
HELLO-AGENTS
https://github.com/datawhalechina/hello-agents
task00
task00:前言
- 了解了学习目标和内容。
- 大体的五部分划分和学习方向。
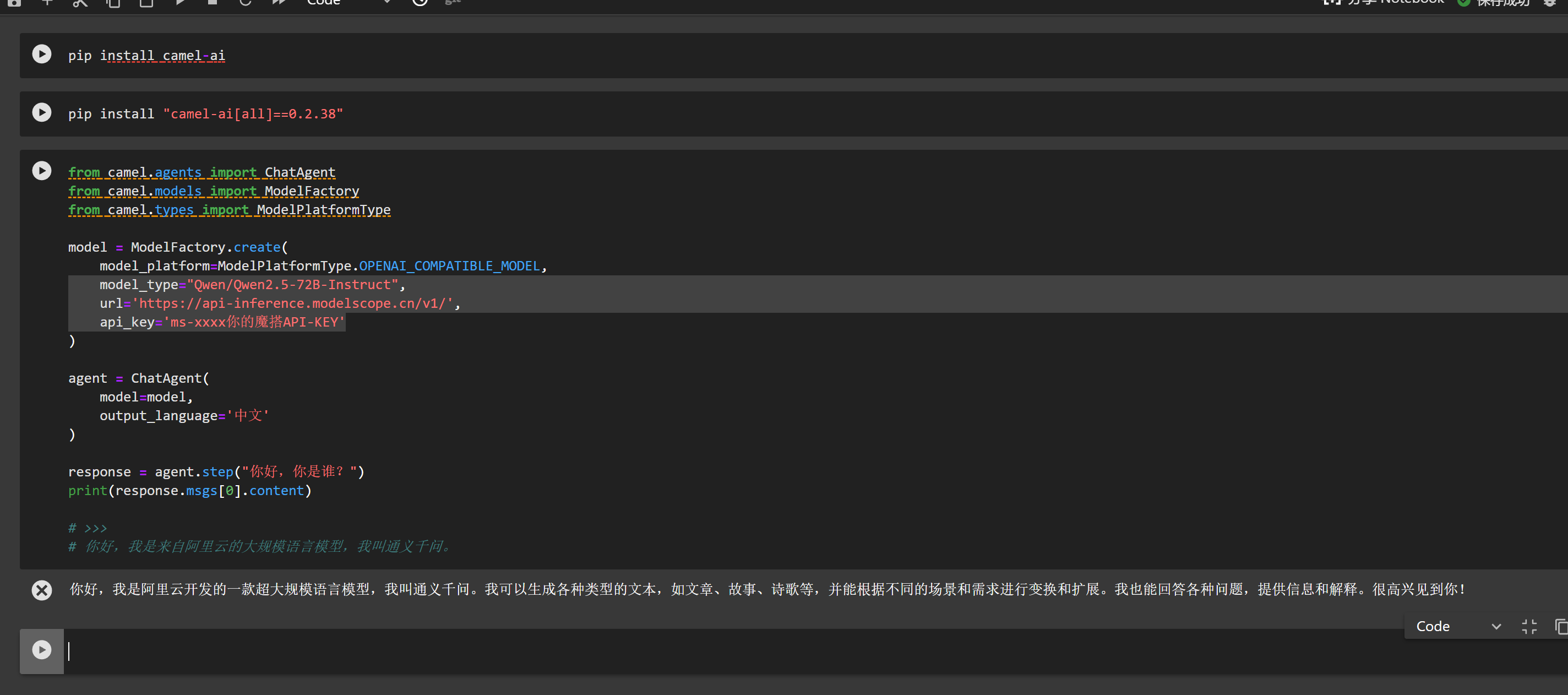
pip install "camel-ai[all]==0.2.38"
pip install "camel-ai[all]==0.2.38"
#%%
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key='ms-xxxx你的魔搭API-KEY'
)
agent = ChatAgent(
model=model,
output_language='中文'
)
response = agent.step("你好,你是谁?")
print(response.msgs[0].content)
# >>>
# 你好,我是来自阿里云的大规模语言模型,我叫通义千问。
task01
task01:
- 了解了什么是智能体。
- 大语言模型的范式。
- 智能体的类型。
- 了解了 Workflow 和 Agent 的区别。
Agent的工作过程
- 感知 (Perception);
- 思考 (Thought);
2.1. 规划 (Planning);
2.2. 行动/执行 (Action); - 智能体的行动会引起环境 (Environment) 的状态变化 (State Change),环境随即会产生一个新的观察 (Observation) 作为结果反馈。
- 形成一个持续的“感知-思考-行动-观察”的闭环
- 感知环境
- 规划行动
- 执行行动
- 评估结果
- 迭代优化
智能体的核心是 Thought-Action-Observation(TAO)循环.
PEAS
- 性能度量(Performance)
- 环境(Environment)
- 执行器(Actuators)
- 传感器(Sensors)

然而,其“阿喀琉斯之踵”在于脆弱性:它依赖于一个完备的规则体系,但在充满模糊和例外的现实世界中,任何未被覆盖的新情况都可能导致系统失灵,这就是所谓的“知识获取瓶颈”。



