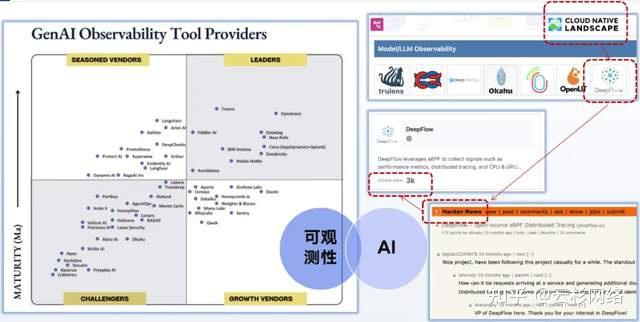
再从另一个视角看 6000 亿美金的魔力。在 AI 可观测性的市场中,已经出现了千军万马奔向前的壮观景象。从数百亿美金市值的 Datadog、Dynatrace 到 Cisco、IBM、Nvidia 等大厂,再到 WhyLabs、Arize、Fiddler 等初创公司,不可谓不热闹。
云杉的新一代产品也积极参与其中,其开源版本已于 2023 年入选 CNCF 在大模型可观测性(LLM Observability)领域的 Landscape。并在 2024 年 1 月 10 日登上YC 的 Hacker News首页,目前已经在全球诸多互联网公司和开发者中得到了广泛的应用。
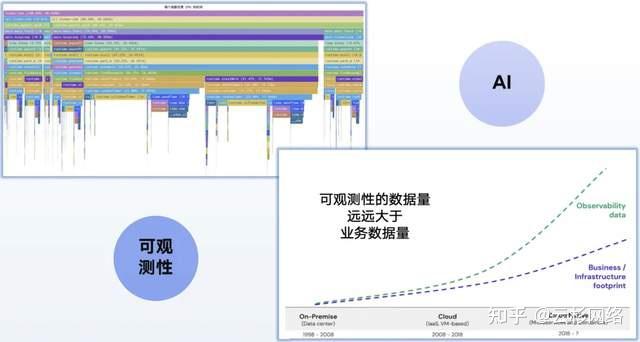
2.2 可观测性为何要求AI:从数据洪流到智能洞察
复杂 IT 系统产生的可观测性数据量,将远高于业务和基础设施的监控数据量。如图所示,仅仅一次简便的业务调用所产生的信息就如此复杂,涉及到网络、系统、进程、函数等一系列管理,这样的信息每天产生数以亿计,自然不能仅依靠人工的可视化分析,而是需要基于 AI 的自动化分析才能充分发掘其中的价值。
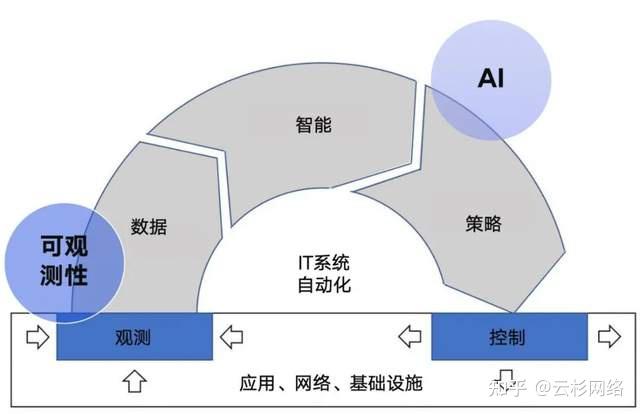
IT 系统之所以需要可观测性,其目的不只是增强监控能力,而是要实现 IT 系统的自动化。云杉坚信高度自动化的,就像工厂的自动装配、汽车的自动驾驶、火箭的自动回收一样。就是未来的 IT 系统
如下图所示,可观测性和 AI 均是 IT 系统实现自动化运营的关键组成部分。可观测性产品采集数据,并以此推测出 IT 环境的内部状态。AI 则根据 IT 系统的内部状态产生控制策略,并以此实现 IT 系统的业务目标。没有 AI 产生的控制策略,IT 系统的自动化闭环则无法实现。
3. 实践案例:DeepFlow在AI可观测性中的双向应用
