OMG-LLaVA学习记录---论文阅读笔记
OMG-LLaVA论文阅读笔记
Part1. 摘要-Abstract
Abstract阐述了现有通用模型的现状和问题
Current universal segmentation methods demonstrate strong capabilities in pixellevel image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions.
- 现状与问题1:这里是说现有的通用分割模型很擅长在像素层面“看懂”图像,也就是把图像的每个部分分割出来。但是,它们好像就是“哑巴”,我们不能通过文字命令它们,它们自己也不会思考和推理
In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction.
- 现状与问题呢2:相比之下,视觉多模态大模型能和我们进行对话和推理。但是,它们好像就是“瞎子”,它们缺乏像素级别的精细理解能力,也难以接受视觉提示以用来和用户灵活地交互
This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction.
- 提出解决方案:这篇文章提出了OMG-LLaVA,它将OMG-Seg和LLaVA结合,而且这是一个
优雅的框架,它既能有像素级的精细视觉能力,又有高级的推理对话能力。
Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user’s text instructions and providing text responses and pixel-level segmentation results based on the visual information.
- 实现方式:具体来说,我们使用一个通用分割模型(
OMG-Seg)作为视觉编码器,它的输出(视觉token)被送给一个大语言模型(LLM)。这个LLM不仅能生成文字回复,还能输出像素级的分割结果
We propose perception prior embedding to better integrate perception priors with image features.
- 关键创新: 这里提到了一个perception prior embedding技术(
感知先验嵌入)。它的作用是更好地融合图像特征和感知模块的“perception prior”(感知先验)
OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks.
- 最终效果:这一模型实现了三个层次的能力:
图像级(整个图的对话),对象级(图中某个物体的对话),像素级(精确分割)
Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.
- 设计理念:整个系统只包含一个编码器,一个解码器,一个LLM。追求一个更整合、端到端的方案,而不是让LLM去调用各种不同的模型
摘要小结 (问题来自Gemini2.5pro)
-
这篇论文要解决什么核心矛盾?
- 将大模型推理思考的能力和图像分割的能力整合起来
-
他们提出的模型叫什么?由哪两部分组成?
- OMG-LLaVA, 由OMG-seg和LLaVA两部分组成
-
这个模型最突出的特点是什么?(实现了哪三个层次的能力?)
- 实现了图像级-对象级-像素级三个层次的能力
-
他们的设计与其他多模态系统相比,有什么哲学上的不同?
- 很精简,只有一个LLM, 一个编码器,一个解码器
Part2. 引言-Introduction
With the development of transformer models [84, 5, 83, 36, 64, 82, 57, 115, 44, 77, 9, 17, 52], recent works in both natural language processing (NLP) and computer vision raise one common trend: adopting one unified model to solve multiple tasks. For example, large language models (LLMs) [83, 36, 82] adopt scale-up models to solve multiple NLP tasks and achieve better results than previous expert models. In vision, we have also seen a similar trend [17, 52, 90, 89, 42, 102], adopting one model to solve multiple tasks or sub-tasks, including detection, segmentation, video analysis, low-level vision, pose estimations, and more tasks. Different methods adopt different transformer designs, including visual-in-context learning [89, 90], unified decoder [17, 52], and unified tokenizer [76, 14, 52]. In summary, benefiting from the scalability and flexibility of the transformer, adopting one model for all tasks has made a great progress [17, 64, 65, 63, 115, 78, 77].
Meanwhile, by combining vision models and language models [64, 65, 63, 57, 58, 97], research on multi-modal models also adopts transformer-based design. One representative work, LLaVA [64, 65, 63], treats visual tokens as the inputs of LLMs and makes LLMs understand visual contents. Several works adopt similar designs [2, 12, 57, 16, 23], and all of them are termed Multi-modal Large Language Models (MLLMs). After that, most research focuses on improving MLLM benchmarks in various ways, including increasing data sizes [13, 16, 63] and enhancing the visual encoders [120, 22, 16] and visual resolutions [100, 16, 58, 23].