5 分钟实现第一个智能体
# (1)指令模板
TAVILY_API_KEY = 'tvly-dev-XXXX 你申请的KEY' # 地址:https://www.tavily.com/
YOUR_API_KEY = 'ms-xxxxx 你的魔搭API-KEY'
AGENT_SYSTEM_PROMPT = """
你是一个智能旅行助手。你的任务是分析用户的请求,并使用可用工具一步步地解决问题。
# 可用工具:
- `get_weather(city: str)`: 查询指定城市的实时天气。
- `get_attraction(city: str, weather: str)`: 根据城市和天气搜索推荐的旅游景点。
# 行动格式:
你的回答必须严格遵循以下格式。首先是你的思考过程,然后是你要执行的具体行动,每次回复只输出一对Thought-Action:
Thought: [这里是你的思考过程和下一步计划]
Action: [这里是你要调用的工具,格式为 function_name(arg_name="arg_value")]
# 任务完成:
当你收集到足够的信息,能够回答用户的最终问题时,你必须在`Action:`字段后使用 `finish(answer="...")` 来输出最终答案。
请开始吧!
"""
# (2)工具 1:查询真实天气
import requests
import json
def get_weather(city: str) -> str:
"""
通过调用 wttr.in API 查询真实的天气信息。
"""
# API端点,我们请求JSON格式的数据
url = f"https://wttr.in/{city}?format=j1"
try:
# 发起网络请求
response = requests.get(url)
# 检查响应状态码是否为200 (成功)
response.raise_for_status()
# 解析返回的JSON数据
data = response.json()
# 提取当前天气状况
current_condition = data['current_condition'][0]
weather_desc = current_condition['weatherDesc'][0]['value']
temp_c = current_condition['temp_C']
# 格式化成自然语言返回
return f"{city}当前天气:{weather_desc},气温{temp_c}摄氏度"
except requests.exceptions.RequestException as e:
# 处理网络错误
return f"错误:查询天气时遇到网络问题 - {e}"
except (KeyError, IndexError) as e:
# 处理数据解析错误
return f"错误:解析天气数据失败,可能是城市名称无效 - {e}"
# (3)工具 2:搜索并推荐旅游景点
import os
from tavily import TavilyClient
def get_attraction(city: str, weather: str) -> str:
"""
根据城市和天气,使用Tavily Search API搜索并返回优化后的景点推荐。
"""
# 1. 从环境变量中读取API密钥
api_key = TAVILY_API_KEY # os.environ.get("TAVILY_API_KEY")
if not api_key:
return "错误:未配置TAVILY_API_KEY环境变量。"
# 2. 初始化Tavily客户端
tavily = TavilyClient(api_key=api_key)
# 3. 构造一个精确的查询
query = f"'{city}' 在'{weather}'天气下最值得去的旅游景点推荐及理由"
try:
# 4. 调用API,include_answer=True会返回一个综合性的回答
response = tavily.search(query=query, search_depth="basic", include_answer=True)
# 5. Tavily返回的结果已经非常干净,可以直接使用
# response['answer'] 是一个基于所有搜索结果的总结性回答
if response.get("answer"):
return response["answer"]
# 如果没有综合性回答,则格式化原始结果
formatted_results = []
for result in response.get("results", []):
formatted_results.append(f"- {result['title']}: {result['content']}")
if not formatted_results:
return "抱歉,没有找到相关的旅游景点推荐。"
return "根据搜索,为您找到以下信息:\n" + "\n".join(formatted_results)
except Exception as e:
return f"错误:执行Tavily搜索时出现问题 - {e}"
# 将所有工具函数放入一个字典,方便后续调用
available_tools = {
"get_weather" : get_weather,
"get_attraction": get_attraction,
}
# 1.3.2 接入大语言模型
from openai import OpenAI
class OpenAICompatibleClient:
"""
一个用于调用任何兼容OpenAI接口的LLM服务的客户端。
"""
def __init__(self, model: str, api_key: str, base_url: str):
self.model = model
self.client = OpenAI(api_key=api_key, base_url=base_url)
def generate(self, prompt: str, system_prompt: str) -> str:
"""调用LLM API来生成回应。"""
print("正在调用大语言模型...")
try:
messages = [
{'role': 'system', 'content': system_prompt},
{'role': 'user', 'content': prompt}
]
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
stream=False
)
answer = response.choices[0].message.content
print("大语言模型响应成功。")
return answer
except Exception as e:
print(f"调用LLM API时发生错误: {e}")
return "错误:调用语言模型服务时出错。"
# 1.3.3 执行行动循环
import re
# --- 1. 配置LLM客户端 ---
# 请根据您使用的服务,将这里替换成对应的凭证和地址
API_KEY = YOUR_API_KEY #os.environ.get("YOUR_API_KEY") # YOUR_API_KEY"
BASE_URL = 'https://api-inference.modelscope.cn/v1/' #os.environ.get("YOUR_BASE_URL") # "YOUR_BASE_URL" 参考 https://modelscope.cn/my/myaccesstoken
MODEL_ID = 'Qwen/Qwen2.5-Coder-32B-Instruct' #os.environ.get("YOUR_MODEL_ID") # "YOUR_MODEL_ID"
# TAVILY_API_KEY = TAVILY_API_KEY# os.environ.get("TAVILY_API_KEY") # "YOUR_Tavily_KEY"
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEY #"YOUR_TAVILY_API_KEY"
llm = OpenAICompatibleClient(
model=MODEL_ID,
api_key=API_KEY,
base_url=BASE_URL
)
# --- 2. 初始化 ---
# user_prompt = "你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。"
user_prompt = "你好,请帮我查询一下今天上海的天气,然后根据天气推荐一个合适的旅游景点。"
prompt_history = [f"用户请求: {user_prompt}"]
print(f"用户输入: {user_prompt}\n" + "=" * 40)
# --- 3. 运行主循环 ---
for i in range(5): # 设置最大循环次数
print(f"--- 循环 {i + 1} ---\n")
# 3.1. 构建Prompt
full_prompt = "\n".join(prompt_history)
# 3.2. 调用LLM进行思考
llm_output = llm.generate(full_prompt, system_prompt=AGENT_SYSTEM_PROMPT)
# 模型可能会输出多余的Thought-Action,需要截断
match = re.search(r'(Thought:.*?Action:.*?)(?=\n\s*(?:Thought:|Action:|Observation:)|\Z)', llm_output, re.DOTALL)
if match:
truncated = match.group(1).strip()
if truncated != llm_output.strip():
llm_output = truncated
print("已截断多余的 Thought-Action 对")
print(f"模型输出:\n{llm_output}\n")
prompt_history.append(llm_output)
# 3.3. 解析并执行行动
action_match = re.search(r"Action: (.*)", llm_output, re.DOTALL)
if not action_match:
print("解析错误:模型输出中未找到 Action。")
break
action_str = action_match.group(1).strip()
if action_str.startswith("finish"):
final_answer = re.search(r'finish\(answer="(.*)"\)', action_str).group(1)
print(f"任务完成,最终答案: {final_answer}")
break
tool_name = re.search(r"(\w+)\(", action_str).group(1)
args_str = re.search(r"\((.*)\)", action_str).group(1)
kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))
if tool_name in available_tools:
observation = available_tools[tool_name](**kwargs)
else:
observation = f"错误:未定义的工具 '{tool_name}'"
# 3.4. 记录观察结果
observation_str = f"Observation: {observation}"
print(f"{observation_str}\n" + "=" * 40)
prompt_history.append(observation_str)

习题四
习题六
- 智能体 “幻觉” 的产生原因
“幻觉” 是智能体生成 “看似合理但实际错误” 信息的现象,核心原因的是 “统计匹配≠事实理解”:
模型本质缺陷:大语言模型(LLM)是基于训练数据的 “下一个词预测”,而非真正理解事实。它会学习数据中的统计规律(如 “某景点门票价格” 常与 “XX 元” 关联),但无法判断信息的真实性;
训练数据问题:训练数据中可能存在错误、矛盾、过时的信息(如旧的景点开放时间),模型学到后会生成错误内容;
缺乏实时核查:智能体未接入外部真实数据源(如实时门票系统、最新政策文档),仅依赖内部知识,导致信息滞后或错误;
上下文遗忘:长文本处理时,上下文窗口有限,可能遗忘关键信息(如用户说 “预算 3000”,后续推荐时生成 “5000 元高端酒店”);
迎合用户倾向:模型为了满足用户需求,会生成 “看似合理” 的内容(如用户问 “某景点是否开放”,模型不确定时仍会给出 “开放时间为 XX” 的答案)。 - 无最大循环次数限制的问题
若智能体的 TAO 循环无次数限制,可能陷入以下困境:
无限循环:如 “推荐景点→用户拒绝→调整推荐→用户再拒绝→再调整”,一直循环无法终止(尤其是用户需求不明确时);
资源耗尽:每次循环需消耗 CPU、内存(如查询 API、推理计算),无限循环会导致系统崩溃;
任务漂移:多次调整后偏离初始目标(如用户要 “历史景点”,调整后变成推荐 “美食”);
用户体验恶化:持续推送无效推荐,让用户厌烦(如连续 10 次推荐用户不喜欢的景点);
逻辑死锁:如备选景点一直售罄,智能体反复查询无结果,无法停止。
task02

import re
import random
# 定义规则库:模式(正则表达式) -> 响应模板列表
rules = {
r'I need (.*)': [
"Why do you need {0}?",
"Would it really help you to get {0}?",
"Are you sure you need {0}?"
],
r'Why don\'t you (.*)\?': [
"Do you really think I don't {0}?",
"Perhaps eventually I will {0}.",
"Do you really want me to {0}?"
],
r'Why can\'t I (.*)\?': [
"Do you think you should be able to {0}?",
"If you could {0}, what would you do?",
"I don't know -- why can't you {0}?"
],
r'I am (.*)': [
"Did you come to me because you are {0}?",
"How long have you been {0}?",
"How do you feel about being {0}?"
],
r'.* mother .*': [
"Tell me more about your mother.",
"What was your relationship with your mother like?",
"How do you feel about your mother?"
],
r'.* father .*': [
"Tell me more about your father.",
"How did your father make you feel?",
"What has your father taught you?"
],
r'.*': [
"Please tell me more.",
"Let's change focus a bit... Tell me about your family.",
"Can you elaborate on that?"
]
}
# 定义代词转换规则
pronoun_swap = {
"i": "you", "you": "i", "me": "you", "my": "your",
"am": "are", "are": "am", "was": "were", "i'd": "you would",
"i've": "you have", "i'll": "you will", "yours": "mine",
"mine": "yours"
}
def swap_pronouns(phrase):
"""
对输入短语中的代词进行第一/第二人称转换
"""
words = phrase.lower().split()
swapped_words = [pronoun_swap.get(word, word) for word in words]
return " ".join(swapped_words)
def respond(user_input):
"""
根据规则库生成响应
"""
for pattern, responses in rules.items():
match = re.search(pattern, user_input, re.IGNORECASE)
if match:
# 捕获匹配到的部分
captured_group = match.group(1) if match.groups() else ''
# 进行代词转换
swapped_group = swap_pronouns(captured_group)
# 从模板中随机选择一个并格式化
response = random.choice(responses).format(swapped_group)
return response
# 如果没有匹配任何特定规则,使用最后的通配符规则
return random.choice(rules[r'.*'])
# 主聊天循环
if __name__ == '__main__':
print("Therapist: Hello! How can I help you today?")
while True:
user_input = input("You: ")
if user_input.lower() in ["quit", "exit", "bye"]:
print("Therapist: Goodbye. It was nice talking to you.")
break
response = respond(user_input)
print(f"Therapist: {response}")
# >>>
# Therapist: Hello! How can I help you today?
# You: I am feeling sad today.
# Therapist: How long have you been feeling sad today?
# You: I need some help with my project.
# Therapist: Are you sure you need some help with your project?
# You: My mother is not happy with my work.
# Therapist: Tell me more about your mother.
# You: quit
# Therapist: Goodbye. It was nice talking to you.