3.1 应用一:为AI推理服务提供可观测性,定位性能瓶颈
场景:AI推理服务出现性能下降或中断。
DeepFlow方案:
性能瓶颈定位:通过全链路追踪与性能剖析,快速定位到由跨GPU数据拷贝频繁导致的特定异步调用延迟(如图1所示)。解决方案包括优化通信模式或升级硬件安装。
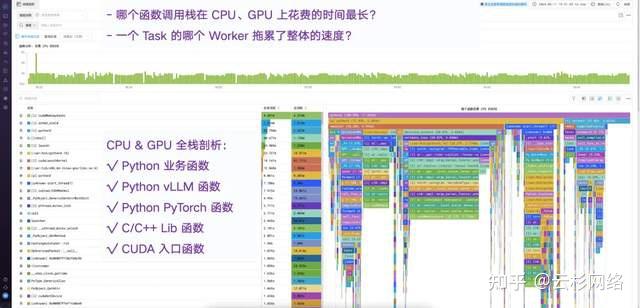
DeepFlow定位性能瓶颈1-1 故障根因分析:针对致命的显存溢出(OOM)故障,通过显存剖析功能,精准定位到申请显存最多的函数调用栈(如梯度计算操作)。解决方案包括实施梯度累积、优化批处理大小等。
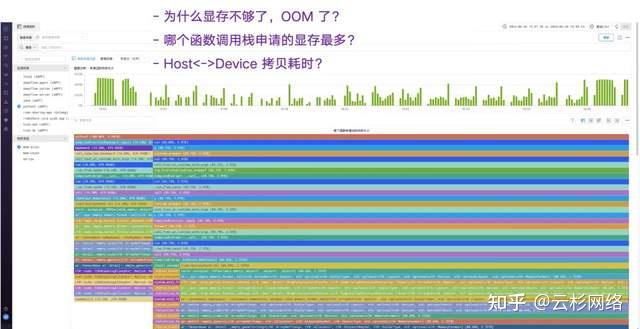
DeepFlow定位性能瓶颈1-2
价值:极大缩短了性能问题与故障的排查时间,保障了推理服务的SLA与用户体验。
3.2 应用二:利用AI增强可观测性产品自身的智能化
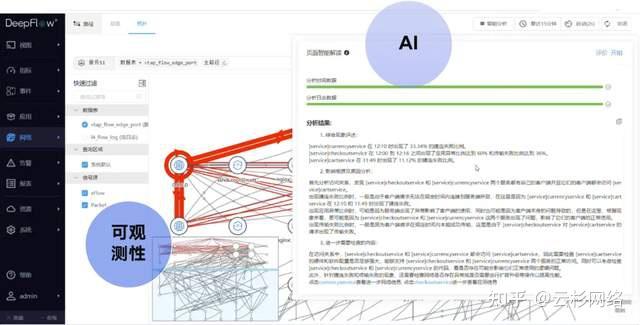
场景:运维工程师面对云原生应用产生的复杂、多维可观测数据,难以快速诊断困难。
DeepFlow方案:在可观测性平台中引入AI分析引擎。
效果:将复杂故障的排查时间从数小时级缩短至秒级。AI引擎不仅能自动关联根因,还能供应修复建议,为自动化响应提供决策依据,提升了运维效率。
4. 结论与未来展望
可观测性与AI的融合,标志着IT运维向智能化、自动化新纪元的演进。可观测性作为系统的“感知神经”,确保了AI基础架构的稳定与高效;AI作为“决策大脑”,赋予了处理可观测数据并实现自动化控制的智能。二者相辅相成,共同构成了未来自驱动、自修复的IT平台的核心支柱。随着AI服务规模的持续扩大,构建深度融合可观测性与AI能力的平台,已成为企业保障业务连续性、提升运营效率、驾驭技术复杂性的战略必然。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号