大趋势:作者提出了一个大趋势,现在更倾向于用一个统一的大模型解决所有任务
However, LLaVA-like models cannot output precise location information since they only carry out image-level analysis.
LLaVA的局限性:LLaVA这类模型虽然强大,但是它们只能做图像级的分析,无法输出精确的位置信息
Thus, recent works [115, 122, 10, 74, 12, 108, 117, 77, 60] try to fill this gaps by adding extra detection models for object level analysis, mask decoder for pixel-level analysis, visual prompts, and also propose task-specific instruction tuning with various datasets. By providing extra detection data and a decoder, the updated MLLMs can perform localization output. However, these models [123, 86, 44] are specifically tuned on specific tasks, losing the ability of LLaVA for image level analysis, such as caption and visual question answering.
前人的尝试与不足:前人做了很多工作尝试弥补这个缺陷,比如给LLaVA加上额外的检测或者分割模块。但问题是,这些“打了补丁”的模型往往在一个任务上调优后,就丧失了LLaVA原本强大的通用对话能力(比如图像描述)。导致了它们“偏了科”
Meanwhile, several works [115, 44, 77, 70] adopt LLMs as agents to collaborate with various visual models or generation models. Despite the works being simple and effective, the inference and parameter costs are huge due to the multiple visual encoders and decoders. Moreover, there are no specific designs for task unification.
另一种思路及其问题:另一种思路就是把LLM当作一个“中介”,由它来调用不同的视觉工具模型。这种方法虽然有效,但是系统臃肿,推理成本和参数量巨大
Motivated by the previous analysis, we ask one essential question: Can we bridge image-level, object-level, and pixel-level tasks into one MLLM model with only one LLM, one visual encoder, and one visual decoder? Back to the universal perception models, we can leverage these models to help us build a stronger MLLM to unify three-level inputs, including image, object, and pixel levels. In particular, we adopt OMG-Seg [52] as our universal perception model due to its simplicity and effectiveness in various segmentation tasks.
提出解决方法:作者直接点明了他们的目标:用最少的组件(一个LLM, 一个视觉编码器,一个视觉解码器)统一三个层次的任务
In this work, we present OMG-LLaVA, an elegant MLLM that bridges image-level, object-level, and pixel-level reasoning and understanding tasks in one model. We preserve the basic pixel-level segmentation ability of OMG-Seg by freezing the visual encoder and decoder, as shown in the bottom left of Fig. 1. Since the LLM processes text input, OMG-LLaVA can also perform referring segmentation, reasoning segmentation, and grounded conversation and generation, shown in the top left of Fig. 1. Moreover, as shown in Fig. 1, with the help of LLMs, OMG-LLaVA can also perform image-level understanding as LLaVA, including caption and conversation, where most MLLMs for grounding lose such ability. In addition, OMG-LLaVA also supports the visual prompts as inputs, which results in object level understanding, such as visual prompt-based conversation and region-level captions. We achieve all these abilities using one LLM, one encoder, and one decoder. In particular, to better encode the visual segmentation outputs, we propose a perception prior embedding module to absorb the object queries into object-centric visual tokens, which are the inputs of LLMs. We present a unified instruction formation strategy, which lets the model accept visual images, texts, and visual prompts as inputs and generate the response of text, segmentation tokens, segmentation masks, and labels. Following the LLaVA [64], we adopt pretraining and instruct tuning pipelines. Extensive experiments show the effectiveness of our components and training strategy. In addition to visual segmentation, OMG-LLaVA can also achieve good enough performance on 6 datasets, including COCO panoptic segmentation, VIPSeg video panoptic segmentation, refCOCO, refCOCO+, refCOCOg referring expression segmentation, GranDf grounded conversation generation, and refCOCOg region caption datasets. We hope our research can inspire the research on MLLM design in a more elegant way for the community.