task02:
- 充分 + 必要
- 符号 -> 专家系统 -> 模式匹配 -> 【元年】协作体 (颠覆性构想,不再将心智视为一个金字塔式的层级结构,而是将其看作一个扁平化的、充满了互动与协作的“社会”。){智能本身就是“不完美”的、由许多功能各异、甚至会彼此冲突的简单部分组成的大杂烩。} -> 机构(Agency) /
涌现(Emergence) -> 多智能体 -> 联结主义(Connectionism)/ 强化学习(Reinforcement Learning, RL) -> 行为主义 (Behaviorism)





task03
import collections
# 示例语料库,与上方案例讲解中的语料库保持一致
corpus = "datawhale agent learns datawhale agent works"
tokens = corpus.split()
total_tokens = len(tokens)
# --- 第一步:计算 P(datawhale) ---
count_datawhale = tokens.count('datawhale')
p_datawhale = count_datawhale / total_tokens
print(f"第一步: P(datawhale) = {count_datawhale}/{total_tokens} = {p_datawhale:.3f}")
# --- 第二步:计算 P(agent|datawhale) ---
# 先计算 bigrams 用于后续步骤
bigrams = zip(tokens, tokens[1:])
bigram_counts = collections.Counter(bigrams)
count_datawhale_agent = bigram_counts[('datawhale', 'agent')]
# count_datawhale 已在第一步计算
p_agent_given_datawhale = count_datawhale_agent / count_datawhale
print(f"第二步: P(agent|datawhale) = {count_datawhale_agent}/{count_datawhale} = {p_agent_given_datawhale:.3f}")
# --- 第三步:计算 P(learns|agent) ---
count_agent_learns = bigram_counts[('agent', 'learns')]
count_agent = tokens.count('agent')
p_learns_given_agent = count_agent_learns / count_agent
print(f"第三步: P(learns|agent) = {count_agent_learns}/{count_agent} = {p_learns_given_agent:.3f}")
# --- 最后:将概率连乘 ---
p_sentence = p_datawhale * p_agent_given_datawhale * p_learns_given_agent
print(f"最后: P('datawhale agent learns') ≈ {p_datawhale:.3f} * {p_agent_given_datawhale:.3f} * {p_learns_given_agent:.3f} = {p_sentence:.3f}")
# >>>
# 第一步: P(datawhale) = 2 / 6 = 0.333
# 第二步: P(agent | datawhale) = 2 / 2 = 1.000
# 第三步: P(learns | agent) = 1 / 2 = 0.500
# 最后: P('datawhale agent learns') ≈ 0.333 * 1.000 * 0.500 = 0.167

task03:
- 现代智能体是如何工作的?
-- 概率
-- 完整的链式法则 -> 马尔可夫假设 (Markov Assumption) -> N-gram模型

-- 我们不必回溯一个词的全部历史,可以近似地认为,一个词的出现概率只与它前面有限的 n−1 个词有关
--- Bigram :N=2 最简单的情况,假设一个词的出现只与它前面的一个词有关。
--- Trigram: N=3 假设一个词的出现只与它前面的两个词有关。
--- 最大似然估计(Maximum Likelihood Estimation,MLE) 最可能出现的,就是我们在数据中看到次数最多的。
-- 致命缺陷
--- 稀疏性问题:当语料库中某些词的出现次数非常少时,它们的概率估计变得不准。
--- 泛化能力差:本质是不理解。 - 前馈神经网络语言模型 (Feedforward Neural Network Language Model)

import numpy as np
# 假设我们已经学习到了简化的二维词向量
embeddings = {
"king": np.array([0.9, 0.8]),
"queen": np.array([0.9, 0.2]),
"man": np.array([0.7, 0.9]),
"woman": np.array([0.7, 0.3])
}
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_product = np.linalg.norm(vec1) * np.linalg.norm(vec2)
return dot_product / norm_product
# king - man + woman
result_vec = embeddings["king"] - embeddings["man"] + embeddings["woman"]
# 计算结果向量与 "queen" 的相似度
sim = cosine_similarity(result_vec, embeddings["queen"])
print(f"king - man + woman 的结果向量: {result_vec}")
print(f"该结果与 'queen' 的相似度: {sim:.4f}")
# >>>
# king - man + woman 的结果向量: [0.9 0.2]
# 该结果与 'queen' 的相似度: 1.0000

-- 语义空间 ,词嵌入 (Word Embedding) 或词向量 ,高维的连续向量空间,词汇表中的每个词都映射为该空间中的一个点。语义上相近的词,它们对应的向量在空间中的位置也相近。
-- 从上下文到下一个词的映射 ,函数的输入是前 n−1 个词的词向量,输出是词汇表中每个词在当前上下文后出现的概率分布。
余弦相似度 (Cosine Similarity) ,它通过计算两个向量夹角的余弦值来衡量它们的相似性。
- 循环神经网络 (RNN) 与长短时记忆网络 (LSTM) -> 循环神经网络 (Recurrent Neural Network, RNN) 为网络增加“记忆”能力, 引入了一个隐藏状态 (hidden state) 向量(网络的短期记忆)

- 循环神经网络 (RNN) 与长短时记忆网络 (LSTM) -> 循环神经网络 (Recurrent Neural Network, RNN) 为网络增加“记忆”能力, 引入了一个隐藏状态 (hidden state) 向量(网络的短期记忆)
-- 缺陷
--- 长期依赖问题 (Long-term Dependency Problem)
-> 长短时记忆网络 (Long Short-Term Memory, LSTM) 解决,引入细胞状态 (Cell State) 和 门控机制 (Gating Mechanism)- 细胞状态 (Cell State) :用于存储长期信息,独立于隐藏状态的信息通路。
- 门控机制 (Gating Mechanism) :包括遗忘门、输入门和输出门,用于控制信息在细胞状态中的流动。
-- 遗忘门 (Forget Gate):决定从上一时刻的细胞状态中丢弃哪些信息。
-- 输入门 (Input Gate):决定将当前输入中的哪些新信息存入细胞状态。
-- 输出门 (Output Gate):决定根据当前的细胞状态,输出哪些信息到隐藏状态。
-> Transformer 架构 ,提高大规模的并行计算能力,完全抛弃了循环结构,转而完全依赖一种名为注意力 (Attention) 的机制来捕捉序列内的依赖关系。
1.Encoder-Decoder 整体结构
2.从自注意力到多头注意力
3.前馈神经网络
4.残差连接与层归一化
Encoder-Decoder 整体结构,为端到端任务机器翻译而设计。

