

归档笔记 - TensorFlow1 从零开始 训练目标检测
2019-8-20
[[OpenCV]]
TensorFlow
相关概念
线性回归 问题
线性回归是利用数理统计中回归分析, 来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
简而言之: 通过统计分析得出一个或者多个自变量和因变量的某种关系.
实例: 一个人受教育年限, 与收入之间的关系, 我们通过受教育年限来预测收入,
F(X) = WX + B; X等于受教育, F(X)等于收入, W跟B就是需要求解的参数
但还要确定W和B的最优解是什么? 需要定义一个损失函数, 使得W和B通过损失函数,越小越好.
损失函数(目标函数)
线性问题 适合均方差(统计学) 作为损失函数,
//以上为例, 机器随机出来W和B参数, 实际样本数据对比得到均方的差, 得到lose值
在反向传播后, 作为评估权重的一个算法
优化器 梯度下降
本例随机输入 W 和 B 经过损失函数, 梯度下降 寻找下降速度最快的方向, 进而调整下次训练的值
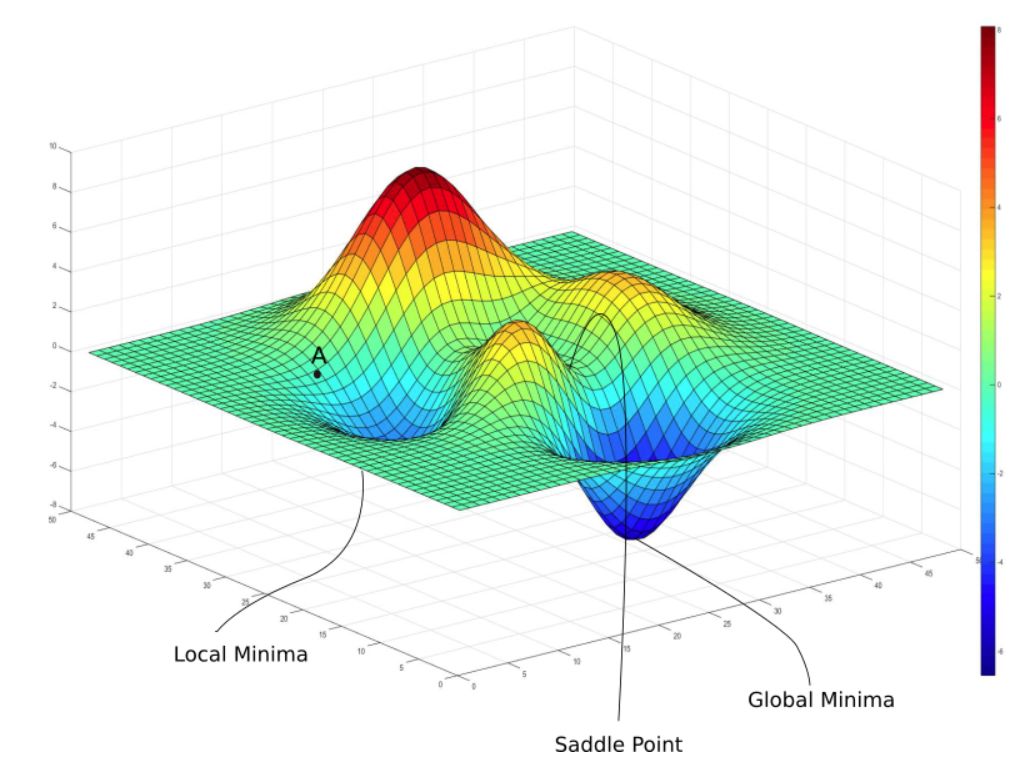
-
局部极值点
局部极值点, 典型特征, 损失值 来回跳 -
下降步骤 检测速率
感知器
你可以这么理解感知器, 它是一个通过加权凭据来进行决策的设备;
一个感知器只有一个输出, 但是可以被下一层的多个感知器使用.
偏移(偏置)
你可以将偏移想象成使感知器如何更容易输出 1, 或者用更加生物学术语, 偏移是指衡量感知器触发的难易程度;
对于一个大的偏移, 感知器更容易输出 1; 如果偏移负值很大, 那么感知器将很难输出 1;
假设我们有一个没有输入的感知器, 那么权重和 ∑jwjxj 将始终为0, 那么如果偏差b>0, 感知器将输出1, 否则输出 0 ;
偏移值越大, 越容易使感知器输出正向反馈 便于某一层加权输出?
神经元
如果权重或者偏移的细小改变能够轻微影响到网络输出, 那么我们会逐步更改权重和偏移来让网络按照我们想要的方式发展;
比如, 假设网络错误的将数字"9"的图像识别为"8", 我们将指出如何在权重和偏移上进行细小的改动来使其更加接近于"9";
并且这个过程将不断重复, 不断地改变权重和偏移来产生更好的输出; 于是这个网络将具有学习特性;
但是有个问题:
任何一个感知器的权重或者偏移细小的改变有时都能使得感知器输出彻底翻转,
这种翻转可能导致网络剩余部分的行为以某种复杂的方式完全改变;
因此当"9"可能被正确分类后, 对于其他图片, 神经网络行为结果将以一种很难控制的方式被完全改变;
sigmoid神经元
我们能通过引入一种新的人工神经元(sigmoid神经元)来克服这个问题;
它和感知器类似, 但是细微调整它的权重和偏移只会很细小地影响到输出结果; 类似一个平滑的感知器 [图表1 sigmoid function]
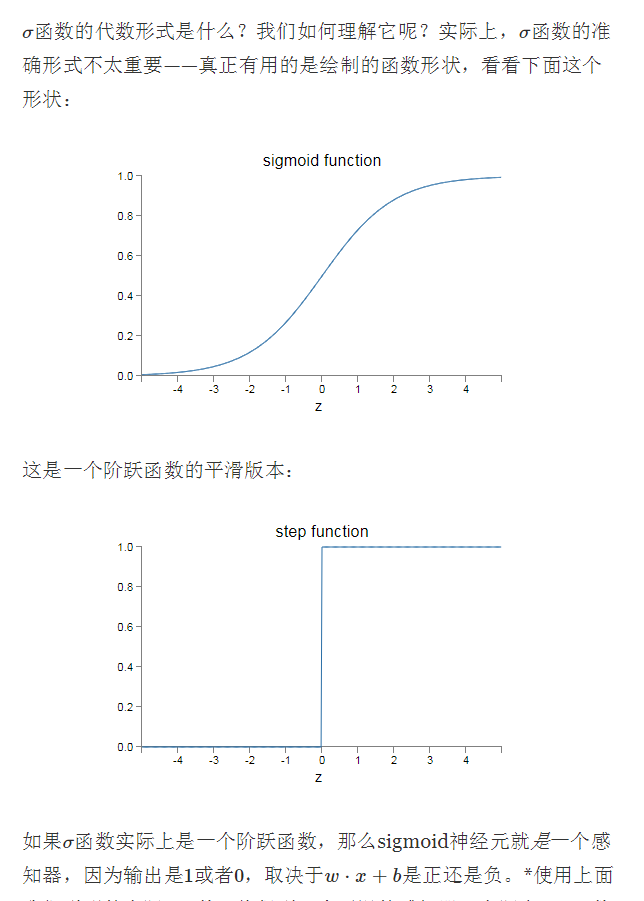
如果把sigmoid神经元的实现函数,变成一个阶跃函数, 那么sigmoid神经元就是一个感知器, 因为输出是1或者0, 取决于w⋅x+b是正还是负; [图表2 step function]
多层感知器
除了输入和输出层,还有一层或多层为隐含层
中间层被称为隐含层, 因为里面的神经元既不是输入也不是输出; "隐含"这个术语可能听起来很神秘——当我第一次听到时候觉得一定有深层的哲学或者数学意义——但实际上它只表示"不是输入和输出"而已;
多层神经元可输出拟合问题(异或运算)
神经元可以依据条件是否激活传递(激活函数)
前向反馈神经网络
我们已经讨论了某一层的输出当作下一层的输入的神经网络; 这样的网络被称为前向反馈神经网络;
这意味着在网络中没有循环——信息总是向前反馈, 决不向后;
递归神经网络
但是, 人工神经网络也有一些具有循环反馈; 这样的模型被称为递归神经网络; 这样的模型思想是让神经元在不活跃之前激励一段有限的时间;
这种激励能刺激其它神经元, 使其也能之后激励一小会; 这就导致了更多神经元产生激励, 等过了一段时间, 我们将得到神经元的级联反应;
在这样的模型中循环也不会有太大问题, 因为一个神经元的输出过一会才影响它的输入, 而不是瞬间马上影响到;
递归神经网络没有前馈神经网络具有影响力, 因为递归网络的学习算法威力不大(至少到目前); 但是递归网络仍然很有趣, 它们比起前馈网络更加接近于我们人脑的工作方式;
激活函数
激活函数(activation function)运行时激活神经网络中某一部分神经元, 将激活神经元的信息输入到下一层神经网络中; 神经网络之所以能处理非线性问题, 这归功于激活函数的非线性表达能力; 激活函数需要满足数据的输入和输出都是可微的, 因为在进行反向传播的时候, 需要对激活函数求导;
逻辑回归 问题
对于二元分类, 输出'是'与'否'的问题
损失函数 建议(二元交叉熵)'binary_crossentropy'
- 交叉熵 放大概率, 适合概率分布
激活函数 建议'sigmoid'
softmax 层
对于多元分类, 经过softmax 层, 输出总量为 1
适合输出指定范围内概率的分布
使用One-hot的直接原因是现在多分类cnn网络的输出通常是softmax层,而它的输出是一个概率分布,从而要求输入的标签也以概率分布的形式出现。 即只在对应的特征处值为1,其余地方值为0
过拟合 & 欠拟合
避免网络容量增大, 过拟合
优先增加层,提高准确率
过拟合典型特征:
在测试数据中 损失值上升, 准确率下降, 得分低; 而在训练数据中 得分高;
反过来就是欠拟合. (在测试数据中, loss值低, 准确率高, 在训练数据中 得分低)
抑制过拟合
添加一个 dropout层,抑制过拟合;
原理: 随机丢掉一些隐含的单元
最好的方式是增加训练数据
第二好的方式是减少(神经元)网络容量?