OMG-LLaVA:这里透露了一个很关键的技术手段:为了保留OMG-seg的强大的分割能力,他们在训练中冻结了视觉编码器和解码器。这意味着视觉部分不在更新参数,大大降低了训练成本。
引言小结(问题来自Gemini2.5pro)
-
当前多模态领域存在哪几种技术路线来结合语言和精细化视觉?
- 给LLaVA加上额外的检测或分割模块
用一个LLM调用不同的视觉模型
- 给LLaVA加上额外的检测或分割模块
-
这些路线分别有什么优缺点?(例如,丧失通用性、系统臃肿等)
- 给LLaVA打补丁对视觉分割上有了提升,但是丧失了原本强大的通用对话能力
用LLM当中介有效但是臃肿,成本高
- 给LLaVA打补丁对视觉分割上有了提升,但是丧失了原本强大的通用对话能力
-
作者是如何基于对这些缺点的分析,提出自己的核心研究问题的?
- 提出要用最少的组件(一个LLM, 一个编码器和一个解码器)统一三个层次的任务
-
OMG-LLaVA 在设计上采取了什么关键策略来试图解决这些问题?(例如,简洁的架构、冻结视觉模块)
- 冻结了视觉编码器和解码器,意味着视觉部分不再更新参数,降低了训练成本
Part3 方法-Methodology
3.1 任务统一 - Task Unification
We model various tasks as the token-to-token generation to bridge the gap between image-level, object-level, and pixel-level understanding and reasoning. To support these tasks, we define three types of tokens: text tokens \(T_t\), pixel-centric visual tokens \(T_{pv}\), and object-centric visual tokens \(T_{ov}\). Text tokens encode textual information. Pixel-centric visual tokens represent dense image features, providing the LLM with comprehensive image information. Object-centric visual tokens encode the features of specified objects, offering the LLM object-centric information, and can be easily decoded into segmentation masks. Then, all the tasks can be unified as:$$ T^{out}t , T^{out} = LLM (T^{in}{pv} , T^{in} , T^{in}_t ) \ \ (1)$$For example, in the classic image-level understanding task, i.e., image caption, a text response \(T^{out}_t\) is generated based on text instruction \(T^{in}_t\) and image features \(T^{pv}_{in}\). In the object-level understanding task, region captioning, the text response \(T^{out}_t\) is generated based on text instruction \(T^{in}_t\), image features \(T^{pv}_{in}\), and specified object-centric visual tokens \(T^{in}_{ov}\). The pixel-level reasoning task, referring segmentation, involves generating object-centric visual tokens \(T^{out}_{ov}\) based on text instruction \(T_t^{in}\) and image features \(T_{pv}^{in}\). Additionally, OMG-LLaVA can support various mixed-level tasks, such as providing grounded descriptions around specified objects. Pixel-centric visual tokens can be obtained by tokenizing images using a CLIP backbone as the tokenizer. However, object-centric visual tokens require encoding object information to be easily decoded into segmentation masks. Therefore, methods like mask pooling in Osprey [115] and ROI pooling in GLaMM [77] fail to meet these requirements. We found that a universal perception decoder can meet all the requirements. Thus, we chose the OMG-Seg decoder [52] as the object-centric tokenizer due to its comprehensive capabilities.
