

计算范式重构:为什么你过去的开发经验,正在变成时代的负资产?
最近打开任何技术社区,满屏都是焦虑:
“程序员要失业吗?”
“AI 是不是泡沫?”
“我是不是该转行卖炒粉?”
请允许我直言一句:
别再问这些傻问题了。
这些问题之所以“傻”,不是因为提问的人不聪明,而是因为——
他们试图用旧周期的逻辑,理解一个全新的技术物种。
我们眼前发生的,不是 4G→5G、Java17→Java21 这种“局部升级”,
而是 计算范式本身正在重写。
它的量级相当于:
-
大型机 → PC
-
离线 → 互联网
-
手工规则 → 机器学习
如果你还用“就业市场”“KPI指标准则”这种表层视角去看这个周期,
你一定会读错方向。
让我们从底层开始,回到第一性原理。
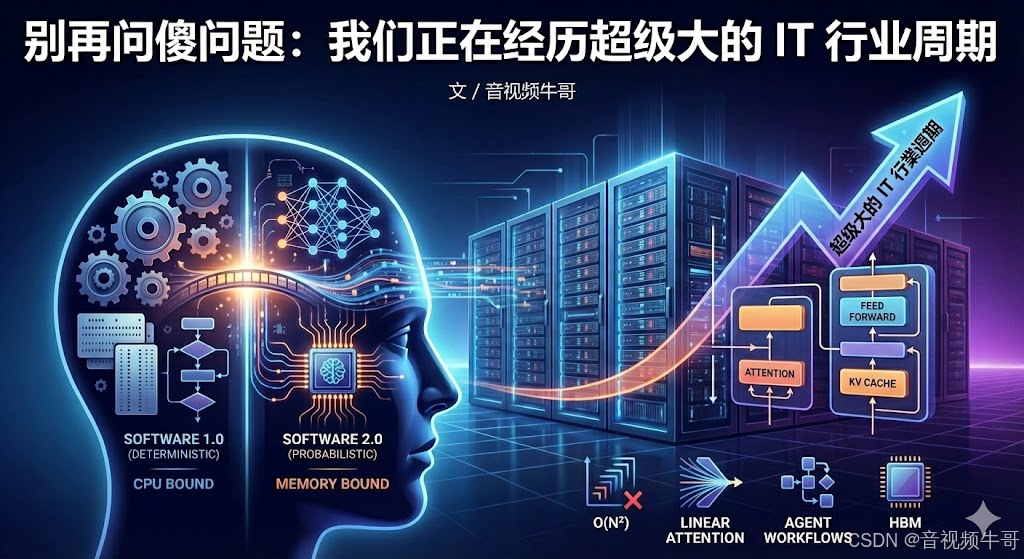
01|软件范式迁移:从“逻辑编码”到“概率优化”
在 Software 1.0 的时代,整个软件工程建立在**确定性逻辑(Deterministic Logic)**之上:
-
输入 A
-
执行函数 f(x)
-
输出必然是 B
程序员的工作,是把现实世界的逻辑翻译成 CPU 能理解的指令集(ISA)。
但 Software 2.0 出现后,这一切被彻底重写。
Karpathy 用一句话总结:
旧世界写规则,新世界写数据;
旧世界写逻辑,新世界写权重。
即:
旧世界:
Output = Code(Input)
规则显式存在于代码中。
新世界:
Output = Model(Input, Weights)
逻辑隐含在权重矩阵中。
这意味着:
-
可解释性 → 降低
-
模型能力 → 放大
-
开发范式 → 转向“概率系统治理”
真正的深水区,不是 Prompt,而是:
✔ 不可解释性治理
如何在概率性模型中构建“可控”“可审计”的业务流?