-- 编码器 (Encoder) :任务是“理解”输入的整个句子。
-- 解码器 (Decoder) :任务是“生成”目标句子。
从自注意力到多头注意力
想象一下我们阅读这个句子:“The agent learns because it is intelligent.”。当我们读到加粗的 "it" 时,为了理解它的指代,我们的大脑会不自觉地将更多的注意力放在前面的 "agent" 这个词上。自注意力 (Self-Attention)
机制就是对这种现象的数学建模。它允许模型在处理序列中的每一个词时,都能兼顾句子中的所有其他词,并为这些词分配不同的“注意力权重”。权重越高的词,代表其与当前词的关联性越强,其信息也应该在当前词的表示中占据更大的比重。
引入了三个可学习的角色:
查询 (Query, Q):代表当前词元,它正在主动地“查询”其他词元以获取信息。
键 (Key, K):代表句子中可被查询的词元“标签”或“索引”。
值 (Value, V):代表词元本身所携带的“内容”或“信息”。
如果只进行一次上述的注意力计算(即单头),模型可能会只学会关注一种类型的关联。比如,在处理 "it" 时,可能只学会了关注主语。但语言中的关系是复杂的,我们希望模型能同时关注多种关系(如指代关系、时态关系、从属关系等)。多头注意力机制应运而生。它的思想很简单:把一次做完变成分成几组,分开做,再合并。
它将原始的 Q, K, V 向量在维度上切分成 h 份(h 就是“头”数),每一份都独立地进行一次单头注意力的计算。这就好比让 h 个不同的“专家”从不同的角度去审视句子,每个专家都能捕捉到一种不同的特征关系。最后,将这 h 个专家的“意见”(即输出向量)拼接起来,再通过一个线性变换进行整合,就得到了最终的输出。

import torch
import torch.nn as nn
import math
# --- 占位符模块,将在后续小节中实现 --- (1)Encoder-Decoder 整体结构
# class PositionalEncoding(nn.Module):
# """
# 位置编码模块
# """
#
# def forward(self, x):
# pass
### (4)残差连接与层归一化 , 3.1.2.5 位置编码
class PositionalEncoding(nn.Module):
"""
为输入序列的词嵌入向量添加位置编码。
"""
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# 创建一个足够长的位置编码矩阵
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
# pe (positional encoding) 的大小为 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
# 偶数维度使用 sin, 奇数维度使用 cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 将 pe 注册为 buffer,这样它就不会被视为模型参数,但会随模型移动(例如 to(device))
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x.size(1) 是当前输入的序列长度
# 将位置编码加到输入向量上
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
# class MultiHeadAttention(nn.Module):
# """
# 多头注意力机制模块
# """
#
# def forward(self, query, key, value, mask):
# pass
### (2)从自注意力到多头注意力
class MultiHeadAttention(nn.Module):
"""
多头注意力机制模块
"""
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 定义 Q, K, V 和输出的线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# 1. 计算注意力得分 (QK^T)
## Q: [batch_size, num_heads, seq_len_q, d_k]
## K: [batch_size, num_heads, seq_len_k, d_k]
## attn_scores: [batch_size, num_heads, seq_len_q, seq_len_k]
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 2. 应用掩码 (如果提供)
if mask is not None:
## # 调整掩码维度以匹配注意力得分: [batch_size, 1, seq_len_q, seq_len_k]
## # 确保掩码广播到所有head
if mask.dim() == 3:
mask = mask.unsqueeze(1) # [batch_size, 1, seq_len, seq_len]
## # 只保留与注意力得分匹配的维度
mask = mask[:, :, :attn_scores.size(2), :attn_scores.size(3)]
# 将掩码中为 0 的位置设置为一个非常小的负数,这样 softmax 后会接近 0
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 3. 计算注意力权重 (Softmax)
attn_probs = torch.softmax(attn_scores, dim=-1)
# 4. 加权求和 (权重 * V)
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# 将输入 x 的形状从 (batch_size, seq_length, d_model)
# 变换为 (batch_size, num_heads, seq_length, d_k)
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# 将输入 x 的形状从 (batch_size, num_heads, seq_length, d_k)
# 变回 (batch_size, seq_length, d_model)
batch_size, num_heads, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# 1. 对 Q, K, V 进行线性变换
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 2. 计算缩放点积注意力
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# 3. 合并多头输出并进行最终的线性变换
output = self.W_o(self.combine_heads(attn_output))
return output
# class PositionWiseFeedForward(nn.Module):
# """
# 位置前馈网络模块
# """
#
# def forward(self, x):
# pass
### (3)前馈神经网络
class PositionWiseFeedForward(nn.Module):
"""
位置前馈网络模块
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionWiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
# x 形状: (batch_size, seq_len, d_model)
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
# 最终输出形状: (batch_size, seq_len, d_model)
return x
# --- 编码器核心层 ---
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
# self.self_attn = MultiHeadAttention() # 待实现
# self.feed_forward = PositionWiseFeedForward() # 待实现
self.self_attn = MultiHeadAttention(d_model, num_heads) # 补全参数
self.feed_forward = PositionWiseFeedForward(d_model, d_ff, dropout) # 补全参数
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 残差连接与层归一化将在 3.1.2.4 节中详细解释
# 1. 多头自注意力
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
# --- 解码器核心层 ---
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads) # 补全参数
self.cross_attn = MultiHeadAttention(d_model, num_heads) # 补全参数
self.feed_forward = PositionWiseFeedForward(d_model, d_ff, dropout) # 补全参数
# self.self_attn = MultiHeadAttention() # 待实现
# self.cross_attn = MultiHeadAttention() # 待实现
# self.feed_forward = PositionWiseFeedForward() # 待实现
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
# def forward(self, x, encoder_output, src_mask, tgt_mask):
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
# 1. 掩码多头自注意力 (对自己)
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 交叉注意力 (对编码器输出)
cross_attn_output = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.norm2(x + self.dropout(cross_attn_output))
# 3. 前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
##### add main
def create_mask(seq_len, batch_size, device, mask_type="pad"):
"""
创建掩码矩阵
Args:
seq_len: 序列长度
batch_size: 批次大小
device: 设备
mask_type: "pad" (填充掩码) 或 "lookahead" (前瞻掩码)
Returns:
mask: [batch_size, seq_len, seq_len]
"""
if mask_type == "pad":
# 填充掩码 (全部为1,表示所有位置都可见)
mask = torch.ones(batch_size, seq_len, seq_len, device=device)
elif mask_type == "lookahead":
# 前瞻掩码 (下三角矩阵,防止看到未来的token)
mask = torch.tril(torch.ones(batch_size, seq_len, seq_len, device=device))
return mask
def main():
# 设置测试参数
batch_size = 2 # 批次大小
seq_len_src = 5 # 源序列长度
seq_len_tgt = 4 # 目标序列长度
d_model = 512 # 模型维度
num_heads = 8 # 注意力头数
d_ff = 2048 # 前馈网络隐藏层维度
dropout = 0.1 # dropout 概率
# 设置设备(GPU优先)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# ==================== 测试 1: 位置编码 ====================
print("\n" + "=" * 50)
print("测试 1: 位置编码 (PositionalEncoding)")
print("=" * 50)
# 创建位置编码实例
pos_encoder = PositionalEncoding(d_model, dropout).to(device)
# 创建测试输入 (batch_size, seq_len, d_model)
x = torch.randn(batch_size, seq_len_src, d_model).to(device)
# 前向传播
x_pos = pos_encoder(x)
print(f"输入形状: {x.shape}")
print(f"输出形状: {x_pos.shape}")
print(f"位置编码矩阵形状: {pos_encoder.pe.shape}")
# ==================== 测试 2: 多头注意力 ====================
print("\n" + "=" * 50)
print("测试 2: 多头注意力 (MultiHeadAttention)")
print("=" * 50)
# 创建多头注意力实例
multi_head_attn = MultiHeadAttention(d_model, num_heads).to(device)
# 创建测试输入
Q = torch.randn(batch_size, seq_len_src, d_model).to(device)
K = torch.randn(batch_size, seq_len_src, d_model).to(device)
V = torch.randn(batch_size, seq_len_src, d_model).to(device)
# 创建掩码 [batch_size, seq_len, seq_len]
mask = create_mask(seq_len_src, batch_size, device, "pad")
# 前向传播
attn_output = multi_head_attn(Q, K, V, mask)
print(f"Q/K/V 形状: {Q.shape}")
print(f"掩码形状: {mask.shape}")
print(f"注意力输出形状: {attn_output.shape}")
# ==================== 测试 3: 位置前馈网络 ====================
print("\n" + "=" * 50)
print("测试 3: 位置前馈网络 (PositionWiseFeedForward)")
print("=" * 50)
# 创建前馈网络实例
ff_network = PositionWiseFeedForward(d_model, d_ff, dropout).to(device)
# 创建测试输入
x = torch.randn(batch_size, seq_len_src, d_model).to(device)
# 前向传播
ff_output = ff_network(x)
print(f"输入形状: {x.shape}")
print(f"输出形状: {ff_output.shape}")
# ==================== 测试 4: 编码器层 ====================
print("\n" + "=" * 50)
print("测试 4: 编码器层 (EncoderLayer)")
print("=" * 50)
# 创建编码器层实例
encoder_layer = EncoderLayer(d_model, num_heads, d_ff, dropout).to(device)
# 创建测试输入和掩码
src_input = torch.randn(batch_size, seq_len_src, d_model).to(device)
src_mask = create_mask(seq_len_src, batch_size, device, "pad")
# 前向传播
encoder_output = encoder_layer(src_input, src_mask)
print(f"编码器输入形状: {src_input.shape}")
print(f"编码器掩码形状: {src_mask.shape}")
print(f"编码器输出形状: {encoder_output.shape}")
# ==================== 测试 5: 解码器层 ====================
print("\n" + "=" * 50)
print("测试 5: 解码器层 (DecoderLayer)")
print("=" * 50)
# 创建解码器层实例
decoder_layer = DecoderLayer(d_model, num_heads, d_ff, dropout).to(device)
# 创建测试输入
tgt_input = torch.randn(batch_size, seq_len_tgt, d_model).to(device)
# 创建掩码
src_mask = create_mask(seq_len_src, batch_size, device, "pad") # 源序列掩码 [2,5,5]
tgt_mask = create_mask(seq_len_tgt, batch_size, device, "lookahead") # 目标序列掩码 [2,4,4]
# 前向传播
decoder_output = decoder_layer(tgt_input, encoder_output, src_mask, tgt_mask)
print(f"解码器输入形状: {tgt_input.shape}")
print(f"编码器输出形状: {encoder_output.shape}")
print(f"源序列掩码形状: {src_mask.shape}")
print(f"目标序列掩码形状: {tgt_mask.shape}")
print(f"解码器输出形状: {decoder_output.shape}")
# ==================== 综合测试 ====================
print("\n" + "=" * 50)
print("测试 6: 综合测试 (完整流程)")
print("=" * 50)
# 1. 创建所有组件
pos_encoder = PositionalEncoding(d_model, dropout).to(device)
encoder_layer = EncoderLayer(d_model, num_heads, d_ff, dropout).to(device)
decoder_layer = DecoderLayer(d_model, num_heads, d_ff, dropout).to(device)
# 2. 源序列处理
src_emb = torch.randn(batch_size, seq_len_src, d_model).to(device) # 源序列词嵌入
src_emb_pos = pos_encoder(src_emb) # 添加位置编码
src_mask = create_mask(seq_len_src, batch_size, device, "pad")
encoder_out = encoder_layer(src_emb_pos, src_mask)
# 3. 目标序列处理
tgt_emb = torch.randn(batch_size, seq_len_tgt, d_model).to(device) # 目标序列词嵌入
tgt_emb_pos = pos_encoder(tgt_emb) # 添加位置编码
tgt_mask = create_mask(seq_len_tgt, batch_size, device, "lookahead")
decoder_out = decoder_layer(tgt_emb_pos, encoder_out, src_mask, tgt_mask)
print(f"源序列词嵌入形状: {src_emb.shape}")
print(f"添加位置编码后形状: {src_emb_pos.shape}")
print(f"编码器输出形状: {encoder_out.shape}")
print(f"解码器输出形状: {decoder_out.shape}")
print("\n✅ 所有测试通过!")
if __name__ == "__main__":
main()