原则
先开发大网络容量, 过拟合 模型
再用最好的方式 抑制过拟合
卷积神经网络
"卷积神经网络"表示在网络采用称为卷积的数学运算; 卷积是一种特殊的线性操作; 卷积网络是一种特殊的神经网络, 它们在至少一个层中使用卷积代替一般矩阵乘法
wiki - 卷积神经网络
卷积层
参考: https://blog.csdn.net/weixin_41417982/article/details/81412076?spm=1001.2014.3001.5501
卷积层是一组平行的特征图(feature map), 它通过在输入图像上滑动不同的卷积核并运行一定的运算而组成; 此外, 在每一个滑动的位置上, 卷积核与输入图像之间会运行一个元素对应乘积并求和的运算以将感受野内的信息投影到特征图中的一个元素; 这一滑动的过程可称为步幅 Z_s, 步幅 Z_s 是控制输出特征图尺寸的一个因素; 卷积核的尺寸要比输入图像小得多, 且重叠或平行地作用于输入图像中, 一张特征图中的所有元素都是通过一个卷积核计算得出的, 也即一张特征图共享了相同的权重和偏置项;
谈一下卷积层的工作原理;
卷积核
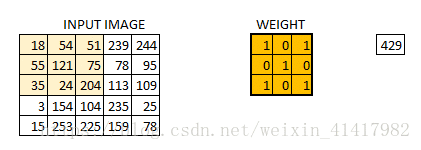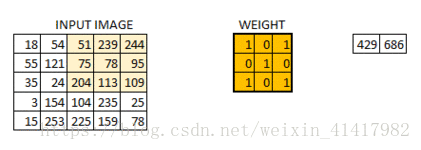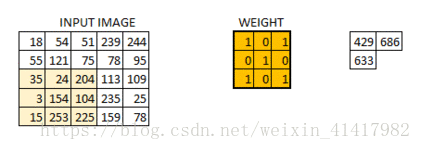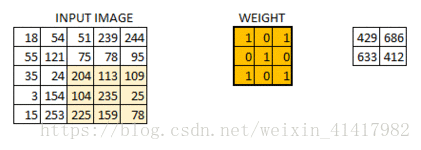
我们是使用卷积核来提取特征的, 卷积核可以说是一个矩阵; 假如我们设置一个卷积核为33的矩阵, 而我们图片为一个分辨率55的图片
; 那么卷积核的任务就如下所示:
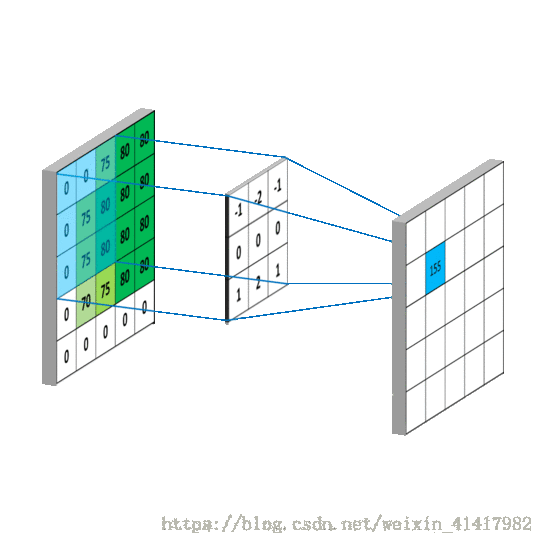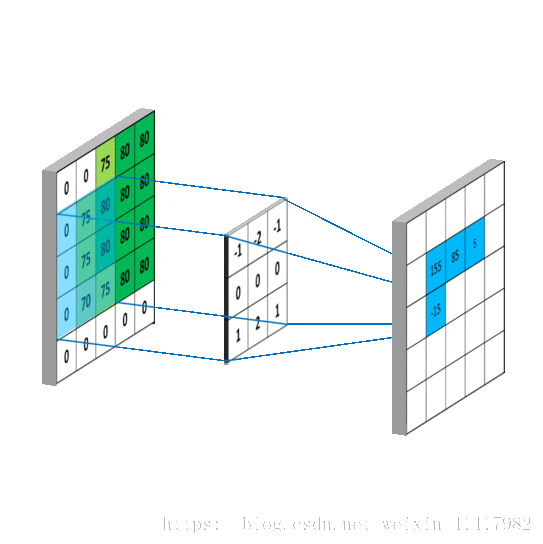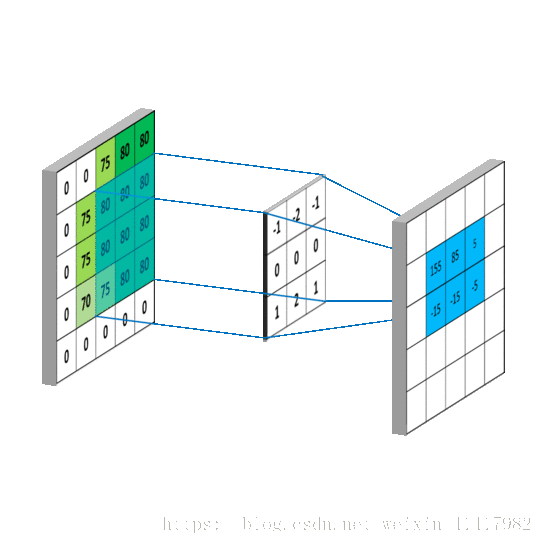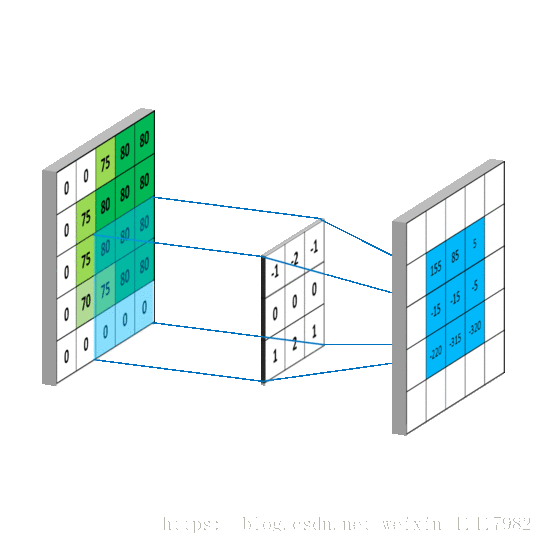
从左上角开始, 卷积核就对应着数据的3*3的矩阵范围, 然后相乘再相加得出一个值;
按照这种顺序, 每隔一个像素就操作一次, 我们就可以得出9个值;这九个值形成的矩阵被我们称作激活映射(Activation map); 这就是我们的卷积层工作原理;
但其实我们输入的图像一般为三维, 即含有R, G, B三个通道; 但其实经过一个卷积核之后, 三维会变成一维; 它在一整个屏幕滑动的时候, 其实会把三个通道的值都累加起来, 最终只是输出一个一维矩阵; 而多个卷积核(一个卷积层的卷积核数目是自己确定的)滑动之后形成的Activation Map堆叠起来, 再经过一个激活函数就是一个卷积层的输出了;
步长和padding
- 步长
卷积层还有另外两个很重要的参数:步长和padding;
所谓的步长就是控制卷积核移动的距离; 在上面的例子看到, 卷积核都是隔着一个像素进行映射的, 那么我们也可以让它隔着两个, 三个, 而这个距离被我们称作步长;
- padding
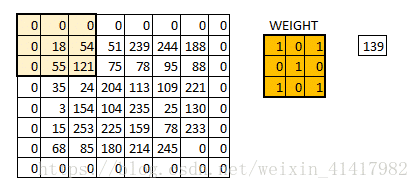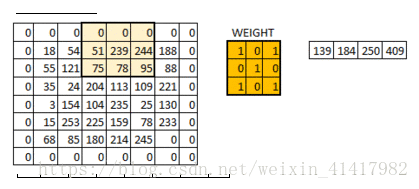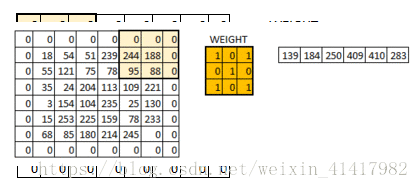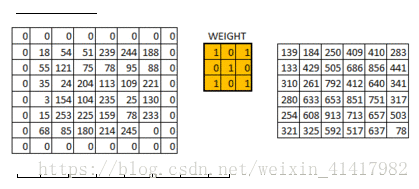
padding就是我们对数据做的操作; 一般有两种,一种是不进行操作,
一种是补0使得卷积后的激活映射尺寸不变; 上面我们可以看到553的数据被33的卷积核卷积后的映射图, 形状为33, 即形状与一开始的数据不同;
有时候为了规避这个变化, 我们使用"补0"的方法——即在数据的外层补上0;
用一个矩阵卷积核(类似一个过滤矩阵), 矩阵遍历图像, 能够把图像缩小,输出的每一个像素都有卷积核范围内的特征
步长就是控制卷积核移动的距离, 最好是卷积核大小/2,这样就能完美遍历整个图片了
padding是在输入的图片外层补0,可以使得卷积后的激活映射尺寸不变
实际问题: 数据乱码
选择一个激活函数, 把一些不适合的,或者不规则的值, 转为简单可以计算的值
实际问题: 数据量过大
如果纯原始数据输入RGB三通道+加2k图+多卷积全图遍历, 数据量会非常大.