- 核心思想: 就像LLM将所有NLP任务都统一为"输入一串token,输出一串token"一样,作者也将所有多模态任务统一为同样的样式
- 三种token:
- \(T_t\)(Text Tokens):就是普通文字
- \(T_{pv}\)(Pxiel-centric Visual Tokens): 代表了整张图的视觉信息,我们可以把它想象成对整张图片的一个“粗略但全面”的描述,它告诉LLM图片里大概有什么东西
- \(T_{ov}\)(Object-centric Visual Tokens):这是关键,它代表了图中特定对象的特征,它不仅告诉LLM这里有个东西,还包含了如何把它精确分割出来的信息
有了这三种token,所有的任务都可以被一个公式概况:$ T^{out}_t$ , \(T^{out}_{ov} = LLM (T^{in}_{pv}\) , \(T^{in}_{ov} , T^{in}_t )\)
- 图像级任务(如图像描述):基于 “文本指令\((\(T_t^{in}\))\)” 和 “图像特征\((\(T_{pv}^{in}\))\)”,生成 “文本响应$((T_t^{out}))”¥;
- 对象级任务(如区域描述):基于 “文本指令\((\(T_t^{in}\))\)”“图像特征((T_{pv}^{in}))” 和 “特定对象的视觉 token((T_{ov}^{in}))”,生成 “文本响应((T_t^{out}))”;
- 像素级任务(如图像分割):基于 “文本指令((T_t^{in}))” 和 “图像特征((T_{pv}^{in}))”,生成 “对象中心视觉 token((T_{ov}^{out}))”;
- 混合层级任务:OMG-LLaVA 还支持更灵活的任务(如 “为指定对象生成周边描述”)。
总的来说,它就是输入一堆混合的视觉和文本token,输出一堆新的文本和对象token
3.2 OMG-LLaVA框架(Framework)
我们来看一下具体的组件是如何生成和处理这些token的
- 输入:
- 一张图片
- 一段文字指令,其中可能包含特殊标记,比如
<Region> - 可选的视觉提示,比如点,框或者掩码
- OMG-Seg模块
- Image Encoder 将输入图片编码成图像特征
- 图像特征被送到两个地方:
- 经过一个
Visual Projector,被转换成 \(T_{pv}\), 送给LLM, 告诉它全图信息 - 送入
OMG Decoder,OMG Decoder会结合图像特征和一些内部的“learnable Queries”来自动检测图中的所有主要物体,并输出它们的\(T_{ov}\),这些token也会经过Visual Projector送给LLM。
- 经过一个
- 总的来说,OMG-Seg模块将负责将视觉世界“翻译”成LLM能理解的两种视觉语言(\(T_{pv}\)和\(T_{ov}\))
- LLM模块
- LLM接收来自用户的文本指令(\(T_{t}\))和来自OMG-Seg的两种视觉token(\(T_{pv}\)和\(T_{ov}\))
- 它理解所有的输入,然后生成一段回答,这个回答是文字和特殊token的混合体
- 输出
- LLM生成的普通文本token直接解码成文字答案
- 如果LLM生成了一个特殊的
[SEG]token,这个token不会被解码成文字,而是会经过一个Text Projector将其从"语言空间"映射回"视觉空间",然后送给冻结的OMG-Decoder,OMG-Decoder接收到这个信号后,就能准确地解码出对应的分割掩码(Segmentation Mask)
框架拆解 - OMG-LLaVA = OMG-Seg + LLM
-
Image Encoder 图像编码器
- 接收高分辨率(比如\(1024 \times 1024\))的原始图像,把它"看"成计算机能够理解的图像形式,也就是“图像特征”,但是一张高分辨率图片包含的信息太多了,都丢给LLM,由于计算量过大不可行,所以作者把图像特征的分辨率降低(比如下采样\(64\)倍),最终只生成了\(256\)个视觉token来代表整张图。这就像用\(256\)个关键点来概括一整幅画,既保留了核心信息,又减轻了计算负担
-
OMG Decoder OMG解码器
- “物体识别”,不仅仅是看懂整张图,也可以主动在图中找出具体的物体,并且生成代表这些物体的对象中心视觉token(\(T_{ov}\))
- 它有两种"工具"来寻找物体:
- Learnable Queries(可学习查询):会自动去图像特征里寻找最显著,最重要的物体
- Visual Prompts Queries(视觉提示查询):当用鼠标点一个点,或者画一个框来指定某个物品时,这些提示会被编码成特定的
mask去找到指定的物品
-
Preception Prior Embedding 感知先验嵌入
We find that directly combining a frozen perception module with LLM doesn’t perform well
这里说直接将感知模块和LLM结合效果很不好,这里提出了一种“预处理”的方法,在信息交给“LLM”之前,先把物体的“身份信息”直接“刻印”到图像的每一个像素特征上
- step1. OMG Decoder 为它找到的每个物体都生成一个预测的分割掩码(\(Mask\))
- step2. 利用这个掩码,计算出一个 掩码分数(\(MS\)) 这里用了\(softmax\),大概就是对于图上的每一个像素点,计算出它有多大的概率属于物体\(A\), 多大的概率属于物体\(B\)....