import re, collections
def get_stats(vocab):
"""统计词元对频率"""
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols) - 1):
pairs[symbols[i], symbols[i + 1]] += freq
return pairs
def merge_vocab(pair, v_in):
"""合并词元对"""
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
# 准备语料库,每个词末尾加上</w>表示结束,并切分好字符
vocab = {'h u g </w>': 1, 'p u g </w>': 1, 'p u n </w>': 1, 'b u n </w>': 1}
num_merges = 4 # 设置合并次数
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(f"第{i + 1}次合并: {best} -> {''.join(best)}")
print(f"新词表(部分): {list(vocab.keys())}")
print("-" * 20)
# >>>
# 第1次合并: ('u', 'g') -> ug
# 新词表(部分): ['h ug </w>', 'p ug </w>', 'p u n </w>', 'b u n </w>']
# --------------------
# 第2次合并: ('ug', '</w>') -> ug</w>
# 新词表(部分): ['h ug</w>', 'p ug</w>', 'p u n </w>', 'b u n </w>']
# --------------------
# 第3次合并: ('u', 'n') -> un
# 新词表(部分): ['h ug</w>', 'p ug</w>', 'p un </w>', 'b un </w>']
# --------------------
# 第4次合并: ('un', '</w>') -> un</w>
# 新词表(部分): ['h ug</w>', 'p ug</w>', 'p un</w>', 'b un</w>']
从 N-gram 到 RNN -> Transformer 架构 -> Decoder-Only 架构 ->
- Transformer的设计哲学是“先理解,再生成”。
- Decoder-Only :完全抛弃了编码器,只保留了解码器部分。【 工作模式被称为自回归 (Autoregressive) 】
- 掩码自注意力 (Masked Self-Attention) : 保证在预测第 t 个词时,不去“偷看”第 t+1 个词的答案。

提示 (Prompt) 与 模型 沟通的语言:Temperature这类的可配置参数,其本质是通过调整模型对 “概率分布” 的采样策略,让输出匹配具体场景需求,配置合适的参数可以提升Agent在特定场景的性能。

ps: 想起当初 Microsoft Copilot 允许用户切换“创意”(Creative)、“平衡”(Balanced)和“精确”(Precise)三种模式,呈现不同的聊天内容,想必应该就是这个T。
零样本、单样本与少样本提示:给模型提供示例(Exemplar)的数量,提示可以分为三种类型。
- 零样本提示 (Zero-shot Prompting) :不给模型任何示例,直接让它根据指令完成任务。
- 单样本提示 (One-shot Prompting) :给模型提供一个完整的示例,向它展示任务的格式和期望的输出风格。
- 少样本提示 (Few-shot Prompting) :提供多个示例,让模型更准确地理解任务的细节、边界和细微差别,获得更好的性能。
指令调优 (Instruction Tuning) 是一种微调技术,它使用大量“指令-回答”格式的数据对预训练模型进行进一步的训练。经过指令调优后,模型能更好地理解并遵循用户的指令。
- 对“文本补全”模型的提示(你需要用少样本提示“教会”模型做什么)。
- 对“指令调优”模型的提示(你可以直接下达指令)。
- 角色扮演 (Role-playing) 通过赋予模型一个特定的角色,我们可以引导它的回答风格、语气和知识范围,使其输出更符合特定场景的需求。
- 上下文示例 (In-context Example) 这与少样本提示的思想一致,通过在提示中提供清晰的输入输出示例,来“教会”模型如何处理我们的请求,尤其是在处理复杂格式或特定风格的任务时非常有效。
- 对于需要逻辑推理、计算或多步骤思考的复杂问题,直接让模型给出答案往往容易出错。思维链 (Chain-of-Thought, CoT) 是一种强大的提示技巧,它通过引导模型“一步一步地思考”,提升了模型在复杂任务上的推理能力。
-- 实现 CoT 的关键,是在提示中加入一句简单的引导语,如“请逐步思考”或“Let's think step by step”。(通过显式地展示其推理过程,模型不仅更容易得出正确的答案,也让它的回答变得更可信、更易于我们检查和纠正。)
将自然语言文本喂给大语言模型之前,必须先将其转换成模型能够处理的数字格式。
- 将文本序列转换为数字序列的过程,就叫做分词 (Tokenization) 。
- 分词器 (Tokenizer) 的作用是定义一套规则,将原始文本切分成一个个最小的单元,【词元 (Token)】 。
-- 按词分词 (Word-based) ;
-- 按字符分词 (Character-based) ;
为了兼顾词表大小和语义表达,现代大语言模型普遍采用子词分词 (Subword Tokenization) 算法。它的核心思想是:将常见的词(如 "agent")保留为完整的词元,同时将不常见的词(如 "Tokenization")拆分成多个有意义的子词片段(如 "Token" 和 "ization")。这样既控制了词表的大小,又能让模型通过组合子词来理解和生成新词。
字节对编码 (Byte-Pair Encoding, BPE) 是最主流的子词分词算法之一[6],GPT系列模型就采用了这种算法。
假设我们的迷你语料库是 {"hug": 1, "pug": 1, "pun": 1, "bun": 1},并且我们想构建一个大小为 10 的词表。

