

像人类一样“看”世界:一文读懂 CNN 卷积神经网络
📝 写在前面
如果说互联网连接了人类, 那么 CNN(卷积神经网络) 的诞生, 则真正赋予了机器“睁眼看世界”的能力。
从刷脸支付到自动驾驶, 从AI 辅助诊疗到抖音魔法特效, CNN 早已渗透进数字生活的每一处毛细血管。
但在入门时,很多人都被那一连串高冷的术语劝退了:卷积核 (Kernel)?池化 (Pooling)?步长 (Stride)? 🤯
别担心。今天,我们拒绝堆砌晦涩的数学公式, 只用最通俗的语言拆解 CNN 的黑盒原理, 带你彻底看懂这块计算机视觉(CV)的绝对基石。
01|为什么不能用普通的神经网络?
在 CNN 称霸之前,我们用的是 全连接神经网络(MLP)。
如果你处理的是结构化数据(比如 Excel),MLP 很好用。
但如果你处理的是图片,MLP 就会崩溃。
❌ 痛点一:参数爆炸
假设一张普通的手机照片:
-
大小:1000 × 1000 像素
-
输入数据量:300 万
如果第一层有 1000 个神经元
➡️ 权重参数 ≈ 30 亿!
👉 计算量爆炸 + 极易过拟合(死记硬背)
❌ 痛点二:空间特征丢失
MLP 会把图片拉平成一条向量:
-
不知道像素之间的左右上下邻接关系
-
等于把拼图碎片打散
👉 图像中最重要的空间结构信息丢失
✅ CNN 的解法
| 核心思想 | 好处 |
|---|---|
| 局部连接 | 每次只看一小块区域 |
| 权值共享 | 特征在哪都能识别 |
这让 CNN 天生适合处理图像。
02|拆解 CNN 的“三驾马车”
一个典型的 CNN 就像一条流水线:
图片进去,分类结果出来。
主要由三大核心组件组成 👇
🔍 1⃣ 卷积层(Convolutional Layer)——特征提取器
想象你拿着放大镜扫描《清明上河图》。
-
卷积核(Kernel) = 放大镜
-
每个卷积核负责找一种特征
→ 竖直线、转角、圆形…
当扫描区域符合特征 → 输出高分
不符合 → 输出低分
📌 权值共享 = 特征平移也能识别
极大减少参数量。
⚡️ 2⃣ 激活函数(ReLU)——增加非线性
卷积是线性的,但现实世界不是。
ReLU:
f(x) = max(0, x)
-
小于 0 → 关掉
-
大于 0 → 保留
让模型“是非分明”。
📉 3⃣ 池化层(Pooling Layer)——信息过滤器
识别到眼睛后,
我们真的在乎它在第 105 行还是第 106 行吗?
不在乎。
最大池化 Max Pooling
| 作用 | 效果 |
|---|---|
| 降维 | 图像更小,计算更快 |
| 抗干扰 | 位置微变不影响结果(鲁棒性) |
03|宏观视角:从“瞎子摸象”到“全知全能”
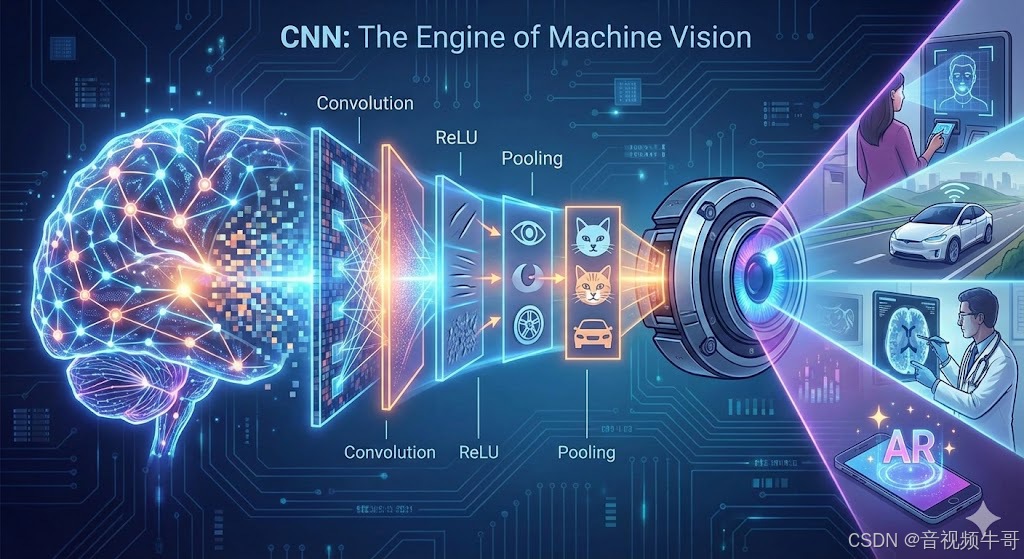
随着网络层数加深,提取特征越来越高级:
| 网络层级 | 能看到什么 |
|---|---|
| 👶 浅层(Low-Level) | 边缘、纹理、颜色斑块 |
| 👦 中层(Mid-Level) | 眼睛、圆形、条纹、方块 |
| 🧑🎓 深层(High-Level) | 脸、猫头、轮胎、蜂窝 |
最后将特征“拉平”进入全连接层:
有猫头 + 有胡须 + 有尖耳朵
= 99% 是猫 🐱
04|经典架构演进(致敬传奇)
理解 CNN,不仅要懂原理,更要懂历史。
从 1998 年的灵光一闪,到 2015 年的登峰造极,这四个经典架构不仅赢得了比赛,更定义了每一个时代深度学习的走向。
🏛️ LeNet-5 (1998)
关键词:开山鼻祖
核心贡献:确立“卷积-池化”标准范式