池化层 (pooling layer)
前面说到池化层是降低参数, 而降低参数的方法当然也只有删除参数了;
一般我们有最大池化和平均池化, 而最大池化就我认识来说是相对多的; 需要注意的是, 池化层一般放在卷积层后面; 所以池化层池化的是卷积层的输出!
至于为什么选择最大池化, 应该是为了提取最明显的特征, 所以选用的最大池化;
平均池化呢, 就是顾及每一个像素, 所以选择将所有的像素值都相加然后再平均;
![左最大值池化,右平均值池化]](_v_images/20180804142645882.png)
池化层也有padding的选项; 但都是跟卷积层一样的, 在外围补0, 然后再池化;
in short 将图片按照固定大小网格分割, 网格内的像素值取网格内所有像素的平均值(平均值池化)或最大值(最大值池化), 或...; 将这种把图片使用均等大小网格分割, 并求网格内代表值的操作称为池化(Pooling)
全连接层(full-connected layer)
全连接层(full-connected layer), 顾名思义, 是将前面层的节点全部连接然后通过自己之后传入下一层;
超参数
事先设置 卷积核, 步长, 池化层... 这些参数
数据流图(Dataflow Graph)
1.节点(nodes) 表示计算单元, 也可以是输入的起点或者输出的终点
2.线(edges)表示节点之间的输入/输出关系
在 TensorFlow 中, 每个节点都是用 tf.Tensor的实例来表示的, 即每个节点的输入, 输出都是Tensor,
如官页图中 Tensor 在Graph(图)中的流动, 形象的展示 TensorFlow 名字的由来;
TensorFlow 中的数据流图有以下几个优点:
- 可并行 计算节点之间有明确的线进行连接(依赖), 系统可以很容易的判断出哪些计算操作可以并行执行
- 可分发 图中的各个节点可以分布在不同的计算单元(CPU, GPU, TPU等)或者不同的机器中, 每个节点产生的数据可以通过明确的线发送的下一个节点中
- 可优化 TensorFlow 中的 XLA 编译器可以根据数据流图进行代码优化, 加快运行速度
- 可移植 数据流图的信息可以不依赖代码进行保存, 如使用Python创建的图, 经过保存后可以在C++或Java中使用
Graph
tensorflow 使用Graph 来表示一个计算任务
在Tensorflow中, 始终存在一个默认的Graph; 如果要将Operation添加到默认Graph中,
只需要调用定义Operation的函数(例如tf.add());
API中tf.Graph类表示可计算的图;图是由操作Operation(例加减乘除,实际操作更复杂) 和 张量Tensor(多维数据)来构成,
其中Operation表示图的节点(即计算单元), 而Tensor则表示图的边(即Operation之间流动的数据单元)
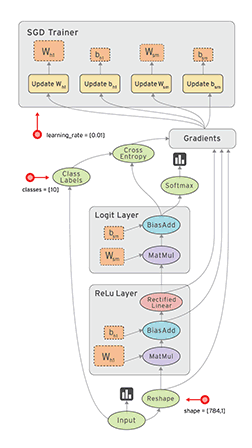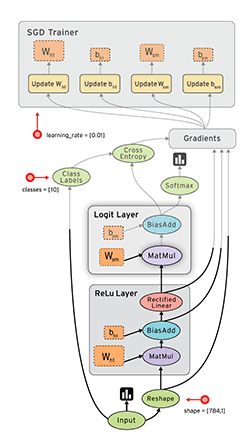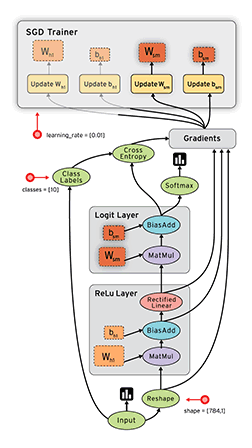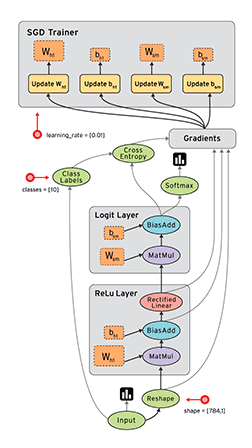
Operation
一个Operation就是Tensorflow Graph中的一个计算节点;
其接收零个或者多个Tensor对象作为输入, 然后产生零个或者多个Tensor对象作为输出;
Tensor
Tensor 多维数据
模型
以上概念都是都是用来定义运行流程的, 并没有数据,只有在运行的时候,才有具体的数值
Tensorflow 的张量
TensorFlow 使用 张量 (Tensor)作为数据的基本单位; TensorFlow 的张量在概念上等同于多维数组, 我们可以使用它来描述数学中的标量(0 维数组), 向量(1 维数组), 矩阵(2 维数组)
简而言之, 就是一个多维数组
张量的重要属性是其形状, 类型和值; 可以通过张量的 shape , dtype 属性和 numpy() 方法获得;
- 张量是用来表示多维数据
- 张量是执行操作时的输入或输出数据
- 用户通过一个操作来创建或计算张量
- 张量的形状(维度长度)必须是确定的, 但不一定在编译时确定, 可以在运行时确定.