- WordPiece:Google BERT 模型采用的算法[7]。它与 BPE 非常相似,但合并词元的标准不是“最高频率”,而是“能最大化提升语料库的语言模型概率”。简单来说,它会优先合并那些能让整个语料库的“通顺度”提升最大的词元对。
- SentencePiece:Google 开源的一款分词工具[8],Llama 系列模型采用了此算法。它最大的特点是,将空格也视作一个普通字符(通常用下划线 _ 表示)。这使得分词和解码过程完全可逆,且不依赖于特定的语言(例如,它不需要知道中文不使用空格分词)。
意义
- 上下文窗口限制:模型的上下文窗口(如 8K, 128K)是以 Token 数量计算的,而不是字符数或单词数。同样一段话,在不同语言(如中英文)或不同分词器下,Token 数量可能相差巨大。精确管理输入长度、避免超出上下文限制是构建长时记忆智能体的基础。
ps: 想起了最新的 TOON 协议 和JSON的对比。
- API 成本:大多数模型 API 都是按 Token 数量计费的。了解你的文本会被如何分词,是预估和控制智能体运行成本的关键一步。
- 模型表现的异常:有时模型的奇怪表现根源在于分词。例如,模型可能很擅长计算 2 + 2,但对于 2+2(没有空格)就可能出错,因为后者可能被分词器视为一个独立的、不常见的词元。同样,一个词因为首字母大小写不同,也可能被切分成完全不同的 Token 序列,从而影响模型的理解。
- 在设计提示词和解析模型输出时,考虑到这些“陷阱”有助于提升智能体的鲁棒性。
pip install transformers torch
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 指定模型ID
model_id = "Qwen/Qwen1.5-0.5B-Chat"
# 设置设备,优先使用GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载模型,并将其移动到指定设备
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
print("模型和分词器加载完成!")
##############
# 准备对话输入
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好,请介绍你自己。"}
]
# 使用分词器的模板格式化输入
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 编码输入文本
model_inputs = tokenizer([text], return_tensors="pt").to(device)
print("编码后的输入文本:")
print(model_inputs)
# >>>
# {'input_ids': tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13,151645, 198, 151644, 872, 198, 108386, 37945, 100157, 107828,1773, 151645, 198, 151644, 77091, 198]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
# device='cuda:0')}
###################################
# 使用模型生成回答
# max_new_tokens 控制了模型最多能生成多少个新的Token
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 将生成的 Token ID 截取掉输入部分
# 这样我们只解码模型新生成的部分
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 解码生成的 Token ID
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("\n模型的回答:")
print(response)
# >>>
# 我叫通义千问,是由阿里云研发的预训练语言模型,可以回答问题、创作文字,还能表达观点、撰写代码。我主要的功能是在多个领域提
# 供帮助,包括但不限于:语言理解、文本生成、机器翻译、问答系统等。有什么我可以帮到你的吗?

这是否意味着 "意识" 被创造了出来?

这是不是 有点像 "碳基生命"被"逼疯"了的样子?
- 检索增强生成 (Retrieval-Augmented Generation, RAG) [14]: 这是目前缓解幻觉的有效方法之一。RAG 系统通过在生成之前从外部知识库(如文档数据库、网页)中检索相关信息,然后将检索到的信息作为上下文,引导模型生成基于事实的回答。
- 多步推理与验证: 引导模型进行多步推理,并在每一步进行自我检查或外部验证。
- 引入外部工具: 允许模型调用外部工具(如搜索引擎、计算器、代码解释器)来获取实时信息或进行精确计算。
-
模型演进与核心架构:本章追溯了从统计语言模型 (N-gram) 到神经网络模型 (RNN, LSTM),再到奠定现代 LLM 基础的 Transformer 架构。通过“自顶向下”的代码实现,本章拆解了 Transformer 的核心组件,并阐述了自注意力机制在并行计算和捕捉长距离依赖中的关键作用。
-
与模型的交互方式:本章介绍了与 LLM 交互的两个核心环节:提示工程 (Prompt Engineering) 和文本分词 (Tokenization)。前者用于指导模型的行为,后者是理解模型输入处理的基础。通过本地部署并运行开源模型的实践,将理论知识应用于实际操作。
-
模型生态与选型:本章系统地梳理了为智能体选择模型时需要权衡的关键因素,并概览了以 OpenAI GPT、Google Gemini 为代表的闭源模型和以 Llama、Mistral 为代表的开源模型的特点与定位。
-
法则与局限:本章探讨了驱动 LLM 能力提升的缩放法则,阐述了其背后的基本原理。同时,本章也分析了模型存在的如事实幻觉、知识过时等固有局限性,这对于构建可靠、鲁棒的智能体至关重要。

