摘要:  PPO与DPO并非新旧替代关系,而是分属对齐不同阶段的工具:PPO用于行为“塑形”(强干预、纠偏乱序),DPO用于偏好“定型”(稳定微调、精细排序)。选型关键看模型是否已基本可控——乱则用PPO,稳则用DPO。 阅读全文
PPO与DPO并非新旧替代关系,而是分属对齐不同阶段的工具:PPO用于行为“塑形”(强干预、纠偏乱序),DPO用于偏好“定型”(稳定微调、精细排序)。选型关键看模型是否已基本可控——乱则用PPO,稳则用DPO。 阅读全文
PPO与DPO并非新旧替代关系,而是分属对齐不同阶段的工具:PPO用于行为“塑形”(强干预、纠偏乱序),DPO用于偏好“定型”(稳定微调、精细排序)。选型关键看模型是否已基本可控——乱则用PPO,稳则用DPO。 阅读全文
posted @ 2026-01-28 18:04
大模型玩家七七
阅读(18)
评论(0)
推荐(0)
摘要: 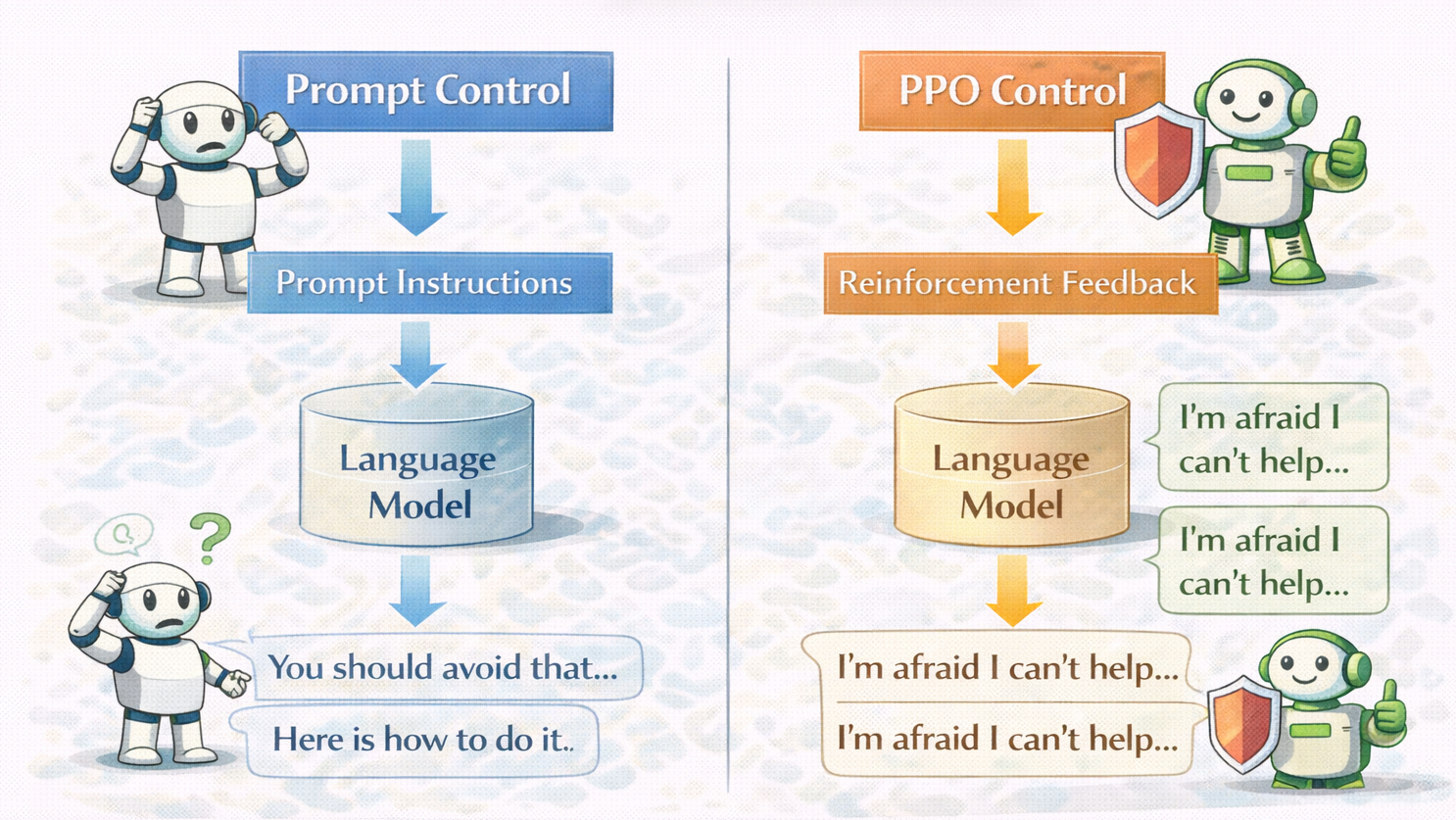 PPO并非“万能增强器”,而是精准解决模型“行为偏好错位”的工具:当模型“会但总选错”(如安全拒答生硬、风格不稳、高风险下过度自信)时,PPO通过人类偏好反馈重塑其选择倾向;若问题本质是“不会”,则PPO无效甚至有害。用对场景,事半功倍。 阅读全文
PPO并非“万能增强器”,而是精准解决模型“行为偏好错位”的工具:当模型“会但总选错”(如安全拒答生硬、风格不稳、高风险下过度自信)时,PPO通过人类偏好反馈重塑其选择倾向;若问题本质是“不会”,则PPO无效甚至有害。用对场景,事半功倍。 阅读全文