特殊张量
有几类特殊的张量, 以下操作产生
tf.constant //常量 , 不可改变的
tf.placeholder // 占位符, 类似一个占位的壳子, 可以规定部分形状;
变量 (tf.Variable)
变量 它是常驻于内存中, 可保存每一轮结束后的张量, 在下一轮可以直接使用; 以节省内存开销
安装搭配环境
Anaconda (Python)
Anaconda是一个方便的python包管理和环境管理软件, 一般用来配置不同的项目环境;
我们常常会遇到这样的情况, 正在做的项目A和项目B分别基于python2和python3, 而第电脑只能安装一个环境,
这个时候Anaconda就派上了用场, 它可以创建多个互不干扰的环境, 分别运行不同版本的软件包, 以达到兼容的目的;
官页下载 - https://www.anaconda.com/download/success
安装选项, 第一个 添加系统变量, 第二个是注册默认的python版本 为默认的(base)环境
如果没有添加环境变量:
添加对应PATH 环境变量: (以自己的安装路径为准)
\Anaconda3
\Anaconda3\Scripts
\Anaconda3\Library\bin
刚刚系统默认创建了名叫base的默认环境, 我们可以使用conda命令查看当前有多少环境
conda env list 查看所有环境 或者 conda info --envs
anaconda在目录下的envs文件夹保存了环境配置, 也就是把所有的安装在这个环境下的包放在同一个文件夹中
当创建一个新环境时, anaconda将在envs中创建一个新的文件夹, 这个文件夹包括了你安装在这个环境中的所有包
envs_dirs
可以通过编辑 ~/.condarc 文件中添加或修改 envs_dirs 来更改默认的环境位置
**envs 文件夹保存了: **
- Conda 环境: 每个环境都是一个独立的目录,其中包含了特定版本的 Python 解释器、相关的库、包和依赖项。每个环境都是独立的,可以有不同的 Python 版本和包集合,这允许用户为不同的项目或需求创建隔离的环境。
- 环境的元数据: 每个环境目录下都有一个名为
conda-meta的子目录,其中包含了该环境的元数据,如环境的创建时间、安装的包列表、版本信息、依赖关系等。 - 二进制文件和脚本: 环境中安装的包可能会包含可执行文件、脚本或链接,这些通常位于环境的
bin目录(在 Linux 和 macOS 上)或Scripts目录(在 Windows 上)。
常用命令
环境管理
- 创建新环境:
conda create --name myenv python=3.8
conda create --name opencv
- 激活环境:
conda activate myenv
conda activate opencv
- 退出环境:
conda deactivate
- 列出所有环境:
conda env list
# 查看当前环境
conda info
- 删除环境:
conda env remove --name myenv
- 克隆环境:
conda create --name myclone --clone myenv
每个 conda 环境都会有一个独立的目录来存放该环境特有的依赖包。这些环境目录通常位于:
- Windows:
C:\Users\用户名\Anaconda3\envs\环境名\lib\site-packages - macOS/Linux:
/home/用户名/anaconda3/envs/环境名/lib/pythonX.X/site-packages(这里的X.X代表Python的版本号)
包管理
- 安装包:
conda install numpy
conda install packagename 为当前环境安装某包
conda install -n envname packagename 为某环境安装某包
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple 指定源安装
conda search packagename 搜索某包
- 更新包:
conda update numpy
conda updata packagename 更新当前环境某包
conda update -n envname packagename 更新某特定环境某包
- 卸载包:
conda remove numpy
conda remove packagename 删除当前环境某包
conda remove -n envname packagename 删除某环境环境某包
- 列出环境中安装的包:
conda list
conda list 列举当前环境下的所有包
conda list -n packagename 列举某个特定名称包
- 搜索包:
conda search scipy
配置管理
- 查看配置:
conda config --show
- 添加通道:
conda config --add channels conda-forge
- 移除通道:
conda config --remove channels conda-forge
- 设置默认通道优先级:
conda config --set channel_priority strict
修改默认源
## 清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
## 中科大
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
conda config --set show_channel_urls yes // 在包后面显示来源
Anaconda 的python解释器
使用pip 安装的模块, 仅针对 Anaconda 的python解释器,
其他解释器可使用代码, 添加模块路径
import sys #导入sys模块
sys.path.append(r'/tmp/test') #要用绝对路径
print(sys.path) #查看模块路径
如何找到conda 切换后的解释器
- 在anaconda prompt中activate解释器所在的环境
conda activate env_name - 查找路径
where python
在 vscode 选择python 的解释器
打开命令面板(Ctrl+Shift+P)输入Python: Select Interpreter 然后选择一个解释器;
配置集成 Jupyter & pip
它默认集成了jupyter 和pip 等
Jupyter Notebooks
Jupyter Notebooks 是一款开源的网络应用, 我们可以将其用于创建和共享代码与文档;
其提供了一个环境, 你无需离开这个环境, 就可以在其中编写你的代码, 运行代码, 查看输出, 可视化数据并查看结果; 因此, 这是一款可执行端到端的数据科学工作流程的便捷工具, 其中包括数据清理, 统计建模, 构建和训练机器学习模型, 可视化数据等等;
jupyter 修改路径
- 生成配置文件
jupyter notebook --generate-config
生成位置: C:\Users\[USER NAME]\.jupyter\jupyter_notebook_config.py
打开[jupyter_notebook_config.py],找到 c.NotebookApp.notebook_dir
取消注释, c前面的#要去掉, 设置路径
c.NotebookApp.notebook_dir = 'F:\\NoteBook'
cmd, 输入jupyter notebook, 你就发现你的路径已更改
jupyter 修改为chorme浏览器
找到App.browser = '', 在这行下面添加以下三行代码
import webbrowser
webbrowser.register("chrome",None,webbrowser.GenericBrowser(u"C:\\ProgramFiles (x86)\\Google\\Chrome\\Application\\chrome.exe"))
c.NotebookApp.browser = 'chrome'
jupyter 启动
jupyter notebook
一个带token的连接, 用浏览器打开
安装 CUDA
CUDA(Compute Unified Device Architecture), 是显卡厂商NVIDIA推出的运算平台;
CUDA™是一种由NVIDIA推出的通用并行计算架构, 该架构使GPU能够解决复杂的计算问题;
tensorflow gpu 版 需要的依赖
- 如果电脑上本身就有Visual Studio Integration, 要将这个取消安装, 避免冲突了
- 如果本地显卡驱动高于CUDA自带的驱动版本, 那一定要把这个勾去掉; 否则会安装失败
点开Driver comonents, Display Driver这一行, 前面显示的是Cuda本身包含的驱动版本是411.31 - 下本地版...网络版..wok
官页下载
https://developer.nvidia.com/cuda-zone
安装 CUDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库; 它强调性能, 易用性和低内存开销;
NVIDIA cuDNN可以集成到更高级别的机器学习框架中, 如谷歌的Tensorflow, 加州大学伯克利分校的流行caffe软件;
简单的插入式设计可以让开发人员专注于设计和实现神经网络模型, 而不是简单调整性能, 同时还可以在GPU上实现高性能现代并行计算;
tensorflow gpu版 需要的依赖
要CUDA版本一致 Download cuDNN v7.6.1 (June 24, 2019), for CUDA 10.0
官页下载列表 MMP现在必须注册
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
作为cuda的补充, 安装简单多了, 只需要把下载后的压缩文件解压缩,
分别将cuda/include, cuda/lib, cuda/bin三个目录中的内容拷贝到
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v[版本号]对应的include, lib, bin目录下即可;
添加环境path变量
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\libnvvp
命令行测试
nvcc -V
tensorflow
TensorFlow 2.1 正式发布后不分GPU版
但是pip 要>19.0
TensorFlow 2 packages require a pip version >19.0.
pip install tensorflow-cpu -i https://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install tensorflow -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
错误 ssl 版本问题(去掉https)
There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skipping
--trusted-host pypi.douban.com
GPU 版
pip install tensorflow-gpu==2.0.0-beta0
wait... wait...
HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read time 报错, 又是 xxx 防火墙!
- 使用豆瓣源
pip install -i https://pypi.douban.com/simple/ tensorflow-gpu==2.0.0-beta0
清华源: https://pypi.tuna.tsinghua.edu.cn/simple
豆瓣源: https://pypi.douban.com/simple/
阿里: https://mirrors.aliyun.com/pypi/simple/
https://pypi.hustunique.com/simple/ 华中理工大学
https://pypi.sdutlinux.org/simple/ 山东理工大学
https://pypi.mirrors.ustc.edu.cn/simple/ 中国科学技术大学
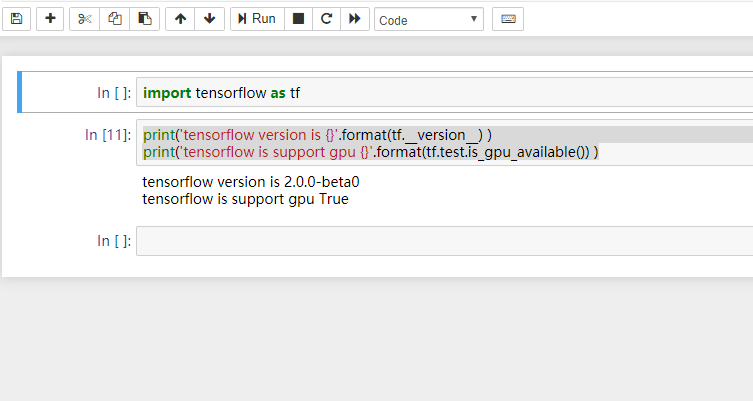
- 测试
启动 jupyter notebook, 新建一个
import tensorflow as tf
print('tensorflow version is {}'.format(tf.__version__) )
print('tensorflow is support gpu {}'.format(tf.test.is_gpu_available()) )
显示True, 说明gpu版本已经安装成功
错误
import tensorflow as tf 语句错误 ImportError: DLL load failed:
下载 Microsoft Visual C++. 安装之
(https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads)
- 升级到最新GPU版本 未测
pip install --upgrade tensorflow-gpu
参考: https://blog.csdn.net/red_stone1/article/details/101303807
简单粗暴 TensorFlow
导数
导数(Derivative), 也叫导函数值; 又名微商, 是微积分中的重要基础概念;
当函数y=f(x)的自变量x在一点x0上产生一个增量Δx时, 函数输出值的增量Δy与自变量增量Δx的比值****在Δx趋于0时的极限 a 如果存在,
a 即为在x0处的导数, 记作f'(x0)或df(x0)/dx;
不是所有的函数都有导数, 一个函数也不一定在所有的点上都有导数; 若某函数在某一点导数存在, 则称其在这一点可导, 否则称为不可导; 然而, 可导的函数一定连续; 不连续的函数一定不可导;
Δ它可百以表示变化量, 屈光度, 一元二次方程中的判别式; Δ, 是西里尔字母的Д和拉丁字母的D都是从 Delta 变来; Delta亦是三角洲的英文, 源自三角洲的形状像三角形, 如同大写度的delta;
一个简单的 线性回归 问题
考虑一个实际问题, 某城市在 2013 年 - 2017 年的房价如下表所示:
年份 |
2013 |
2014 |
2015 |
2016 |
2017 |
房价 |
12000 |
14000 |
15000 |
16500 |
17500 |
现在, 我们希望通过对该数据进行线性回归, 即使用线性模型 y = ax + b 来拟合上述数据, 此处 a 和 b 是待求的参数;
y = 房价
x = 年份
简而言之 希望通过年份来预测房价, 定义一个线性函数 房价 = a * 年份 + b, 在这个简单的模型中, 如何确定a和b的最优解是什么? 隐藏需要定义一个损失函数, 使得a和b通过损失函数,得到的值与测试数据相比,越小越好.
首先, 我们定义数据, 进行基本的归一化操作;
import numpy as np
X_raw = np.array([2013, 2014, 2015, 2016, 2017], dtype=np.float32)
y_raw = np.array([12000, 14000, 15000, 16500, 17500], dtype=np.float32)
X = (X_raw - X_raw.min()) / (X_raw.max() - X_raw.min())
y = (y_raw - y_raw.min()) / (y_raw.max() - y_raw.min())
print(X)
print(y)
TODO
安装 目标检测API(object detection api)
object detection (tf 2.0 没有现成的)
-
创建个 tf1x 环境
conda create -n tf1x python=3.7.3
conda env list -
切换
activate tf1_14
//退出时记得退出命令deactivate
每次命令行都要切换
tf 2.0 没有现成的, 所以装回1.14的...
- 安装
pip install tensorflow-gpu==1.14
pip install -i https://pypi.douban.com/simple/ tensorflow-gpu==1.14
安装这个依赖失败, 单独安装 grpcio
pip install -i https://pypi.douban.com/simple/ grpcio>=1.8.6
在jupyter 使用tf1_14
安装交互环境(ipykernel) conda install ipykernel
加载到 ipykernel python -m ipykernel install --name tf1_14 --display-name "Python tensorflow1.14"
jupyter notebook
kermel 切换..
下载 object detection
解压,例
D:\ProgramData\tensorflow_model\object_detection
安装 protoc (用于编译模块)
一个命令行工具...
编译 ./protoc object_detection/protos/*.proto --python_out=.
如果在protos文件夹下各proto文件没有生成对应的py文件, 就将*.proto换成文件夹下具体的文件名,
一个一个运行, 每运行一个, 对应会生成一个py文件, 亲测有效;
还要下载slim..
放在同级目录下
D:\ProgramData\tensorflow_model\slim
Anaconda 添加环境 slim
\Anaconda\Lib\site-packages 这个文件夹目录下, 写一个.pth文件内容:
D:\ProgramData\tensorflow_model
D:\ProgramData\tensorflow_model\slim
build 安装
cd 进入 D:\ProgramData\tensorflow_model
python object_detection/builders/model_builder_test.py
报错: ModuleNotFoundError: No module named 'matplotlib' ..
安装之 pip install -i https://pypi.douban.com/simple/ matplotlib
报错:ModuleNotFoundError: No module named 'PIL'
安装之 pip install -i https://pypi.douban.com/simple/ Pillow
YES
[ RUN ] ModelBuilderTest.test_session
[ SKIPPED ] ModelBuilderTest.test_session
[ RUN ] ModelBuilderTest.test_unknown_faster_rcnn_feature_extractor
[ OK ] ModelBuilderTest.test_unknown_faster_rcnn_feature_extractor
[ RUN ] ModelBuilderTest.test_unknown_meta_architecture
[ OK ] ModelBuilderTest.test_unknown_meta_architecture
[ RUN ] ModelBuilderTest.test_unknown_ssd_feature_extractor
[ OK ] ModelBuilderTest.test_unknown_ssd_feature_extractor
----------------------------------------------------------------------
Ran 16 tests in 0.112s
OK (skipped=1)
(tf1_14) D:\ProgramData\tensorflow_model>
实例 目标检测
概览
TensorFlow 2 Object Detection API tutorial
官方概览
理论算法概要
理论算法概要
数据准备
图片打标软件 labelImg
labelImg 发布页
./data/predefined_classes.txt 文件, 定义分类标签
将打标的xml转为csv,最终csv格式, 一个目标一行数据.
filename,width,height,class,xmin,ymin,xmax,ymax
0_1568872921.jpg,704,576,Aerator open,285,276,375,319
0_1568872921.jpg,704,576,Aerator open,570,225,616,251
0_1568872921.jpg,704,576,Aerator open,359,192,399,209
0_1568872921.jpg,704,576,Aerator open,338,174,364,184
0_1568873047.jpg,704,576,Aerator open,285,276,375,319
0_1568873047.jpg,704,576,Aerator open,570,225,616,251
0_1568873047.jpg,704,576,Aerator open,359,192,399,209
....