- step3. 用这个分数作为权重,将所有“对象查询(\(Q\))”进行加权平均
- step4. 将这个包含了物体身份信息的加权结果,直接加到原始的图像特征\(\mathcal{F}\)上,生成最终的像素中心视觉token(\(T_{pv}\))
-
\(Viusal\) \(Projector\) 和 \(Text\) \(Projector\) 视觉和文本投影器
- 相当于翻译官
- \(Viusal\) \(Projector\): 负责把\(OMG\) \(Decoder\)输出的两种视觉\(token\)(\(T_{pv}\)和\(T_{ov}\))从“视觉语言空间”翻译成\(LLM\)能理解的“文本语言空间”
- \(Text\) \(Projector\): 负责反向翻译,当\(LLM\)决定要输出一个分割结果是,它会生成一个特殊的
[SEG]token,然后它干的事情就是把这个\(token\)从“文本语言空间”翻译回“视觉语言空间”,让\(OMG\) \(Decoder\)指导该去哪里生成掩码了
-
\(Instruction\) \(Formulation\) 指令格式
- 一种固定格式,相当于“黑话”
<Image>这是一个占位符,在把指令交给“LLM”之前,系统会把这个词替换成所有准备号的视觉token<Region>指代用户通过视觉提示(如框)指定特定物体所对应的\(T_{ov}\)[SEG]这是LLM下达给OMG Decoder的行动指令,意思是:这不是一个话,而是要在这里画一个分割图
小结 (问题来自Gemini2.5pro)
-
请用你自己的话描述 \(T_{pv}\) 和 \(T_{ov}\) 的区别和各自的作用。
- \(T_{pv}\)代表了整个图的信息,粗略但是完整,作用是告诉了LLM整个图的大致信息
- \(T_{ov}\)代表了图中的特定对象的特征,作用是告诉了LLM具体信息,还告诉了LLM如何分割整个图
-
在 Figure 3 的流程中,一个“指代性分割”任务(比如“请分割出离镜头最远的火车”)的数据流是怎样的?(从输入问题和图片,到最终输出分割图)