RAG、DSPy、CoT 本质都是为了让“随机的神经网络行为”走向“可控的产品行为”。
✔ 权重工程(Weight Engineering)
RLHF、LoRA、SFT 等微调方式,本质上是 新一代编译器优化。
你不是在调模型,你是在写“新时代版本的代码”。
这是第一次,程序不完全由人类写,而是由“训练过程”写。
02|冯·诺依曼架构正在被算力需求击穿
过去几十年,程序性能的瓶颈在 CPU 计算能力。
到了大模型时代,瓶颈完全变了。
模型推理(尤其是 Decoding)是典型的:
Memory-Bound(内存受限)工作负载
即:
-
FLOPS 够
-
HBM 不够
-
数据搬运速度远慢于算力释放速度
这也是为什么 H100 贵不是因为“算得快”,
而是因为它拥有:
-
HBM3e 高带宽显存
-
CoWoS 封装
-
极高的内存吞吐能力
GPU 不是贵在计算,而是贵在把那堆权重搬得够快。
于是工程师不得不面对新的学问:
✔ KV Cache 爆炸
长上下文模型(32K、128K、1M Token)正在把显存压到极限。
PageAttention、FlashAttention 都是为了让注意力不把你卡死。
✔ 通信开销成为核心矛盾
以前拼 CPU/GPU 算力,
现在拼:
-
NVLink
-
NVSwitch
-
InfiniBand
-
RDMA
你训练一台 70B 模型时,80% 的时间都在“通信”,不是“计算”。
这是整个计算机体系第一次被“模型尺寸”反向定义。
03|算法复杂度战争:O(N²) 的时代必须终结
Transformer 革命了 NLP,但也埋下了毒瘤:
Attention = O(N²)
输入序列每增加一倍,计算量直接平方膨胀。
当你把上下文窗口从 4K → 100K → 1M 时,代价根本不是线性上升,而是灾难性爆炸。
于是“后 Transformer 时代”已经开幕:
✔ Linear Attention
目的:让 Attention 的复杂度从二次方降到线性。
✔ SSM(状态空间模型)
如:Mamba、S4
推理复杂度接近 O(1),并保留训练并行性。
✔ MoE(混合专家模型)
不是扩大模型,是扩大“潜在容量”。
每次只激活部分网络,让大模型变得“像用小模型一样便宜”。
真正的技术人员关注的是:
Transformer 的时代正在进入“后期工业化阶段”,下一代架构已经出现在地平线上。
04|开发模式的重构:从 API 调用 → Agent 工作流
大多数人还停留在“写提示词(Prompt)”阶段,
而应用层真正的革新是:
我们正在从“面向对象(OOP)”,转向“面向 Agent(AOP)”。
未来的软件不是函数调用,而是“任务执行体”:
-
你给目标
-
Agent 自己规划路径(Planning)
-
自己调工具(Tool Use)
-
自己判断结果(Reflection)
-
自己管理状态(Memory)
这是第一次,应用具备了“主动性”。
这对工程师提出了完全不同的要求:
✔ 如何设计上下文管理
像操作系统的虚拟内存一样,
让有限 Context 模拟无限知识。
✔ 如何构建可控的 Agent
防止:
-
死循环
-
幻觉流程
-
工具滥用
-
状态膨胀
✔ 如何设计“LLM 时代的系统架构”
微服务 → 工作流 Orchestration
API → ToolChain
函数 → 思维过程(Thoughts)
这已经不是“生成文本”,
这是在构建 下一代软件操作系统。
结语:别再问 AI 会不会取代你
真正的问题不是:
“AI 会不会取代我?”
而是:
“你能否从旧范式跳到新范式?”
历史上每一次新周期,
被淘汰的从来不是人,
而是——
停留在旧周期的人。
现在的你,应该关心的不是 Java 下个语法糖,
而是:
-
Transformer 到底卡在什么地方?
-
HBM 与 CUDA 的真正瓶颈是什么?
-
如何构建工业级 RAG 系统?
-
Agent 的编排逻辑如何设计?
-
KV Cache 为什么会炸显存?
-
分布式推理的通信成本怎样优化?
这些问题,才属于这个“超级 IT 周期”的真正考题。
我们不是在经历一阵风,
我们正站在 计算范式重构的震中。
看懂周期的人,将迎来时代红利。
看不懂周期的人,只会看到焦虑。
选择哪一类,取决于你今天开始往哪里走。
📎 CSDN官方博客:音视频牛哥-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号