由 CNN 之父 Yann LeCun 提出。虽然当时主要用于简单的手写数字识别(MNIST),但它奠定了现代卷积神经网络最基础的 Conv -> Pool -> FC 结构,是所有后续架构的“基因源头”。
🚀 AlexNet (2012)
关键词:引爆奇点
核心贡献:ImageNet 冠军,深度学习爆发
沉寂十几年后的王者归来。它首次引入了 ReLU 激活函数解决梯度消失,使用 Dropout 防止过拟合,并利用 GPU 进行大规模并行计算。它以压倒性优势夺冠,标志着 AI 正式进入深度学习时代。
🧱 VGGNet (2014)
关键词:暴力美学
核心贡献:小卷积核堆叠,证明“越深越好”
它抛弃了大尺寸卷积核,全部采用 3*3 的极小卷积核进行层层堆叠。这种设计极大地减少了参数,同时增加了网络深度(16层/19层)。它告诉世界:深度(Depth)是提升性能的关键。
♾️ ResNet (2015)
关键词:工业基石
核心贡献:残差连接 (Skip Connection)
当网络过深时,会出现退化问题。ResNet 通过巧妙的“残差模块”,让信息可以走“捷径”直接传导。这使得训练 1000 层以上的网络成为可能。直到今天,ResNet 及其变体依然是工业界应用最广泛的骨干网络 (Backbone)。
05|硬核实战:由代码看本质
理论讲得再多,不如看一眼最小可用 CNN 是如何构成的。
以下 PyTorch 代码完整展示了,从图片输入到分类输出的整个流程:
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积块 1:提取基础边缘/纹理特征
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
# 卷积块 2:提取更高层次语义结构
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
# 分类头:将特征映射为类别概率
self.fc = nn.Linear(32 * 8 * 8, 10) # 10 类分类示例
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 特征展平 (Flatten)
out = self.fc(x)
return out
📌 仅几十行代码:
就让模型完成了:
-
🔹 卷积层提取特征
-
🔹 池化层压缩信息
-
🔹 全连接层做最终决策
换句话说👇
这就是一个能看懂图像的“小型大脑”
当你读懂它时,你就真正理解了 CNN 的工程本质。
06|总结
CNN 的伟大之处,在于它不仅仅是数学公式的堆砌,而是对生物进化的致敬。
它深度模仿了人类视觉皮层的层级结构,通过感受野的逐层扩大,洞察并巧妙利用了物理世界中图像的邻域关系与空间特征。这种独特的“归纳偏置”,让它天生就是为视觉而生。
如果用一句话总结 CNN:
它是一个精密的特征提取漏斗, 将杂乱无章的原始像素, 炼化为机器能深刻理解的“语义概念”。
放眼当下,虽然 Vision Transformer (ViT) 凭借全局注意力机制风头正盛,意图重塑视觉大模型格局,但在算力敏感和数据受限的真实落地场景中,CNN 依然不可替代。
凭借着:✔ 极致的推理效率✔ 对小样本数据的极佳友好度
CNN 依然稳坐计算机视觉领域的绝对主力,撑起了 AI “看”世界的半壁江山。
var code = "092a9292-7241-45fc-9493-9d2d8cfc5ff4"
 浙公网安备 33010602011771号
浙公网安备 33010602011771号