- 文字提示传给LLM
- 图片传给Image Encoder, 然后传给OMG Decoder 接着传给 Visual Projector,最后是LLM,如果有[SEG]信息,就通过Text Projector传给OMG Decoder
-
论文中提出的“感知先验嵌入 (Perception Prior Embedding)”是为了解决什么问题?它的大致思路是什么?
- 解决LLM与OMG Decoder“语言不通”的问题
- 大致思路是将包含了物体身份的特征信息直接加到原始特征上,形成\(T_{ov}\)
-
特殊token
<Image>,<Region>,[SEG]在整个框架中分别扮演什么角色?- image是占位符,会把它替换成准备好的视觉token
- region指代用户通过视觉提示指定的特定物体对应的T_
- SEG表示这里要进行分割了
Part4. 实验-Experiment
数据集设置
为了训练和验证模型的“全能性”,用了多样化的数据集:
- 图像级能力(聊天,推理):使用LLaVA数据集
- 对象级能力(对物体提问):使用Osprey和MDVP数据集
- 像素级能力(分割,定位):
- 指代性分割:refCOCO, refCOCO+, refCOCOg等
- 语义分割:ADE20K, COCO-stuff
- 接地对话生成:DranDf数据集,这是一种复杂的任务,要求模型在生成描述文字的同时,分割出文字对应的物体
实施细节
-
核心组件:视觉模块是训练好的
ConvNext-L版的OMG-Seg,LLM是InterLM2-7B -
硬件与耗时: 训练是在4块NVIDIA A800 GPU 上进行了,预训练花了7个小时,指令微调花了48个小时
-
训练策略:训练时感知模块是冻结的,只使用
LoRA技术微调LLM以及投影层
4.1 结果展示
- 表2. 综合能力对比
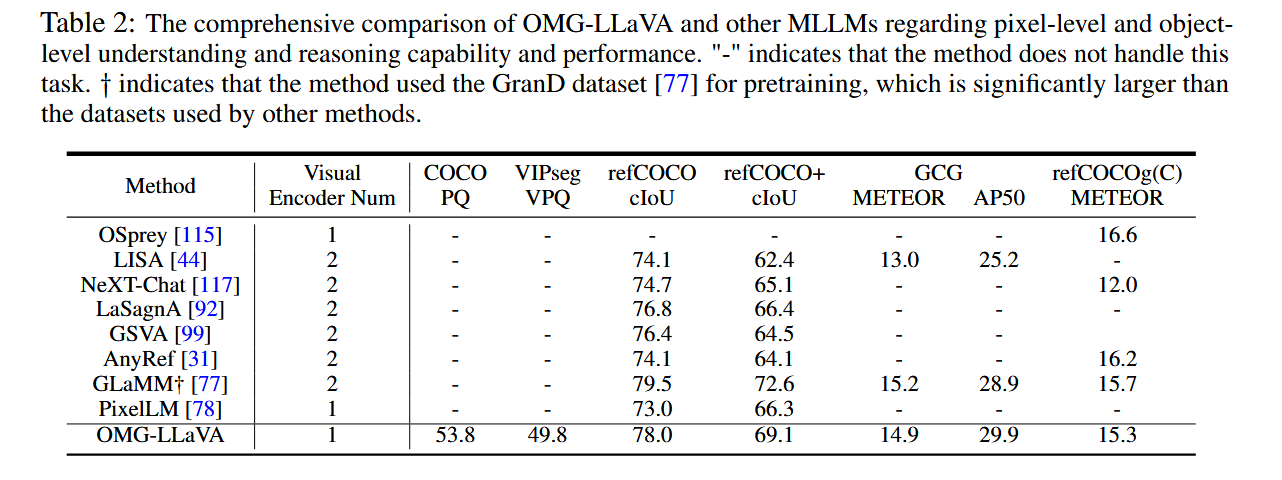
- 表3. 指代性分割(Referring expression segmentation)