PPO并非“万能增强器”,而是精准解决模型“行为偏好错位”的工具:当模型“会但总选错”(如安全拒答生硬、风格不稳、高风险下过度自信)时,PPO通过人类偏好反馈重塑其选择倾向;若问题本质是“不会”,则PPO无效甚至有害。用对场景,事半功倍。 阅读全文
posted @ 2026-01-28 18:02
大模型玩家七七
阅读(34)
评论(0)
推荐(0)
摘要: 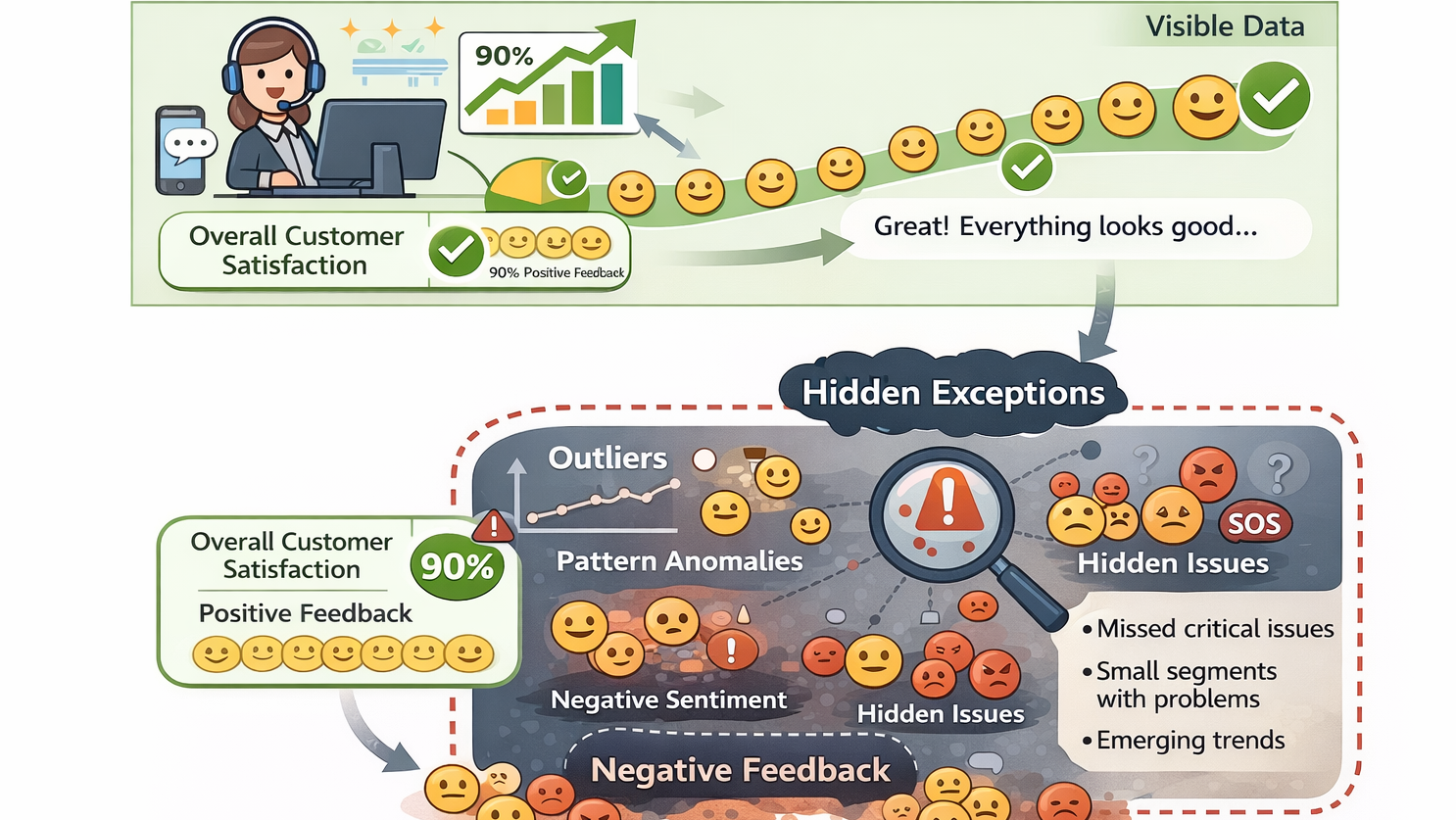 智能客服失败常因误将“问答机器人”当“服务处理器”。其核心不在答对,而在判断:是否该答、答到哪、何时转人工、如何安抚。微调非万能,仅适用于稳定风格、固化明确规则、强化安全拒答三类场景;知识更新、动态状态、争议判断等问题,应交由RAG或规则系统处理。 阅读全文
智能客服失败常因误将“问答机器人”当“服务处理器”。其核心不在答对,而在判断:是否该答、答到哪、何时转人工、如何安抚。微调非万能,仅适用于稳定风格、固化明确规则、强化安全拒答三类场景;知识更新、动态状态、争议判断等问题,应交由RAG或规则系统处理。 阅读全文
智能客服失败常因误将“问答机器人”当“服务处理器”。其核心不在答对,而在判断:是否该答、答到哪、何时转人工、如何安抚。微调非万能,仅适用于稳定风格、固化明确规则、强化安全拒答三类场景;知识更新、动态状态、争议判断等问题,应交由RAG或规则系统处理。 阅读全文
posted @ 2026-01-28 16:31
大模型玩家七七
阅读(37)
评论(0)
推荐(0)
