摘要:
当前大语言模型(LLM)虽能力突飞猛进,却难逃“知识静态滞后”与“专业内容幻觉”两大痛点。在法律、医疗等强合规场景中,这几乎是“致命缺陷。而 RAG(检索增强生成)框架虽能通过融合外部知识库破解此困,却在落地时遭遇新瓶颈:有限硬件资源下,如何实现高效、低延迟推理? 在此背景下,以LightLLM 为 阅读全文
posted @ 2025-10-30 14:36
Lab4AI大模型实验室
阅读(144)
评论(0)
推荐(0)
 当前基于指令的图像编辑虽借助扩散模型取得进展,但仍面临挑战,本研究突破SFT范式的泛化性与可控性限制,解决扩散模型结合 RL 时的策略优化偏差问题。 阅读全文
当前基于指令的图像编辑虽借助扩散模型取得进展,但仍面临挑战,本研究突破SFT范式的泛化性与可控性限制,解决扩散模型结合 RL 时的策略优化偏差问题。 阅读全文
 【01 论文概述】 论文标题:ScalingInstruction-BasedVideoEditingwithaHigh-QualitySyntheticDataset 作者团队:香港科大、蚂蚁集团、浙江大学、东北大学 发布时间:2025 年 10 月 17 日 论文链接:https://arxiv 阅读全文
【01 论文概述】 论文标题:ScalingInstruction-BasedVideoEditingwithaHigh-QualitySyntheticDataset 作者团队:香港科大、蚂蚁集团、浙江大学、东北大学 发布时间:2025 年 10 月 17 日 论文链接:https://arxiv 阅读全文
 10月13日,AI领域大神AndrejKarpathy发布了自己的最新开源项目。截至当前,GitHub项目上已经达到29.1KStar。 阅读全文
10月13日,AI领域大神AndrejKarpathy发布了自己的最新开源项目。截至当前,GitHub项目上已经达到29.1KStar。 阅读全文
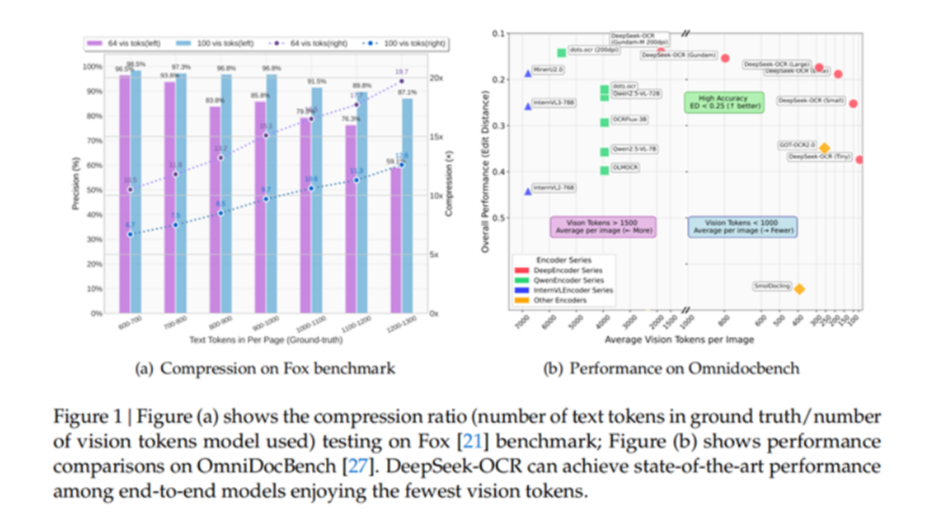 DeepSeek团队于10月20日开源的DeepSeek-OCR,以“上下文光学压缩”为核心突破,重新定义了OCR(光学字符识别)的效率边界。 阅读全文
DeepSeek团队于10月20日开源的DeepSeek-OCR,以“上下文光学压缩”为核心突破,重新定义了OCR(光学字符识别)的效率边界。 阅读全文
 通过给大模型喂我们的聊天记录,就可打造出我们的数字分身,当前爆火的Weclone项目采取的就是这种做法。 阅读全文
通过给大模型喂我们的聊天记录,就可打造出我们的数字分身,当前爆火的Weclone项目采取的就是这种做法。 阅读全文
 开发鲁棒且通用的操作策略是机器人领域的关键目标。为实现有效的泛化能力,构建包含大量演示轨迹和在复杂真实环境中完成多样化任务的综合数据集至关重要。 阅读全文
开发鲁棒且通用的操作策略是机器人领域的关键目标。为实现有效的泛化能力,构建包含大量演示轨迹和在复杂真实环境中完成多样化任务的综合数据集至关重要。 阅读全文
 1.论文概述 论文标题:SAM3: Segment Anything with Concepts 作者团队:Anonymous authors 发布时间:ICLR2026 论文链接:https://openreview.net/pdf?id=r35clVtGzw 👉Lab4AI 大模型实验室链接: 阅读全文
1.论文概述 论文标题:SAM3: Segment Anything with Concepts 作者团队:Anonymous authors 发布时间:ICLR2026 论文链接:https://openreview.net/pdf?id=r35clVtGzw 👉Lab4AI 大模型实验室链接: 阅读全文
 01 论文概述 论文名称: Direct Preference Optimization: Your Language Model is Secretly a Reward Model —— DPO:你的语言模型,其实就是个奖励模型 论文链接:https://arxiv.org/pdf/2305.1 阅读全文
01 论文概述 论文名称: Direct Preference Optimization: Your Language Model is Secretly a Reward Model —— DPO:你的语言模型,其实就是个奖励模型 论文链接:https://arxiv.org/pdf/2305.1 阅读全文
 TRM仅使用一个超小的2层网络(7M参数),通过更直接、完整的递归和深度监督机制,在多个基准测试上显著超越了HRM和许多主流LLMs。其最引人注目的成果是在ARC-AGI-1上达到45%的测试准确率,超过了参数量是其数百万倍的LLMs。 阅读全文
TRM仅使用一个超小的2层网络(7M参数),通过更直接、完整的递归和深度监督机制,在多个基准测试上显著超越了HRM和许多主流LLMs。其最引人注目的成果是在ARC-AGI-1上达到45%的测试准确率,超过了参数量是其数百万倍的LLMs。 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号