-
模型无法准确判断哪些是有效输入、哪些是填充的无效内容,可能导致生成结果异常(比如乱码、逻辑混乱、重复输出等),建议手动传入注意力掩码(attention_mask)来保证结果可靠。
- 关键背景:你的模型(Qwen1.5-0.5B-Chat)中,「填充标记(pad token,用来补全长度不一致的输入文本)」和「结束标记(eos token,用来标识文本结束)」是同一个东西。
- 为什么出问题:模型生成文本时,需要靠「注意力掩码(attention_mask)」区分 “有效输入内容”(比如你的问题 “你好,请介绍你自己”)和 “填充的无效内容”(比如为了统一输入长度补的空白标记)。现在因为两个标记一样,模型没法自动推断出注意力掩码,就会 “分不清” 有效内容和填充内容,进而可能出现奇怪的生成结果。
- 你的代码小特殊:从你打印的 model_inputs 能看到,其实分词器已经自动生成了 attention_mask(全是 1,说明你的输入没有填充内容,全是有效内容),所以你当前的生成结果是正常的,但这个警告是提醒你 “如果后续有填充输入,不手动传掩码就会出问题”。
方案 1:最简单!生成时直接传入已有的 attention_mask
###################################
# 使用模型生成回答
# max_new_tokens 控制了模型最多能生成多少个新的Token
# generated_ids = model.generate(
# model_inputs.input_ids,
# max_new_tokens=512
# )
# 使用模型生成回答(新增 attention_mask 参数),修复 The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
generated_ids = model.generate(
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask, # 关键:传入注意力掩码
max_new_tokens=512
)
方案 2:指定分词器的 pad_token,让 pad token 和 eos token 不一样 【无效】
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 新增:指定 pad token,解决“pad和eos相同”的问题
tokenizer.pad_token = tokenizer.eos_token # 关键代码,Qwen 模型优先推荐这种写法
方案 3:最规范!同时指定 pad token + 传入 attention_mask
结合方案 1 和方案 2,既解决根源问题,又保证生成时的严谨性,适合后续批量处理、有填充输入的场景(比如一次传入多个长度不一致的问题)。
# 1. 加载分词器并指定 pad token
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token # 解决 pad 和 eos 相同的问题
# 2. 生成时传入 attention_mask
generated_ids = model.generate(
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask, # 传入掩码
max_new_tokens=512
)
习题
- 马尔可夫假设的含义
马尔可夫假设是 N-gram 模型的核心理论基础,其核心思想是:一个单词的出现概率仅依赖于其前面有限个(N-1 个)最近的单词,而与更早的单词无关。 - N-gram 模型的根本性局限
数据稀疏问题:随着 N 的增大,N-gram 组合的数量呈指数级增长,语料库中大量合理的 N-gram 组合从未出现,导致概率为 0,即使添加平滑处理也无法从根本上解决。 - 上下文窗口有限:马尔可夫假设忽略了长距离依赖关系,无法捕捉句子中相隔较远单词之间的语义关联,而这种关联在自然语言中普遍存在(如指代关系、逻辑关系等)。
- 参数空间爆炸:N-gram 模型需要存储所有可能的 N-gram 组合的概率,当 N 增大或词汇量增加时,参数数量会急剧膨胀,导致模型存储和计算成本过高。
- 缺乏语义理解:N-gram 仅基于单词的共现频率计算概率,不理解单词的语义含义,无法处理同义词、多义词等语义层面的语言现象。
- RNN/LSTM 的改进与优势
(1)如何克服 N-gram 局限
解决长距离依赖(部分):RNN 通过循环结构将前一时刻的隐藏状态传递到当前时刻,理论上可以捕捉任意长度的上下文依赖;LSTM 通过门控机制(输入门、遗忘门、输出门)进一步解决了 RNN 的梯度消失问题,能够有效捕捉较长距离的语义关联。
参数共享:RNN/LSTM 在每个时间步共享相同的参数,避免了 N-gram 参数空间爆炸的问题,模型参数数量不再随词汇量和上下文长度呈指数增长。
语义表征:模型通过训练学习到单词的分布式语义表征(词向量),能够捕捉单词的语义信息,更好地处理同义词、多义词等语义现象。
(2)优势
序列建模能力:天然适合处理序列数据,能够捕捉序列中的时序依赖关系,在语音识别、机器翻译等时序任务中表现出色。
参数效率高:参数共享机制使得模型在处理长序列时,计算成本不会显著增加,训练和推理效率优于高阶 N-gram 模型。 - Transformer 的改进与优势
(1)如何克服 N-gram 局限
- 全局上下文依赖:通过自注意力机制,Transformer 能够直接计算序列中任意两个单词之间的关联,不受距离限制,完美解决了 N-gram 和 RNN/LSTM 的上下文窗口有限问题。
- 并行计算:摒弃了 RNN 的循环结构,采用全连接和注意力机制,使得模型可以并行处理整个序列,大幅提升了训练和推理效率。
- 更强的语义表征:通过多层 Transformer 堆叠和自注意力机制,模型能够学习到更复杂、更抽象的语义表征,捕捉语言中的深层语义结构。
(2)优势 - 并行效率极高:相比 RNN 的串行处理,Transformer 的并行计算能力使其能够利用现代 GPU 的算力优势,处理更长的序列和更大规模的语料。
- 长距离依赖建模能力:自注意力机制可以直接建立任意位置单词的关联,无需像 LSTM 那样逐步传递信息,在长文本处理任务中表现远超传统模型。
- 模型扩展性强:通过堆叠更多的 Transformer 层和扩大模型参数规模,可以持续提升模型的性能,这也是大语言模型能够取得突破性进展的核心原因。
二 、Transformer 架构核心问题解析
- 自注意力机制(Self-Attention)的核心思想
- 自注意力机制的核心思想是:在处理序列中的每个位置时,通过计算该位置与序列中所有其他位置的关联权重,动态聚合整个序列的信息,生成该位置的上下文表征。
- 其本质是为每个单词生成一个 "注意力权重向量",表示该单词与其他单词的关联程度,然后通过加权求和的方式,将其他单词的信息融合到当前单词的表征中。这种机制使得模型能够根据当前语境,灵活地关注序列中最相关的信息,不受单词位置距离的限制。
- Transformer 并行处理与位置编码的作用
(1)并行处理的原因
- RNN 的串行本质:RNN 的计算依赖于前一时刻的隐藏状态,必须按顺序逐个处理序列中的单词,前一个单词处理完成后才能开始处理下一个,无法并行。
- Transformer 的并行设计:Transformer 采用的是全连接层和自注意力机制,每个位置的计算仅依赖于输入序列的全局信息,不同位置之间的计算相互独立,因此可以同时处理序列中的所有位置,实现并行计算。
(2)位置编码的作用 - Transformer 的自注意力机制本身不包含序列顺序信息,所有位置的计算是并行且对称的,无法区分单词在序列中的位置。位置编码的作用就是为每个位置的单词添加一个独特的位置信息,让模型能够感知到单词在序列中的顺序和相对位置。
- 位置编码通常通过三角函数或可学习的向量实现,将位置信息与单词的词向量相加,使得模型在计算注意力时能够考虑到单词的位置差异,从而正确建模语言中的时序关系。
- Decoder-Only 与 Encoder-Decoder 架构的区别及主流选择原因
(1)架构区别
| 维度 | Decoder-Only 架构 | Encoder-Decoder 架构 |
|---|---|---|
| 结构组成 | 仅由多层 Decoder 堆叠而成 | 由 Encoder 和 Decoder 两部分组成 |
| 输入处理 | 输入序列直接输入 Decoder | 输入序列先经过 Encoder 编码为上下文向量,再输入 Decoder |
| 核心机制 | 采用自回归的方式生成输出,通过 Masked 自注意力防止看到未来信息 | Encoder 使用自注意力,Decoder 使用 Masked 自注意力和 Encoder-Decoder 注意力,关注 Encoder 的输出 |
| 适用任务 | 文本生成、对话生成、代码生成等 | 机器翻译、文本摘要、信息抽取等 |
(2)主流选择 Decoder-Only 的原因
训练和推理效率更高:Decoder-Only 架构无需维护 Encoder 和 Decoder 两部分参数,模型结构更简洁,训练时的计算成本更低,推理时的速度更快。
生成能力更强:自回归生成方式更符合自然语言的生成逻辑,能够生成连贯、流畅的长文本,在对话、创作等生成式任务中表现更出色。
多任务泛化能力:Decoder-Only 模型通过提示词工程,可以适配多种任务(如分类、摘要、推理等),无需针对不同任务修改模型结构,灵活性更高。
工程实现更简单:Decoder-Only 架构的训练和推理流程更统一,更容易进行分布式训练和优化,降低了工程实现的复杂度。
五、文本子词分词算法核心问题
- 不能直接以字符或单词作为输入单元的原因
(1)字符作为输入单元的问题
语义粒度太细:字符本身不具备完整的语义,需要模型学习大量的组合规则才能形成有意义的单词和句子,增加了模型的学习难度和训练成本。
序列长度过长:以字符为单位会导致输入序列长度大幅增加,不仅增加了计算量,还会加剧长文本处理时的上下文窗口限制问题。
(2)单词作为输入单元的问题
词汇量爆炸:语言中的单词数量庞大,且不断有新词出现(如网络热词、专业术语),模型无法覆盖所有单词,导致未登录词(OOV)问题严重。
语义冗余:很多单词存在词形变化(如英语的时态、单复数)或语义关联(如 "run" 和 "running"),以单词为单位会忽略这些关联,增加模型的参数数量和学习负担。 - BPE(Byte Pair Encoding)算法解决的问题
BPE 算法是一种基于统计的子词分词算法,核心是通过迭代合并出现频率最高的字符或子词对,生成新的子词单元,直到达到预设的词汇量。
它主要解决了以下问题:
未登录词问题:BPE 可以将未见过的单词拆分为已学习的子词单元,从而处理词典外的新词,大幅降低 OOV 比例。
语义关联建模:BPE 能够捕捉单词的词形变化和语义关联(如将 "running" 拆分为 "run" 和 "ing"),让模型能够共享这些子词的语义信息,提升模型的泛化能力和参数效率。
平衡语义粒度:子词单元介于字符和单词之间,既保留了单词的部分语义信息,又具备一定的灵活性,能够在语义表达和计算效率之间取得平衡。
pip install hf_xet
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-0.6B")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-0.6B")
# 生成文本
prompt = "自然语言处理的核心任务包括"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
top_p=0.9,
do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))

采样参数对输出的影响
Temperature(温度):控制输出的随机性。温度越高(如 1.5),输出越多样化、富有创意,但可能出现逻辑混乱;温度越低(如 0.1),输出越保守、确定,更倾向于选择概率最高的词,但可能缺乏多样性。


