🎉在k8s调度的花园里面挖呀挖
上文使用koordinator演示gang-scheduling和binpack调度, 已经生效。
4个2卡Pod龟缩在一个节点,另外一个2卡Pod被挤到另外一个节点(每节点上虚拟gpu:8卡)。
此时我们再尝试申请8卡作业,pod会Pending状态。但一旦节点有资源,pod就会自动进入Running状态。
这就是resource.requests/limits 软调度的效果。
1. resource.requests/limits 软调度
上面的调度主要由requests配置来约束。
requests: 是“承诺资源”, kube-scheduler将requests cpu:1 的pod调度到某个node, 就相当于从该node资源池上划走了有一部分资源,这1核会被预定,不再承诺给其他pod,即使你这个pod只用了500m核。
limits: 是资源使用的上限,是由kubelet来强制执行。
2. k8s原生配额ResourceQuota: 硬隔离
当多个团队共享k8s集群节点资源时, 会有某一租户霸占大量资源的可能性。
资源配额就是用来解决这个问题:
资源配额作用在命名空间上(命名空间天生就是多租户概念的载体), 限制了该租户(命名空间)能创建的资源对象(+基础设施资源)的上限, 这个限制是通过api server在资源对象层面做到的。
ResourceQuota 相当于框定某一类资源的可用上限, 有“资源类型”、”配额作用域“ 等过滤资源的选项, 具体请参见ResouceQouta官方。
下面给出一个包含[基础设施资源、扩展资源、资源对象]的ResourceQuota:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi # 需求总量
limits.cpu: "2"
limits.memory: 2Gi # 限额总量
requests.example.com/dongle: 2
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
因为扩展资源不可超量分配,故没有必要为扩展资源同时指定requests和limits配置,只需指定requests.xxxx 即可。
因为配额的准入是在apiserver 资源对象层面, 所以当配额不足,不会产生pod处于pending的现象,kubectl命令会给出报错:pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota, 这点与resource.requests/limits 软调度不同。
提示:
ResourceQuota 与集群资源总量是完全独立的。它们通过绝对的单位来配置。
所以,为集群添加节点时,k8s资源配额不会自动赋予每个命名空间消耗更多资源的能力。
3. kueue 任务队列
上文k8s原生resourceQuota 是命名空间级别的硬资源限制,“它只负责限制, 不负责调度”。
在企业级多租户云环境中,为了①高效②灵活 利用集群资源, 需要“协调和调度”的能力。
kueue 这种任务队列就是这个作用,它不谋求替代k8s原生组件作用,工作在k8s原生调度器之上。
kueue是k8s上管理资源池配额和管控job消费资源池配额的任务队列系统,
kueue决定了job什么时候应该等待,什么时候被准入,什么时候job可以被抢占。
什么时候使用kueue?
① 需要弹性计算资源(可随时扩缩容)
② 计算资源是异构资源(架构、可用性、价格等因素)
这里我用自己的想法协助大家理解这①②点:
kueue中构建的clusterQueue引用的资源池配额是逻辑配额, 资源可以跨队列流动 (借用、抢占), 虽然和k8s原生配额一样都不与硬件资源直接挂钩,但很明显相比k8s原生配额更具弹性。
同构资源指的是所有计算节点/设备规格相同, 异构资源是指计算节点/设备规格/特性不同。

为什么会存在异构资源?
由业务需求驱动产生的不同设备形态(AI/ML工作负载、边缘计算、科学计算等要求的设备种类、设备规格、设备侧重都不同), 衍生出设备价格也不同。
下图是kueue的作用原理。