再通过generate_tfrecord.py脚本,转为tfrecord单文件数据.
Usage:
## From tensorflow/models/
## Create train data:
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
## Create test data:
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
tfrecord 生成代码, ## TO-DO replace this with label map 要改下自己的标签映射
预训练模型
简而言之: 预定义模型就是一个定义好各连接层的'模型', 可以把我们自定义数据填充进去训练即可
Object Detection 官方提供了很多预训练模型
例如: ssd_inception_v2_coco_2018_01_28.tar.gz
下载解压至./object_detection/pretrained, 可能没有这个目录(pretrained)需要新建
选择模型
表格模型指标说明:
Speed: 识别速度?
COCO mAP: mAP(mean Average Presion),在多个类别的检测中,每一个类别都可以调整阈值,算出召回率从0到1时的准确率(同一召回率取最高的准确率),计算准确率的平均值,而后再对于所有类求平均得到 mAP。越大越好。
Outputs: 表示输出数据类型; boxes(盒子坐标);Keypoints(关键点); Masks 多边形坐标?
RCNN模型简介
TODO
mscoco_label_map 标签映射
随便从.\object_detection\data 复制个.pbtxt文件,修改下命名mscoco_label_map.pbtxt
item {
id: 1
name: 'Aerator open'
}
item {
id: 2
name: 'Aerator off'
}
配置
模型配置文件 pipeline.config
可参考官方文档 但是也没多少说明..
The train_config defines parts of the training process 定义部分训练参数..
model {
(... Add model config here...)
}
train_config: {
(... Add train_config here...)
}
train_input_reader: {
(... Add train_input configuration here...)
}
eval_config: {
}
eval_input_reader: {
(... Add eval_input configuration here...)
}
需要修改的几个地方
## copy of ssd_inception_v2
model {
faster_rcnn {
num_classes: 2 #训练集中物体类别数
...
gradient_clipping_by_norm: 10.0
fine_tune_checkpoint: "F:/tensorflow/train_dir/tfdata/model.ckpt" ## 没有可删, 实测
from_detection_checkpoint: true
num_steps: 1000 ## 训练总步数
}
train_input_reader {
label_map_path: "F:/tensorflow/train_dir/tfdata/mscoco_label_map.pbtxt" ## 训练数据, 标签
tf_record_input_reader {
input_path: "F:/tensorflow/train_dir/tfdata/train.recordd" ## 训练数据
}
}
eval_config {
num_examples: 31 ## 验证集图片数
max_evals: 10
use_moving_averages: false
}
eval_input_reader {
label_map_path: "F:/tensorflow/train_dir/tfdata/mscoco_label_map.pbtxt"## 测试数据, 标签
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "F:/tensorflow/train_dir/tfdata/eval.recordd"## 测试数据, 标签
}
}
训练开始
activate tf1_14
cd D:\ProgramData\tensorflow_model\object_detection
//run model_main.py --logtostderr \
--model_dir=F:/tensorflow/train_dir/tfdata/ssd_iv2_data \ ## 训练的数据和日志保存的位置
--pipeline_config_path=F:/tensorflow/train_dir/tfdata/config/ssd_inception_v2.config #该网络的配置文件
## ssd_inception_v2
python model_main.py --logtostderr --model_dir=F:/tensorflow/train_dir/tfdata/ssd_iv2_data --pipeline_config_path=F:/tensorflow/train_dir/tfdata/config/ssd_inception_v2.config
## faster_rcnn_inception_resnet_v2_atrous_pets
python model_main.py --logtostderr --model_dir=F:/tensorflow/train_dir/tfdata/train_data --pipeline_config_path=F:/tensorflow/train_dir/tfdata/config/faster_rcnn_inception_resnet_v2_atrous_pets.config
各种坑
-
error: No modul named pycocotools错误: 需要安装 pycocotools, 参考 安装 pycocotools -
ValueError: SSD Inception V2 feature extractorSSD Inception V2模型错误: 要在配置文件 feature_extractor 配置块添加override_base_feature_extractor_hyperparams: true
feature_extractor {
...
override_base_feature_extractor_hyperparams: true
}
faster_rcnn_inception_resnet_v2_atrous_pets ## 在 faster_rcnn_inception_resnet_v2 模型 错误: 要删除
schedule {
step: 0
learning_rate: 0.000300000014249
}
-
fine_tune_checkpoint: "F:/tensorflow/train_dir/tfdata/model.ckpt"## 没有需删掉 -
Resource exhausted: OOM when allocating tensor with shape..内存不足
在配置
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 600
max_dimension: 1024
}
}
这个部分表示将输入图像进行等比例缩放再进行训练, 缩放后的最大边长为1024, 最小边长为600.
可以将整两个数值改小(比如改成512和300), 使用的显存就会变小; 不过这样做也可能导致模型的精度下降
安装 pycocotools
原作者不支持win平台
需要手动编译, 修改支持win版
win版
需要各种库
visualcppbuildtools_full
下载解压后
cd 进去执行
### Anaconda 多环境, 注意切换 activate tf1_14 ##
## cd D:\ProgramData\cocoapi-master\PythonAPI
## python setup.py build_ext --inplace
## python setup.py build_ext install
找不到cl.exe的问题
开始菜单, 找到VS2015 x86 x64 Cross Tools Command Prompt并执行, 即可解决cl.exe找不到的问题;
参考 https://chuna2.787528.xyz/miclita/p/10127871.html
显存不够
tensorflow 默认优先使用gpu内存, 可以通过设置gpu内存的使用分配比例;
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.4)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
如上, 如果gpu内存是10G的话, 那么gpu内存最大会使用4G;
当tensorflow需要调用超过4G的内存计算时, 则调用电脑内存;
https://segmentfault.com/q/1010000010016880
监控训练情况
打开anaconda prompt终端
执行
tensorboard --logdir=F:\tensorflow\train_dir\tfdata\train_data --host=127.0.0.1
logdir = 训练的数据和日志保存的位置
会得到一个类似的url
TensorBoard 1.14.0 at http://127.0.0.1:6006/ (Press CTRL+C to quit)
tensorboard --logdir=F:\tensorflow\train_dir\tfdata\ssd_iv2_data --host=127.0.0.1
导出训练模型
模型文件说明
.meta – 保存图结构, 即神经网络的网络结构
.data – 保存数据文件, 即网络的权值, 偏置, 操作等等
.index – 是一个不可变得字符串表, 每一个键都是张量的名称, 它的值是一个序列化的BundleEntryProto;
activate tf1_14
jupyter notebook
TensorFlow Object Detection API提供了一个export_inference_graph.py脚本用于导出训练好的模型;
cd D:\ProgramData\tensorflow_model\object_detection
python export_inference_graph.py --input_type image_tensor --pipeline_config_path F:/tensorflow/train_dir/tfdata/config/ssd_inception_v2.config --trained_checkpoint_prefix F:/tensorflow/train_dir/tfdata/ssd_iv2_data/model.ckpt-22530 --output_directory F:/tensorflow/train_dir/tfdata/export_ssd_iv2
模型调用(tf1.0)
#frozen_inference_graph.pb文件就是后面需要导入的文件, 它保存了网络的结构和数据
PATH_TO_FROZEN_GRAPH = 'F:/tensorflow/train_dir/tfdata/export/frozen_inference_graph.pb'
# mscoco_label_map.pbtxt文件中保存了index到类别名的映射, 该文件就在object_dection/data文件夹下
PATH_TO_LABELS = 'F:/tensorflow/train_dir/tfdata/mscoco_label_map.pbtxt'
#新建一个图
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
#这个函数也是一个方便使用的帮助函数, 功能是将图片转换为Numpy数组的形式
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
#检测
# PATH_TO_TEST_IMAGES_DIR = 'F:/tensorflow/train_dir/test'
testlist = get_dir_jpt_filename('F:/tensorflow/train_dir/data')
testlist = testlist[0:1]
TEST_IMAGE_PATHS = testlist
# 输出图像的大小(单位是in)
IMAGE_SIZE = (12, 8)
with tf.Session(graph=detection_graph) as sess:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
#将图片转换为numpy格式
image_np = load_image_into_numpy_array(image)
#将图片扩展一维, 最后进入神经网络的图片格式应该是[1,?,?,3], 括号内参数分别为一个batch传入的数量, 宽, 高, 通道数
image_np_expanded = np.expand_dims(image_np,axis = 0)
#获取模型中的tensor
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
#boxes变量存放了所有检测框
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
#score表示每个检测结果的confidence
scores = detection_graph.get_tensor_by_name('detection_scores:0')
#classes表示每个框对应的类别
classes = detection_graph.get_tensor_by_name('detection_classes:0')
#num_detections表示检测框的个数
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# sess 实际检测
boxes,scores,classes,num_detections = sess.run([boxes,scores,classes,num_detections],
feed_dict={image_tensor:image_np_expanded})
##
# np.set_printoptions(precision=3, suppress=True)
# print('阀值confidence {}',scores)
# print('框对应的类别 {}'.format(classes))
# print('检测框的个数 {}'.format(num_detections))
##
#可视化结果
#squeeze函数: 从数组的形状中删除单维度条目, 即把shape中为1的维度去掉
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
参考:
https://blog.csdn.net/qq_38593211/article/details/82823255
https://blog.csdn.net/qq_24946843/article/details/88181686
调用模型(opencv)
[[OpenCV]]
安装 pip install opencv-python
常见的tensorflow训练好的模型保存方式有两种: ckpt格式和pb格式, 其中前者主要用于暂存我们训练的临时数据, 避免发生意外导致训练终止, 前面的努力全部白费掉了; 而后者常用于将模型固化, 提供离线预测, 用户只要提供一个输入, 通过模型就可以得到一个预测结果;
Tensorflow模型的graph结构可以保存为.pb文件或者.pbtxt文件, 或者.meta文件, 其中只有.pbtxt文件是可读的;
在OpenCV中, 每个模型.pb文件, 原则上应有一个对应的文本图形定义的.pbtxt文件, 当然也可能没有,这个.pbtxt是可以通过.pb文件生成的...