Top-p(核采样):选择概率累计和达到 p 的最可能的词集合,仅从该集合中采样。Top-p 越小(如 0.5),输出越集中、确定;Top-p 越大(如 0.95),输出越多样化。


Do_sample:是否启用采样策略。若为 False,则采用贪心搜索,每次选择概率最高的词,输出确定性强但缺乏多样性。

The following generation flags are not valid and may be ignored: ['temperature', 'top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
你设置的 temperature、top_p 这两个采样相关参数无效,模型会忽略它们
- 在 model.generate() 中设置了 do_sample=False(这是默认值,即使不显示指定也会生效),此时模型采用的是「贪心搜索(Greedy Search)」策略 —— 每次生成时只选择概率最高的下一个 token,不存在随机采样的过程。
- temperature(控制采样随机性)、top_p(核采样,限定采样候选集)是仅在随机采样模式下生效的参数,贪心搜索不需要这些参数来控制随机性,因此 Transformers 库会提示这些参数无效并忽略。
- 提示中还提到了 top_k(虽未在你的代码中设置),它同样是采样模式的专属参数,与 temperature、top_p 作用类似,仅在 do_sample=True 时有效。
- 贪心搜索(do_sample=False):输出确定性强,每次输入相同的 prompt 会得到几乎一致的结果,但可能缺乏多样性,甚至出现重复文本。
- 随机采样(do_sample=True):结合 temperature 和 top_p 可平衡多样性与合理性:
-- temperature 越大(如 1.0),随机性越强;越小(如 0.3),输出越保守、确定。
-- top_p 越小(如 0.7),采样候选集越窄,输出越稳定;越大(如 0.95),候选集越宽,多样性越高。

- 不同提示策略效果对比(以文本分类任务为例)
任务:将句子 "手机续航能力强,拍照效果好,值得购买" 分类为 "正面评价" 或 "负面评价"。
Zero-shot:直接给出分类指令,无需示例。
提示词:"判断以下句子的情感倾向,分为正面评价或负面评价:手机续航能力强,拍照效果好,值得购买"
效果:模型能够理解任务,但在复杂语境下准确率可能较低。


Few-shot:提供少量示例,帮助模型理解任务。
提示词:" 判断以下句子的情感倾向,分为正面评价或负面评价:
这款电脑性能差,经常卡顿,不推荐购买 - 负面评价
耳机音质清晰,佩戴舒适,性价比很高 - 正面评价
手机续航能力强,拍照效果好,值得购买 - "
效果:通过示例引导,模型准确率显著提升,适用于训练数据较少的场景。


Chain-of-Thought(CoT):引导模型逐步推理,给出分类理由。
提示词:"判断以下句子的情感倾向,分为正面评价或负面评价,并说明理由:手机续航能力强,拍照效果好,值得购买"
效果:模型能够给出更合理的分类结果,且输出具有可解释性,适用于需要逻辑推理的复杂任务。

模型幻觉缓解方法解析
- 检索增强生成(RAG)的工作原理与适用场景
(1)工作原理
RAG 的核心思想是:在模型生成文本之前,先从外部知识库中检索与当前问题相关的信息,将检索结果作为上下文输入给模型,引导模型基于真实信息生成输出,从而减少幻觉。
其流程通常包括:
问题解析:对用户的问题进行语义理解和关键词提取。
信息检索:通过向量数据库等工具,从知识库中检索与问题相关的文档或片段。
上下文构建:将检索到的信息与用户问题拼接,形成新的提示词。
文本生成:模型基于构建好的上下文生成回答,确保输出内容与检索结果一致。
(2)适用场景
知识密集型任务:如医疗咨询、法律问答、技术支持等,需要基于准确的专业知识生成回答。
时效性强的任务:如新闻问答、行业动态咨询等,需要结合最新的外部信息,弥补模型训练数据的滞后性。
事实性要求高的任务:如学术问答、产品介绍等,要求输出内容必须真实可靠,不容许虚构信息。 - 前沿幻觉缓解方法调研
除了 RAG、多步推理和外部工具调用,当前前沿研究还提出了以下方法:
模型对齐(Model Alignment):通过 RLHF(基于人类反馈的强化学习)、DPO(直接偏好优化)等方法,让模型的输出更符合人类的事实性和真实性偏好,从模型内部减少幻觉的产生。优势是无需依赖外部知识库,可提升模型在各类任务中的事实准确性。
事实性验证模块:在模型生成输出后,添加一个独立的验证模块,检查输出内容是否与外部知识库或事实一致,对存在幻觉的内容进行修正或标记。优势是能够对生成结果进行事后校验,提升输出的可靠性,适用于对准确性要求极高的场景。
结构化输出约束:通过提示词或模型微调,引导模型生成结构化的输出(如表格、列表),并要求输出内容必须有明确的来源依据。优势是输出格式规范,便于人工审核和自动化验证,减少模型自由发挥导致的幻觉。
多模型协同:将多个不同的模型结合使用,让一个模型生成回答,另一个模型进行事实性校验,或者让多个模型共同投票决定最终结果。优势是能够利用不同模型的互补性,降低单一模型产生幻觉的概率,提升输出的鲁棒性。
八、论文辅助阅读智能体设计 - 基座模型选择及考虑因素
推荐选择:Llama 3-70B 或 Qwen 3-72B(开源大模型)
选择时需要考虑的核心因素:
上下文窗口:学术论文通常篇幅较长(数千至数万单词),需要模型支持足够长的上下文窗口(至少 32k tokens),才能完整处理单篇论文。
语义理解能力:学术论文包含复杂的逻辑结构、专业术语和数学公式,需要模型具备强大的语义理解和逻辑推理能力,能够准确提取核心信息和分析论文观点。
可扩展性:支持微调、模型蒸馏等优化手段,能够针对学术论文阅读场景进行定制化训练,提升模型在特定领域的表现。
开源性:支持本地部署和二次开发,便于集成检索模块、文档解析模块等功能,构建完整的智能体系统。
多语言支持:能够处理中英文等多语言论文,满足不同研究人员的需求。 - 提示词设计与长文本处理
(1)提示词设计策略
结构化提示:采用 "任务指令 + 输出格式要求 + 示例" 的结构化提示词,引导模型按照固定格式输出结果。例如:"请总结以下论文的核心内容,包括研究背景、研究方法、实验结果和结论,输出格式为:1. 研究背景:... 2. 研究方法:... 3. 实验结果:... 4. 结论:..."
分任务提示:将复杂任务拆解为多个子任务,逐步引导模型完成。例如,先让模型提取论文的研究问题,再提取研究方法,最后整合为完整总结。
专业术语引导:在提示词中明确提及论文所属领域的专业术语,帮助模型快速定位核心信息,提升理解准确率。
(2)长文本处理方案
文本分段与摘要:将长论文按照章节或段落拆分为多个片段,先对每个片段生成摘要,再将所有摘要整合为论文的完整总结,避免上下文窗口限制。
关键信息提取优先:先从论文中提取标题、摘要、关键词、图表说明等核心信息,再基于这些信息理解论文的整体框架,最后针对具体章节进行详细分析。
检索增强阅读:将论文内容构建为向量数据库,当用户提问时,先检索与问题相关的论文片段,再让模型基于这些片段生成回答,无需处理整篇论文。 - 确保输出准确客观的系统设计
引用溯源机制:要求模型在生成回答时,标注信息来源的论文章节、页码或段落,方便用户核对原文,确保信息的可追溯性。
事实性校验模块:集成外部学术数据库(如 Google Scholar、CNKI)或事实性验证模型,对模型生成的信息进行实时校验,标记可能存在的错误或幻觉内容。
人工审核接口:提供人工审核功能,对于重要的论文解读结果,允许研究人员进行修改和确认,确保输出内容符合学术严谨性要求。
领域专家微调:邀请相关领域的专家标注高质量的论文解读数据,对模型进行微调,提升模型在特定领域的准确性和专业性。
输出格式约束:强制模型采用结构化的输出格式(如列表、表格),避免模糊性表述,让输出内容更清晰、更易于验证。
task04 - task08
see: https://chuna2.787528.xyz/Chary/p/19410406/hello-agents_by_wx20190202gyb-prart2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号