任务满足资源池配额,被准入后:
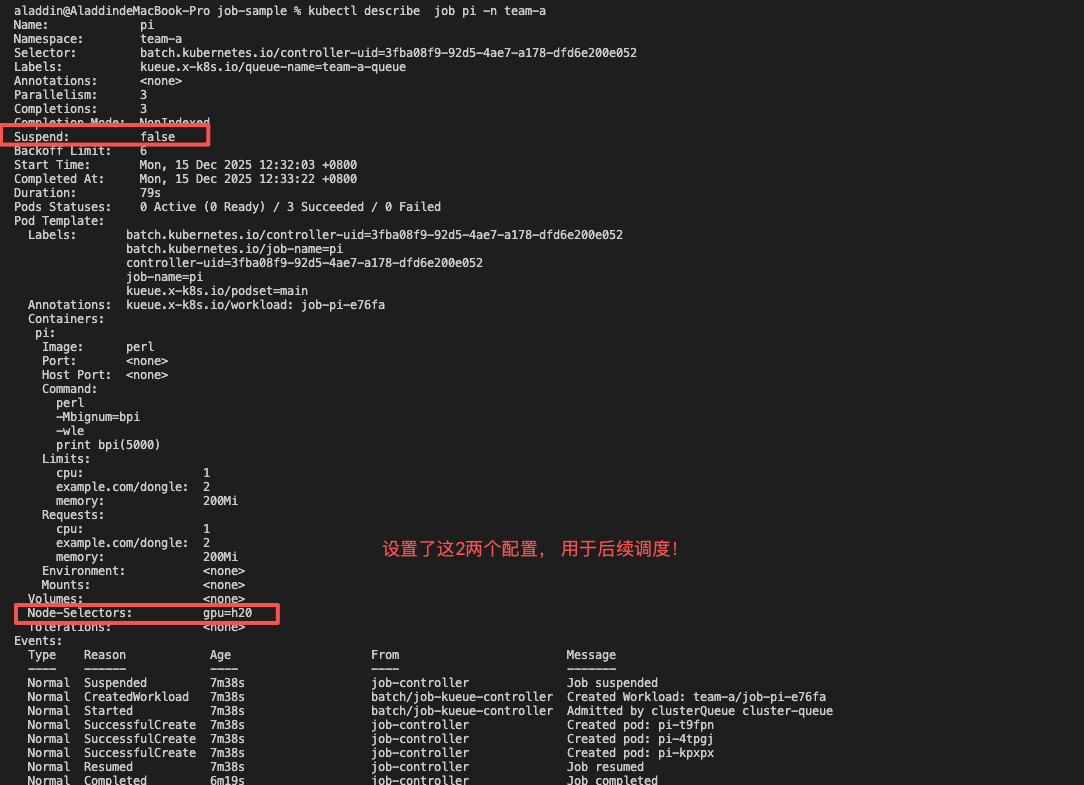
- kueue修改job的 suspend: false, 放行job
- kueue 向job注入nodeselector注解,将本次资源风味相关的信息给到job, 用于后续调度!!
3.1 资源高度抽象
上面的resource.requests/limits 和k8s原生resourceQuota 都没能跳脱worker 节点资源的概念。
kueue将worker节点上的资源抽象成由特定资源风味(ResourceFlavor)表征的资源池, 框定了某一类含有特定资源类型/规格的节点。
apiVersion: kueue.x-k8s.io/v1beta2
kind: ResourceFlavor
metadata:
name: "vgpu"
spec:
nodeLabels:
instance-type: vgpu
上面名为vgpu的资源风味 框定了带有instance-type=vgpu标签的节点
如果是同构资源,你也可以定义empty resource flavor。
然后基于框定的资源池给某个任务队列分发资源配额。
3.2 资源池的配额 nominalQuota
ClusterQueue 默认是集群级别的对象,定义了集群中某类资源风味的配额。
下面为cluster-queue的全局队列(依托于“default-flavor”资源池)定义了使用配额, 其中为稀缺资源example.com/dongle约束10卡。
kubectl label nodes minikube-m02/minikube-m03 gpu=h20 假设节点有这样的标签
命名空间team-a的localQueue引用了该clusterQueue。
apiVersion: kueue.x-k8s.io/v1beta2
kind: ResourceFlavor
metadata:
name: default-flavor ## 对同构资源,定义empty资源风味
spec:
nodeLabels:
gpu: h20 # 框定了含h20标签的节点
---
apiVersion: kueue.x-k8s.io/v1beta2
kind: ClusterQueue
metadata:
name: "cluster-queue"
spec:
namespaceSelector: {} # match all.
resourceGroups:
- coveredResources: ["cpu", "memory", "pods"]
flavors:
- name: "default-flavor"
resources:
- name: "cpu"
nominalQuota: 10
- name: "memory"
nominalQuota: 10Gi
- name: "example.com/dongle"
nominalQuota: 10
---
apiVersion: kueue.x-k8s.io/v1beta2
kind: LocalQueue
metadata:
namespace: team-a
name: team-a-queue
spec:
clusterQueue: cluster-queue
clusterQueue与localQueue的引用关系实现了共享全局资源池的理念。
形成的对象映射关系如下:

浅绿色是kueue产生的对象,浅蓝色是用户实际提交的批处理任务。
下面用一个k8s原生job来演示 kueue的工作表现。
apiVersion: batch/v1
kind: Job
metadata:
name: pi3
labels:
kueue.x-k8s.io/queue-name: team-a-queue
spec:
parallelism: 3 # 并行执行次数,默认为1
completions: 3 # 完成次数,默认为parallelism的值
suspend: true # 应该在挂起状态下创建job,由kueue来决定何时启动job
template:
spec:
containers:
- name: pi
image: perl
imagePullPolicy: IfNotPresent
command: [ "perl", "-Mbignum=bpi", "-wle", "print bpi(5000)" ]
resources:
requests:
cpu: "1"
memory: "200Mi"
example.com/dongle: "2"
limits:
cpu: "1"
memory: "200Mi"
example.com/dongle: "2"
restartPolicy: Never
# Job 代表一次性任务,运行完成到停止,它将π计算到5000个位置并将其打印出来。完成大约需要60秒。 之后pod状态是 Completed
这里最重要的是配置是job中的"suspend:true", job应该以挂起状态被创建,由kueue来决定何时启动, 不需要这个suspend:true配置,加上了kueue.x-k8s.io/queue-name: team-a-queue就能受kueue管控。- 在原生job标签关联localqueue
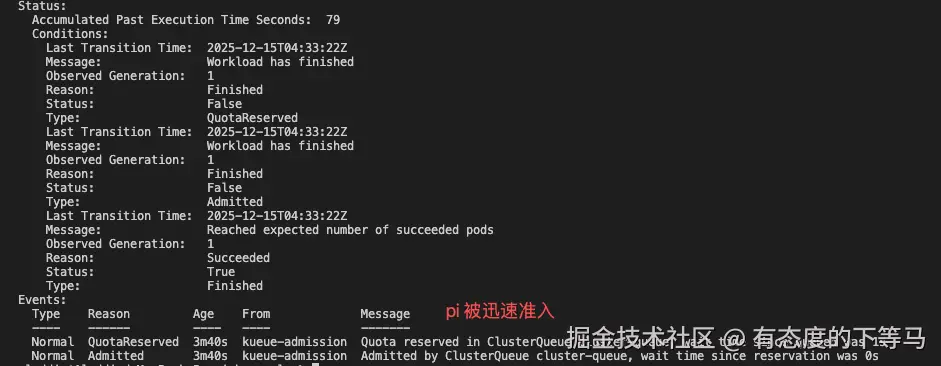
提交第一个任务,3个Pod占用了6卡;
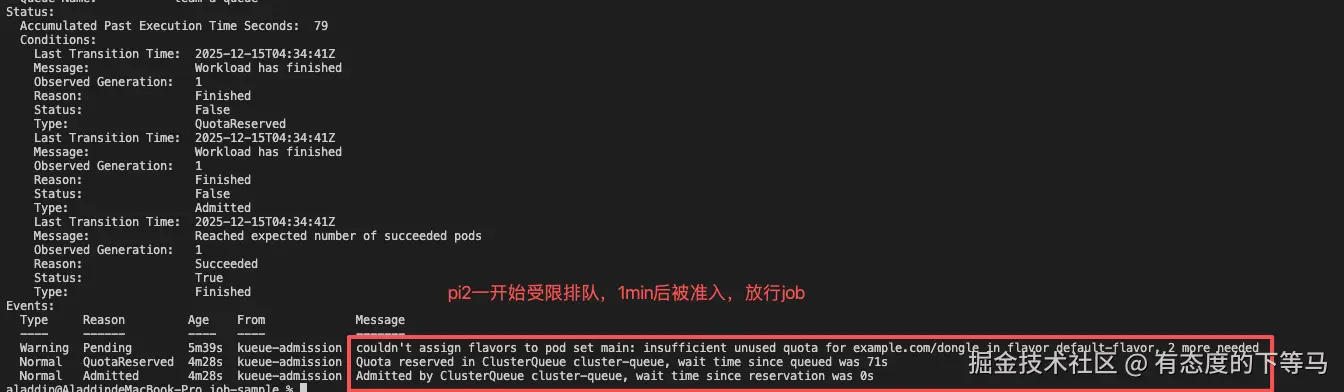
再立刻启动同样配置的第二个任务,受localqueue中nominalQuota: 10的约束,任务2会pending

等待任务1执行完,释放了example.com/dongle资源,最后进入runing状态跑完任务,分别查看任务1和任务2的准入事件:
最后验证实际job被kueue修改的配置:
kueue 还有很多特性,读者自行审阅,修行在个人。
① 核心的clusterqueue默认的排队策略是: BestEffortFIFO: 先按优先级排序,再按照创建时间;未被准入的旧任务不会影响后续能被准入的新来任务。
② 支持队列组Cohort, 可实现资源弹性借用
③ 注意队列组、clusterqueue与资源风味的1对多的关系。

在企业级多租户、强资源生产隔离、计费要求的背景下,一般是独立clusterQueue 与 共享ClusterQueue结合的做法。
4. 总结
今天主要在调度这个花园里面挖呀挖, 更准确的是聚焦在“准入”这个动作上展开思路。
k8s原生资源配额的目的:不是为了优化调度,而是在多租户背景下,约束资源的硬使用边界。
ResourceQuota 框定了命名空间中某些资源的产生上限;
kueue资源池的配额约束了某些细粒度要求的资源池的逻辑边界,通过resourceFalvor抽象出资源池的概念, kueue通过”排队“这个概念细化了准入这个动作,在kube-scheduler工作前管控了批处理任务的调度。
本文来自博客园,作者:{有态度的马甲},转载请注明原文链接:https://chuna2.787528.xyz/JulianHuang/p/19351159
欢迎关注我的原创技术、职场公众号, 加好友谈天说地,一起进化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号