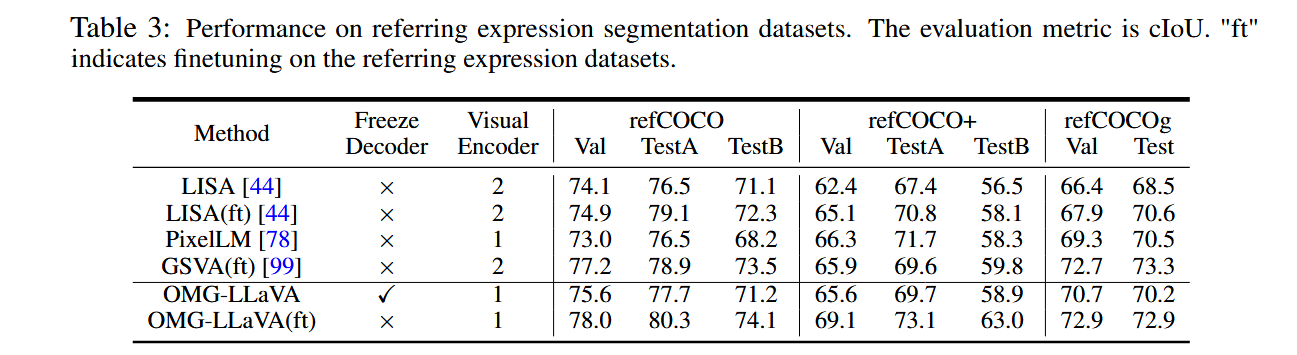
- 表4. 接地对话生成 (Grounded conversation generation)
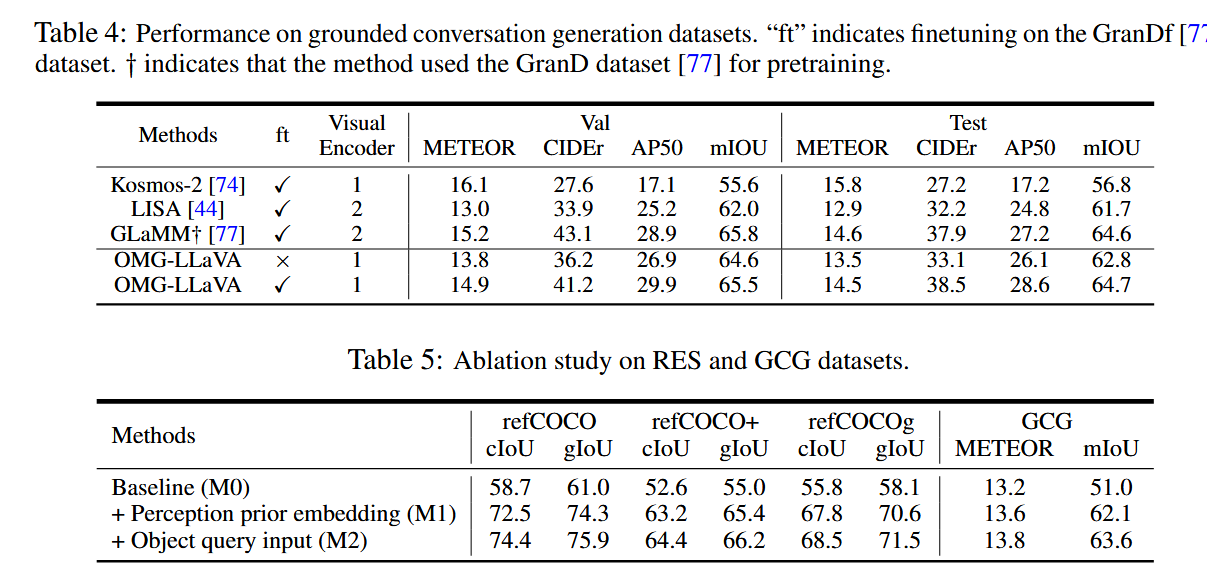
4.2 真的得益于"感知先验嵌入"吗 ------消融实验
人话:控制变量来看到底是不是某一部分起作用了

-
Baseline (M0) - 基础版:
这是一个最简单的组合,直接将
OMG-Seg和LLM粘在一起 。LLM 输出的 [SEG] token 直接送给冻结的 OMG-Seg 去解码成掩码 。这个版本没有使用作者提出的“感知先验嵌入”。结果比较差的原因
论文解释说,这是因为 LLM 自身没有任何分割的先验知识,它需要凭空生成一个“分割指令”来喂给一个它完全不了解的、冻结的视觉模块,这是一个极其困难的任务 。也就是之前讨论的“语言不通”问题。
-
Perception prior embedding (M1) - 加上“感知先验嵌入”:
在基础版 (M0) 的上,加入了作者的核心创新——“感知先验嵌入”策略。
结果比较好的原因
通过将对象的感知信息提前“刻印”到像素特征里,LLM 在理解图像时就有了“坐标系”,极大地降低了它生成准确分割指令的难度。
-
Object query input (M2) - 再加上“对象查询输入”:
在 M1 的基础上,除了将感知先验嵌入到像素 token (\(T_{pv}\)) 里,还把前景物体的查询 token (\(T_{ov}\)) 也作为额外的输入直接送给 LLM 。结果更好的原因
除了在像素级别融入先验知识外,再给 LLM一些物体级别的浓缩信息作为“参考”,能帮助它在一些情况下做出更精细的判断。
小结
-
简单地拼接LLM和冻结的视觉模块是行不通的
-
“感知先验嵌入”是解决问题的关键
-
在此基础上,额外给LLM提供对象级别的 token输入,能带来更好的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号