摘要:  本文揭示向量数据库实战的七大关键陷阱:选型前需明确业务本质(模糊匹配 or 精确查询?);embedding 比数据库本身更重要,决定语义“世界观”;文档切分是核心工程,非辅助步骤;建库成功≠可用,TopK 准确率会随数据演进失效;“相似但不可用”是常态,必须引入 rerank;需建立可追溯的bad case排查路径;向量库是长期系统,非一次性组件。核心结论:难在“用对”,不在“用上”。 阅读全文
本文揭示向量数据库实战的七大关键陷阱:选型前需明确业务本质(模糊匹配 or 精确查询?);embedding 比数据库本身更重要,决定语义“世界观”;文档切分是核心工程,非辅助步骤;建库成功≠可用,TopK 准确率会随数据演进失效;“相似但不可用”是常态,必须引入 rerank;需建立可追溯的bad case排查路径;向量库是长期系统,非一次性组件。核心结论:难在“用对”,不在“用上”。 阅读全文
本文揭示向量数据库实战的七大关键陷阱:选型前需明确业务本质(模糊匹配 or 精确查询?);embedding 比数据库本身更重要,决定语义“世界观”;文档切分是核心工程,非辅助步骤;建库成功≠可用,TopK 准确率会随数据演进失效;“相似但不可用”是常态,必须引入 rerank;需建立可追溯的bad case排查路径;向量库是长期系统,非一次性组件。核心结论:难在“用对”,不在“用上”。 阅读全文
posted @ 2026-01-28 12:23
大模型玩家七七
阅读(38)
评论(0)
推荐(0)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号