.pd 生成 .pbtxt
OpenCV DNN 模块调用 TensorFlow 训练的目标检测模型时, 需要一个额外的配置文件, 其主要是基于与 protocol buffers(protobuf) 格式序列化图(graph) 相同的文本格式版本(.pbtxt文件)
在opencv官方DNN 目录, 有常用目标检测模型转换脚本
三种不同对应 TensorFlow 目标检测模型转换脚本为:
tf_text_graph_ssd.py
tf_text_graph_faster_rcnn.py
tf_text_graph_mask_rcnn.py
转换脚本的输入参数:
[1] - --input: TensorFlow frozen graph 文件路径.
[2] - --config: TensorFlow 模型训练时的 *.config 文件路径. (pipeline.config)
前提需要安装:
pip install -i https://pypi.douban.com/simple/ opencv-python
把dnn目录下过来,cd到目录
D:\opencv410\sources\samples\dnn
执行:
python tf_text_graph_ssd.py --input F:/test/tf/ssd_iv2/frozen_inference_graph.pb --config F:/test/tf/ssd_iv2/ssd_inception_v2_coco.config --output F:/test/tf/ssd_iv2/ssd_inception_v2_coco_2018_01_28.pbtxt
//自定义
python tf_text_graph_ssd.py --input F:/tensorflow/train_dir/tfdata/export_ssd_iv2/frozen_inference_graph.pb --config F:/tensorflow/train_dir/tfdata/ssd_iv2_data/pipeline.config --output F:/test/ssd_inception_v2_my.pbtxt
TF2.0
错误:
....
assert(graph_def.node[0].op == 'Placeholder')
转换一下模型
import tensorflow as tf
## 转换 模型 解决用与opencv 生成 .pbtxt文件的 tf_text_graph_ssd 脚本 错误 assert(graph_def.node[0].op == 'Placeholder')
from tensorflow.tools.graph_transforms import TransformGraph
PATH_TO_FROZEN_GRAPH = 'F:/tensorflow/train_dir/tfdata/export_ssd_iv2/frozen_inference_graph.pb'
PATH_TO_OUT_GRAPH = 'F:/tensorflow/train_dir/tfdata/export_ssd_iv2/sorted_inference_graph.pb'
with tf.gfile.FastGFile(PATH_TO_FROZEN_GRAPH, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
graph_def = TransformGraph(graph_def, ['image_tensor'], ['detection_boxes', 'detection_classes', 'detection_scores', 'num_detections'], ['sort_by_execution_order'])
with tf.gfile.FastGFile(PATH_TO_OUT_GRAPH, 'wb') as f:
f.write(graph_def.SerializeToString())
//自定义 使用转换后的模型ok
python tf_text_graph_ssd.py --input F:/tensorflow/train_dir/tfdata/export_ssd_iv2/sorted_inference_graph.pb --config F:/tensorflow/train_dir/tfdata/ssd_iv2_data/pipeline.config --output F:/test/ssd_inception_v2_my.pbtxt
Python opencv版
#!/usr/bin/python
#!--*-- coding:utf-8 --*--
import cv2 as cv
## MY
## pb_file = "F:/test/tf/myssdiv2/frozen_inference_graph.pb" ## SIZE_CC = 200
## pbtxt_file = "F:/test/tf/myssdiv2/ssd_inception_v2_my.pbtxt"
## pb_file = "F:/test/tf/ssd_iv2/frozen_inference_graph.pb" ## SIZE_CC = 300
## pbtxt_file = "F:/test/tf/ssd_iv2/ssd_inception_v2_coco_2018_01_28.pbtxt"
C_SIZE = 200
cvNet = cv.dnn.readNetFromTensorflow(pb_file, pbtxt_file)
img = cv.imread( "F:/test/tf/0_1568872921.jpg")
rows = img.shape[0]
cols = img.shape[1]
cvNet.setInput(cv.dnn.blobFromImage(img, size=(C_SIZE, C_SIZE), swapRB=True, crop=False))
cvOut = cvNet.forward()
i=0
for detection in cvOut[0,0,:,:]:
tag = float(detection[1])# 这个是分类标签值
score = float(detection[2])
print("{} score {}".format(i,score) )
i+=1
if score > 0.3:
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (23, 230, 210), thickness=2)
cv.imshow('img', img)
cv.waitKey()
[再来一份视频版]
# 准备模型
pb_file = "F:/test/tf/ssd_iv2/frozen_inference_graph.pb"
pbtxt_file = "F:/test/tf/ssd_iv2/ssd_inception_v2_coco_2018_01_28.pbtxt"
C_SIZE = 300
cvNet = cv.dnn.readNetFromTensorflow(pb_file, pbtxt_file)
# 摄像头
cap=cv.VideoCapture(0)
# 流
rtsp = "rtsp://admin:[email protected]:1014/h264/ch0/sub/av_stream"
cap=cv.VideoCapture(rtsp)
while(cap.isOpened()):
ret, img = cap.read()
rows = img.shape[0]
cols = img.shape[1]
imput_ = cv.dnn.blobFromImage(img, size=(C_SIZE, C_SIZE), swapRB=True, crop=False)
cvNet.setInput(imput_)
cvOut = cvNet.forward()
for detection in cvOut[0,0,:,:]:
tag = float(detection[1])# 这个是分类标签值
score = float(detection[2])
# print("{} score {}".format(i,score) )
if score > 0.3:
# print("{} score {}".format(i,score) )
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (23, 230, 210), thickness=2)
cv.imshow('show', img)
k=cv.waitKey(1)
cap.release()
cv.destoryAllWindows()
C++ 版
文件 识别超过2000ms, 且不准确, 完全官方试试!
e.. 在opencv的源码里面, 有示例.\sources\samples\dnn\object_detection.cpp 还有个头文件: #include "common.hpp" 写成一个命令行工具, 且可以读取所有支持的模型, 一堆参数....
补充
最后原因是 cv::dnn::blobFromImage(frame, 1.0, Size(300, 300), Scalar(), true,false); 这个函数, 第二个参数是 1.0 , 需设置正常 Scalar(), true,false 参数, 结果是对了, 仍然识别慢...
Mat frame = cv::imread("F:/test/0_1568872921.jpg");
if ( frame.empty ()){
std::cout << "Error open image file" << std::endl;
return -1;
}
//off
// String weights = "F:/tensorflow/ssd_inception_v2_coco_2018_01_28/frozen_inference_graph.pb";
// String prototxt = "F:/tensorflow/ssd_inception_v2_coco_2018_01_28/ssd_inception_v2_coco_2018_01_28.pbtxt";
//my size = 200
String weights = "F:/tensorflow/train_dir/tfdata/export_ssd_iv2/frozen_inference_graph.pb";
String prototxt = "F:/tensorflow/train_dir/tfdata/export_ssd_iv2/sorted_inference_graph.pbtxt";
qint64 before = QDateTime::currentMSecsSinceEpoch();
dnn::Net net = cv::dnn::readNetFromTensorflow(weights, prototxt);
cv::Mat blob = cv::dnn::blobFromImage(frame, 1.0, Size(200, 200), Scalar(), true,false);
//cout << "blob size: " << blob.size << endl;
net.setInput(blob);
Mat output = net.forward();
//cout << "output size: " << output.size << endl;
Mat detectionMat(output.size[2], output.size[3], CV_32F, output.ptr<float>());
qint64 diff = (QDateTime::currentMSecsSinceEpoch()) - before;
std::cout <<"detect idff="<<diff <<"ms"<< std::endl;
//
Size frame_size = frame.size();
Size cropSize;
if (frame_size.width / (float)frame_size.height > WHRatio) {
cropSize = Size(static_cast<int>(frame_size.height * WHRatio),
frame_size.height);
} else {
cropSize = Size(frame_size.width,
static_cast<int>(frame_size.width / WHRatio));
}
Rect crop(Point((frame_size.width - cropSize.width) / 2,
(frame_size.height - cropSize.height) / 2),
cropSize);
frame = frame(crop);
float confidenceThreshold = 0.20;
////把框画出来
for (int i = 0; i < detectionMat.rows; i++){
float confidence = detectionMat.at<float>(i, 2);
if (confidence > confidenceThreshold){
size_t objectClass = (size_t)(detectionMat.at<float>(i, 1));
int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
ostringstream ss;
ss << confidence;
String conf(ss.str());
Rect object((int)xLeftBottom, (int)yLeftBottom,
(int)(xRightTop - xLeftBottom),
(int)(yRightTop - yLeftBottom));
rectangle(frame, object, Scalar(0, 255, 0), 2);
String label = String(classNames[objectClass]) + ": " + conf;
int baseLine = 0;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
rectangle(frame, Rect(Point(xLeftBottom, yLeftBottom - labelSize.height),
Size(labelSize.width, labelSize.height + baseLine)),
Scalar(0, 255, 0), 0);
putText(frame, label, Point(xLeftBottom, yLeftBottom),
FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));//标签
}
}
imshow("image", frame);
waitKey(0);
return 0;
目前问题: c++版 识别还是超3000ms, 而Py版只有500ms
读取摄像头实时识别 项目文件
-
博客
C++调用tensorflow训练好的SSD物体检测模型https://blog.csdn.net/qq_29462849/article/details/85262609
Opencv调用深度学习模型
Use existing config file for your model
参考->TensorFlow 目标检测模型转换为 DNN 可调用格式 -
资料仓库
tf训练模型
opencv_extra
问题
Error: Assertion failed (inputs.size() == requiredOutputs) in getMemoryShapes
参考: https://stackoverflow.com/questions/48287551/ opencv-dnn-assertion-failed-in-getmemoryshapes
cv::Mat blob = cv::dnn::blobFromImage(frame, 1.0F, Size(200, 200)); 这里的大小, 要跟训练时的大小一至!!!***
-
terminate called after throwing an instance of 'std::bad_alloc' -
error: (-215:Assertion failed) int(numPriors * _numClasses) == total(inputs[1], 1) in function 'cv::dnn::DetectionOutputLayerImpl::getMemoryShapes
分类标签不一致
模型配置 py入口研究 model_main.py
入口代码文件 model_main.py
...
FLAGS = flags.FLAGS
def main(unused_argv):
flags.mark_flag_as_required('model_dir')
flags.mark_flag_as_required('pipeline_config_path')
config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir)
## 关键函数, 应用`pipeline_config_path`配置文件,源文件在 object_detection/model_lib.py
train_and_eval_dict = model_lib.create_estimator_and_inputs(
run_config=config,
hparams=model_hparams.create_hparams(FLAGS.hparams_overrides),
pipeline_config_path=FLAGS.pipeline_config_path,
train_steps=FLAGS.num_train_steps,
sample_1_of_n_eval_examples=FLAGS.sample_1_of_n_eval_examples,
sample_1_of_n_eval_on_train_examples=(
FLAGS.sample_1_of_n_eval_on_train_examples))
estimator = train_and_eval_dict['estimator']
train_input_fn = train_and_eval_dict['train_input_fn']
eval_input_fns = train_and_eval_dict['eval_input_fns']
eval_on_train_input_fn = train_and_eval_dict['eval_on_train_input_fn']
predict_input_fn = train_and_eval_dict['predict_input_fn']
train_steps = train_and_eval_dict['train_steps']
if FLAGS.checkpoint_dir:
if FLAGS.eval_training_data:
name = 'training_data'
input_fn = eval_on_train_input_fn
else:
name = 'validation_data'
## The first eval input will be evaluated.
input_fn = eval_input_fns[0]
if FLAGS.run_once:
estimator.evaluate(input_fn,
steps=None,
checkpoint_path=tf.train.latest_checkpoint(
FLAGS.checkpoint_dir))
else:
model_lib.continuous_eval(estimator, FLAGS.checkpoint_dir, input_fn,
train_steps, name)
else:
train_spec, eval_specs = model_lib.create_train_and_eval_specs(
train_input_fn,
eval_input_fns,
eval_on_train_input_fn,
predict_input_fn,
train_steps,
eval_on_train_data=False)
## 使用 tf.estimator.train_and_evaluate 启动训练和验证过程, 参数有三个:
## estimator 是一个 tf.estimator.Estimator 对象, 用于指定模型函数以及其它相关参数;
## train_spec 是一个 tf.estimator.TrainSpec 对象, 用于指定训练的输入函数以及其它参数;
## eval_spec 是一个 tf.estimator.EvalSpec 对象, 用于指定验证的输入函数以及其它参数;
## Currently only a single Eval Spec is allowed.
tf.estimator.train_and_evaluate(estimator, train_spec, eval_specs[0])
if __name__ == '__main__':
tf.app.run() ## 如果作为命令行启动, 则运行启动tf session
tf.Estimator
Tensorflow 封装高级API之一
Estimator 类, 用来训练和验证 TensorFlow 模型;
Estimator 对象包含了一个模型 model_fn, 这个模型给定输入和参数, 会返回训练, 验证或者预测等所需要的操作节点;
所有的输出(检查点, 事件文件等)会写入到 model_dir, 或者其子文件夹中; 如果 model_dir 为空, 则默认为临时目录;
config 参数为 tf.estimator.RunConfig 对象, 包含了执行环境的信息; 如果没有传递 config, 则它会被 Estimator 实例化, 使用的是默认配置;
params 包含了超参数; Estimator 只传递超参数, 不会检查超参数, 因此 params 的结构完全取决于开发者;
但官方建议使用2.0的 Keras API
tf.keras
博客
手写CNN 牛逼!
win10 python 命令弹商店?
在cmd下或powershell下运行python, 均弹出应用商店
查看path发现第一条为"%USERPROFILE%\AppData\Local\Microsoft\WindowsApps", 这个应该就是罪魁祸首了, 直接删掉
附录文档
TensorFlow Core r1.14 api文档
tensorflow2.0 api文档
极客学院 翻译官方文档
简单粗暴 tensorflow2.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号